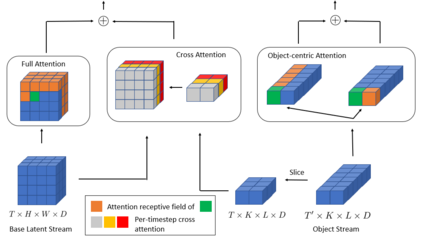
In this work, we present Patch-based Object-centric Video Transformer (POVT), a novel region-based video generation architecture that leverages object-centric information to efficiently model temporal dynamics in videos. We build upon prior work in video prediction via an autoregressive transformer over the discrete latent space of compressed videos, with an added modification to model object-centric information via bounding boxes. Due to better compressibility of object-centric representations, we can improve training efficiency by allowing the model to only access object information for longer horizon temporal information. When evaluated on various difficult object-centric datasets, our method achieves better or equal performance to other video generation models, while remaining computationally more efficient and scalable. In addition, we show that our method is able to perform object-centric controllability through bounding box manipulation, which may aid downstream tasks such as video editing, or visual planning. Samples are available at https://sites.google.com/view/povt-public}{https://sites.google.com/view/povt-public
翻译:在这项工作中,我们展示了一种新型的区域视频生成结构,它利用以物体为中心的信息,在视频中高效地模拟时间动态。我们以先前的工作为基础,通过压缩视频的离散潜在空间进行视频预测,通过压缩视频的自动递增变异变异器,通过捆绑框对以物体为中心的信息的模型进行额外修改。由于以物体为中心的表达方式更加可压缩,我们可以提高培训效率,允许该模型只访问更远的地平线时间信息对象信息。在对各种困难的以物体为中心的数据集进行评估时,我们的方法与其他视频生成模型的性能更好或平等,同时仍然以更具有计算效率和可扩展性。此外,我们展示了我们的方法能够通过捆绑框操作来进行以物体为中心的控制,这可能有助于诸如视频编辑或视觉规划等下游任务。样本可在https://sites.gogle.com/view/povt-public_https://sitesites.gogle.view/povt-publicpubs.