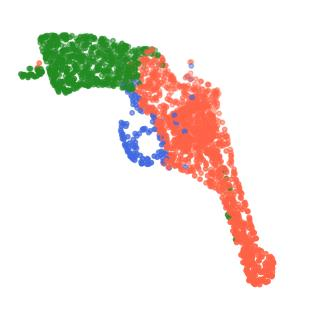
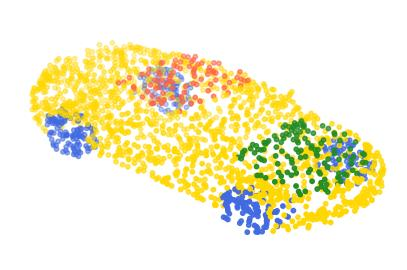
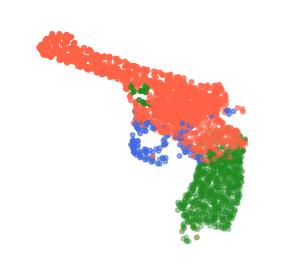
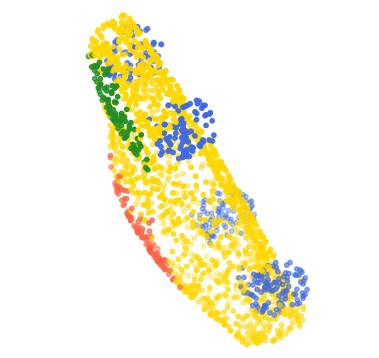
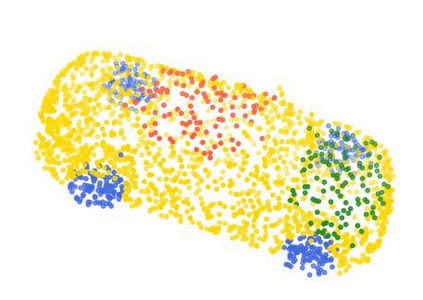
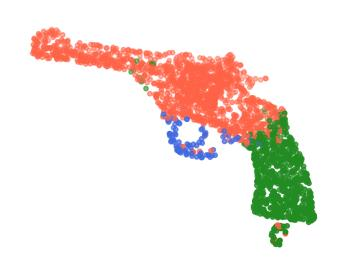
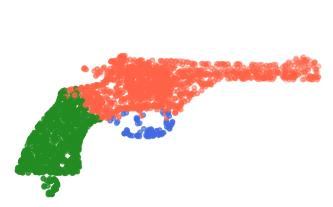
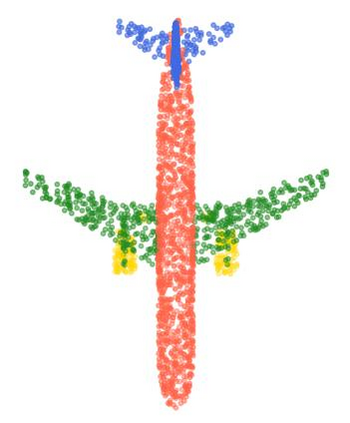
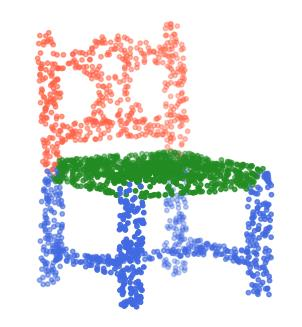
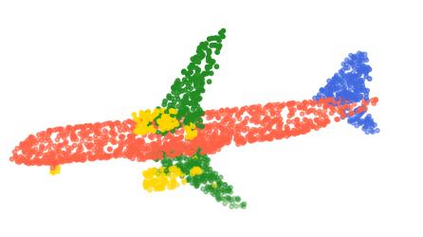
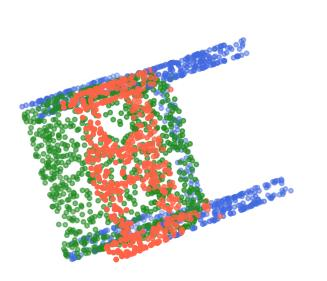
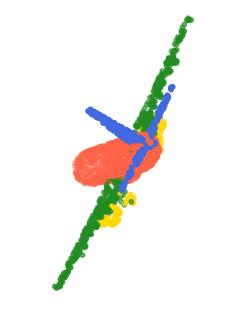
Rotation-invariant (RI) 3D deep learning methods suffer performance degradation as they typically design RI representations as input that lose critical global information comparing to 3D coordinates. Most state-of-the-arts address it by incurring additional blocks or complex global representations in a heavy and ineffective manner. In this paper, we reveal that the global information loss stems from an unexplored pose information loss problem, which can be solved more efficiently and effectively as we only need to restore more lightweight local pose in each layer, and the global information can be hierarchically aggregated in the deep networks without extra efforts. To address this problem, we develop a Pose-aware Rotation Invariant Convolution (i.e., PaRI-Conv), which dynamically adapts its kernels based on the relative poses. To implement it, we propose an Augmented Point Pair Feature (APPF) to fully encode the RI relative pose information, and a factorized dynamic kernel for pose-aware kernel generation, which can further reduce the computational cost and memory burden by decomposing the kernel into a shared basis matrix and a pose-aware diagonal matrix. Extensive experiments on shape classification and part segmentation tasks show that our PaRI-Conv surpasses the state-of-the-art RI methods while being more compact and efficient.
翻译:3D 深层学习方法(RI) 3D 深层学习方法会发生性能退化,因为它们通常设计RI 代表,作为与 3D 坐标相比失去关键全球信息的投入。大多数最先进的艺术都通过大量和低效的方式产生额外的区块或复杂的全球代表来解决这个问题。在本文中,我们发现全球信息损失源于一个未探索的信息丢失问题,这个问题可以更加高效和有效地加以解决,因为我们只需要恢复每个层中较轻的当地构成,而全球信息可以在深层网络中进行分级汇总,而无需做出额外努力。为了解决这一问题,我们开发了一个“浮度变异性变换(即PaRI-Convonv)”,根据相对构成动态调整其内核。为了实施这一问题,我们建议增加Pair Fair Faterature(APF) 点(APPF), 以充分编码RI 相对构成信息, 以及一个因因素化的动态内核生成的动态内核内核内核内核, 它可以进一步降低计算成本和记忆负担,通过将数据采集的内核分析方法进行分解,同时将我们的内层分析,同时将磁结构的内核分析,并显示一个共同的内层结构结构。