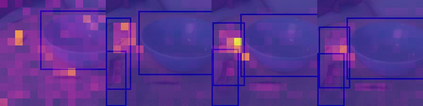
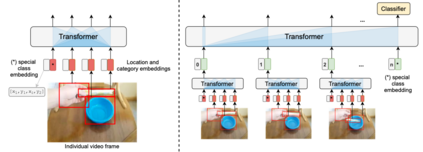
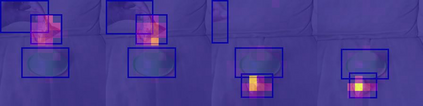
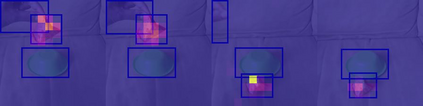
The objective of this work is to learn an object-centric video representation, with the aim of improving transferability to novel tasks, i.e., tasks different from the pre-training task of action classification. To this end, we introduce a new object-centric video recognition model based on a transformer architecture. The model learns a set of object-centric summary vectors for the video, and uses these vectors to fuse the visual and spatio-temporal trajectory `modalities' of the video clip. We also introduce a novel trajectory contrast loss to further enhance objectness in these summary vectors. With experiments on four datasets -- SomethingSomething-V2, SomethingElse, Action Genome and EpicKitchens -- we show that the object-centric model outperforms prior video representations (both object-agnostic and object-aware), when: (1) classifying actions on unseen objects and unseen environments; (2) low-shot learning to novel classes; (3) linear probe to other downstream tasks; as well as (4) for standard action classification.
翻译:这项工作的目的是学习一种以物体为中心的视频显示方式,目的是改进向新任务,即与训练前行动分类任务不同的任务的可转让性。为此目的,我们采用了基于变压器结构的新的以物体为中心的视频识别模式。模型为视频学习了一套以物体为中心的简易矢量,并利用这些矢量将视频剪辑的视觉和时空轨迹“模式”融合起来。我们还引入了一种新的轨迹对比损失,以进一步加强这些摘要矢量的可转让性。通过对四个数据集 -- -- Something-V2, Somethe Else, Action Georgee和EpicKitchens -- -- 的实验,我们表明,以物体为中心的模型比先前的视频显示方式(对象-敏感和对象-觉知度)要优于先前的视频显示方式(对象-敏感和对象-觉察度),当时:(1) 将看不见物体和看不见环境的行动分类;(2) 低镜头学习新类;(3) 线性探测到其他下游任务;以及(4) 标准行动分类。