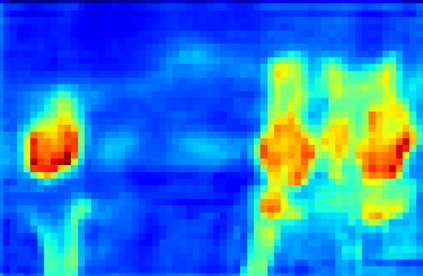
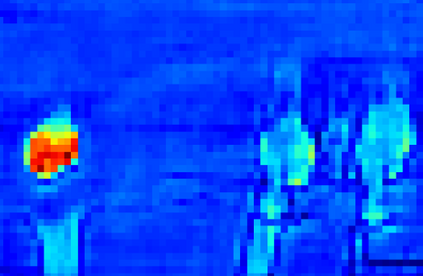
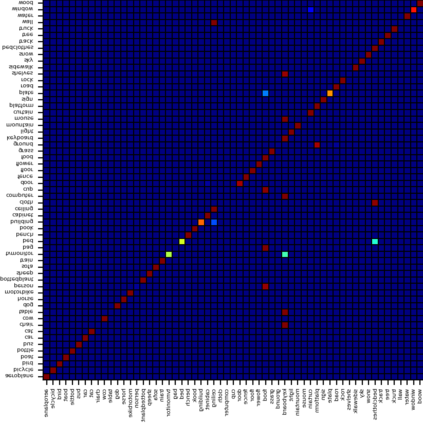
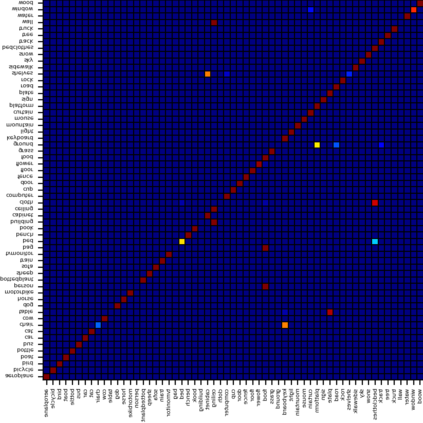
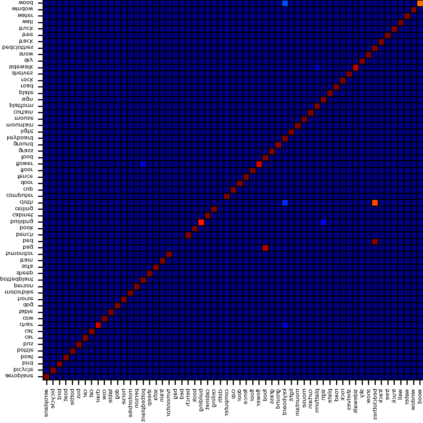
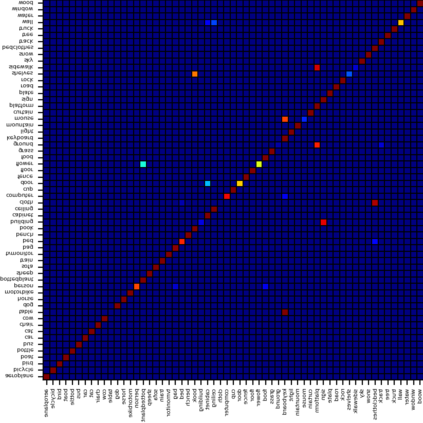
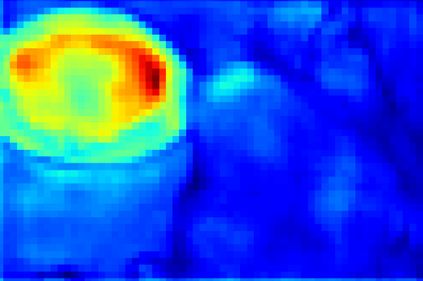
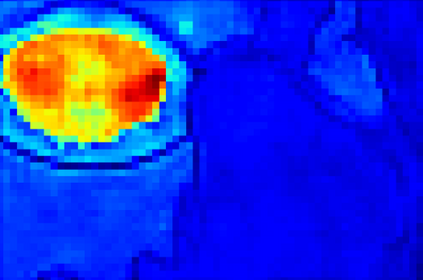
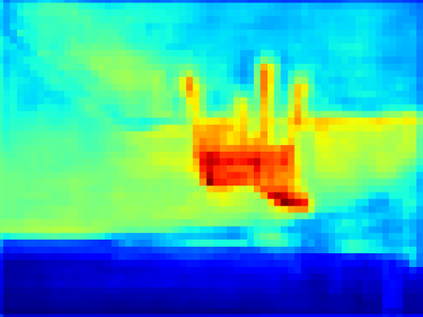
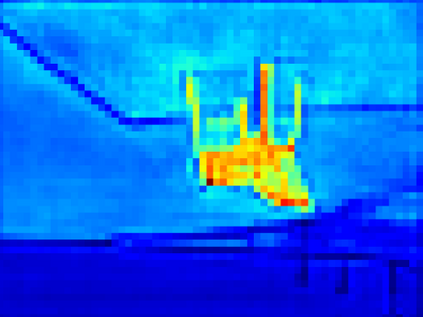
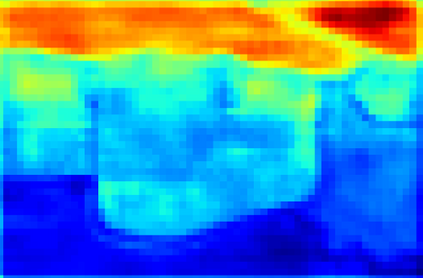
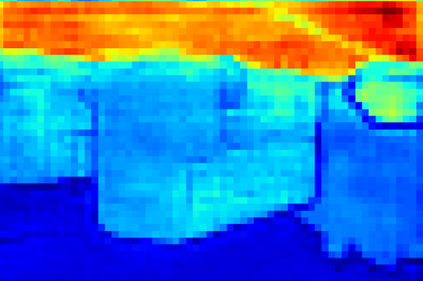
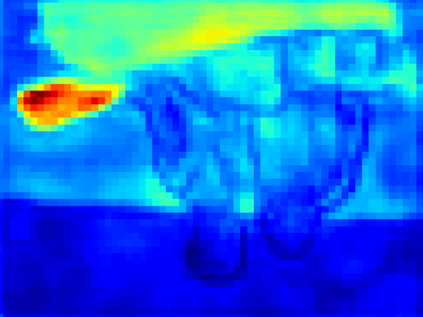
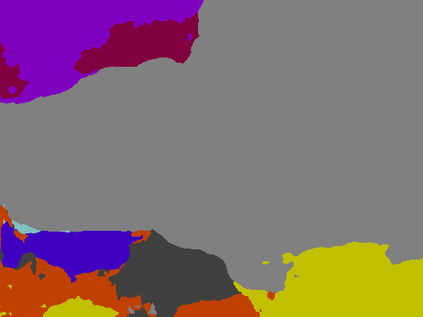
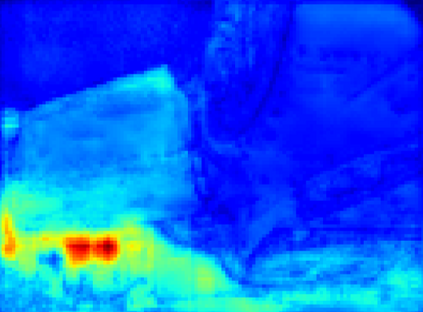
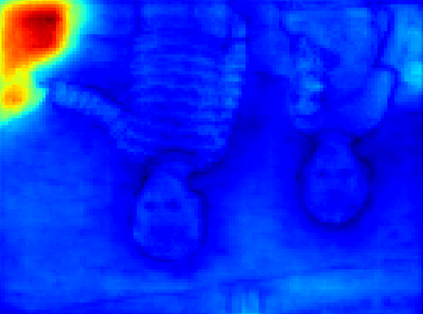
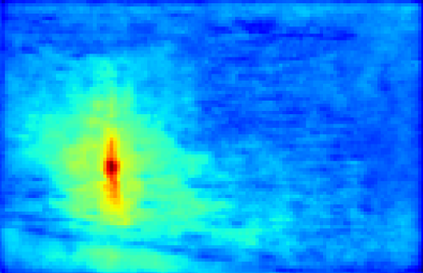
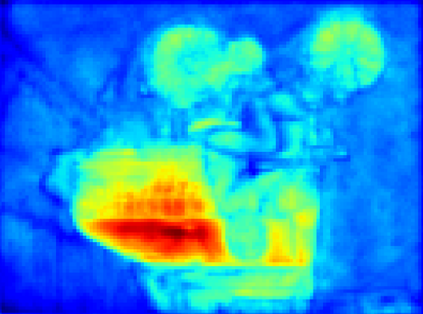
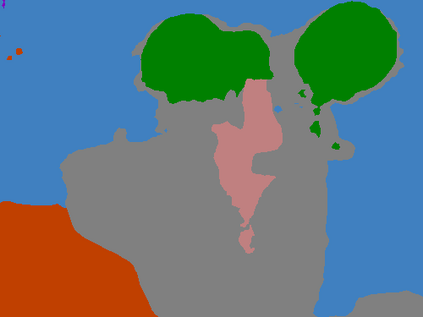
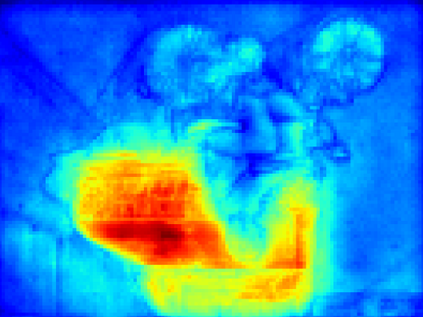
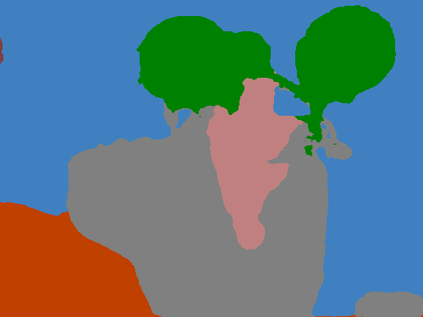
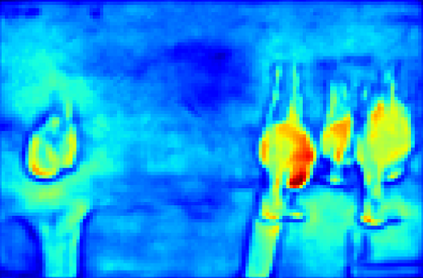
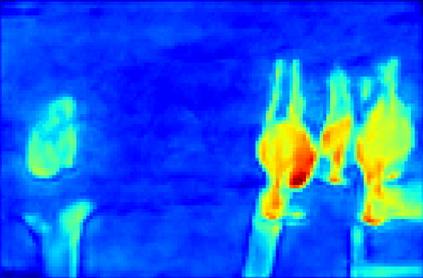
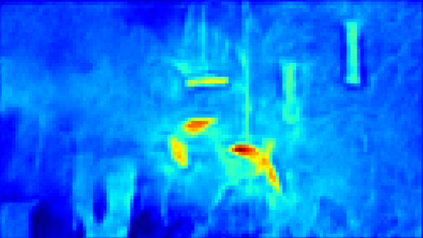
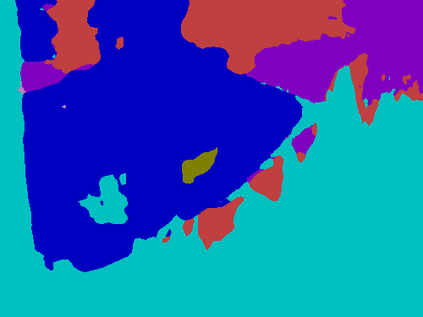
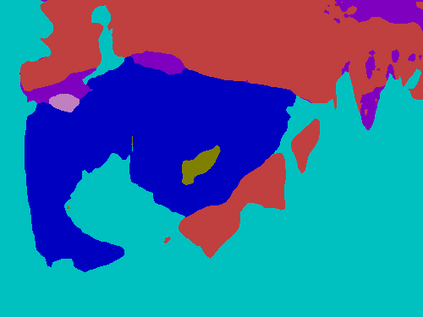
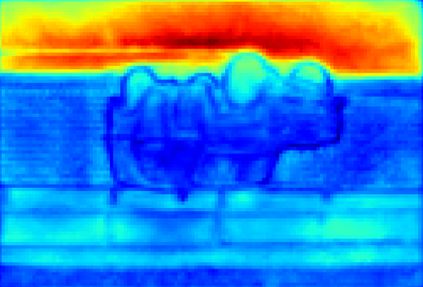
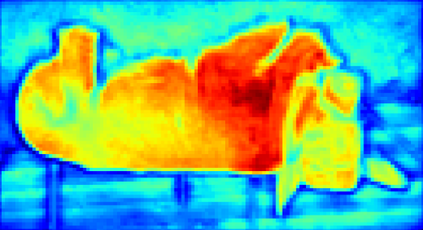
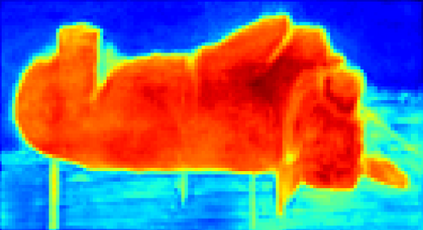
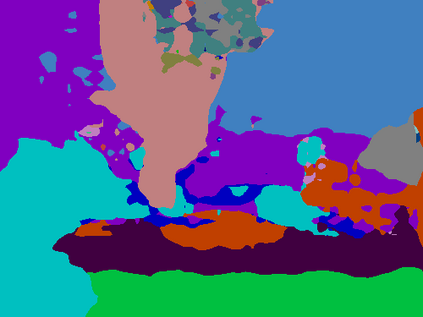
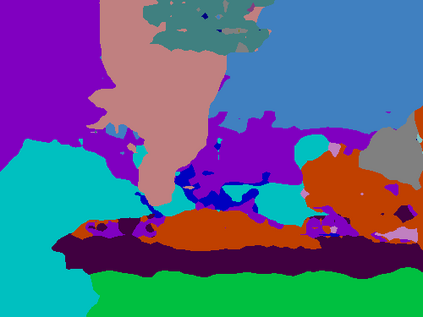
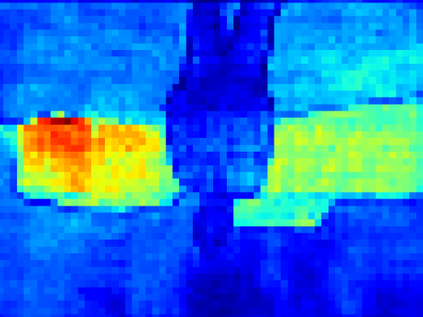
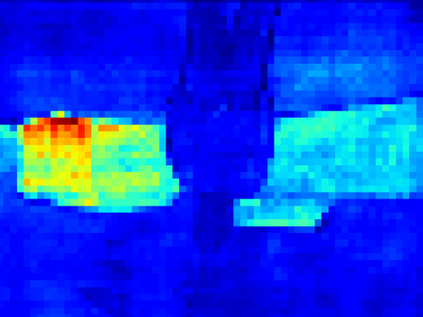
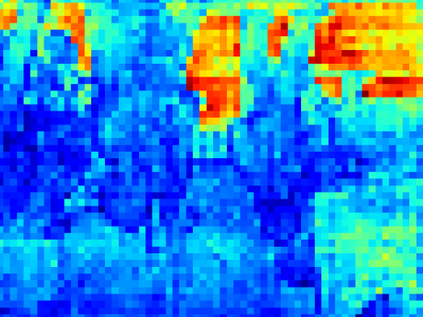
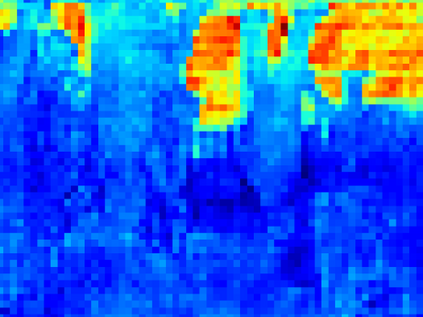
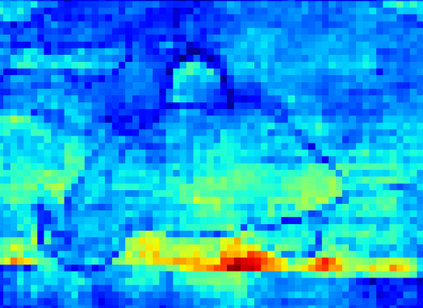
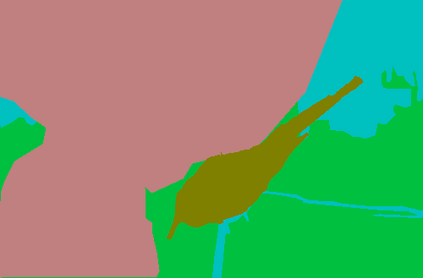
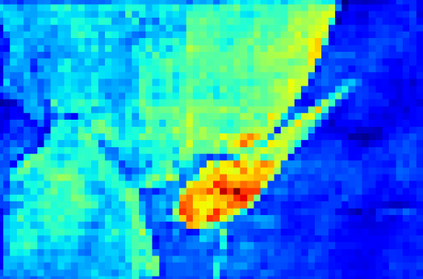
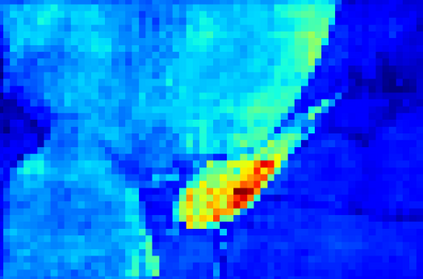
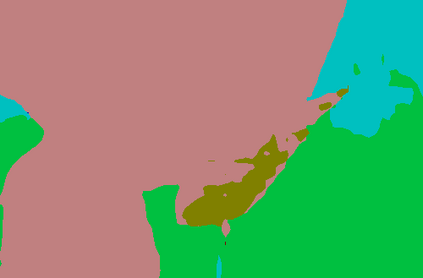
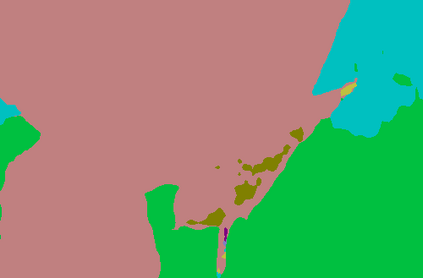
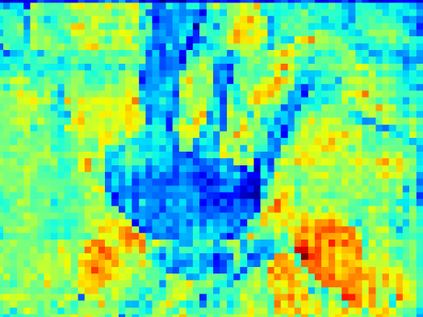
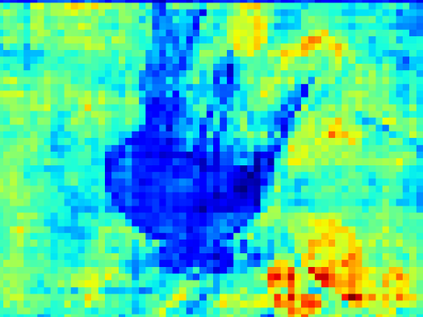
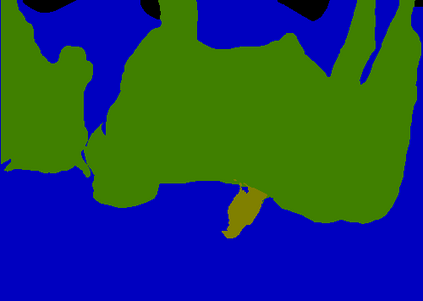
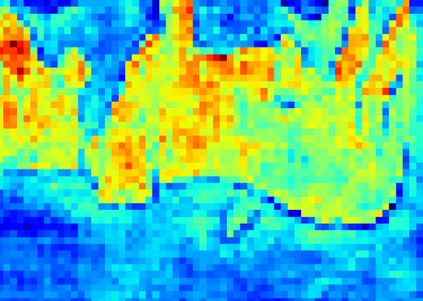
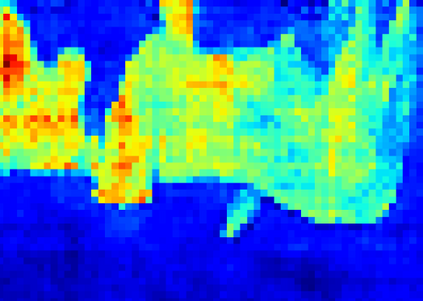
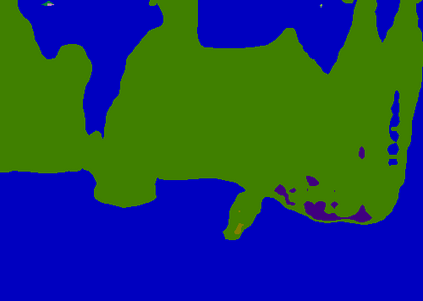
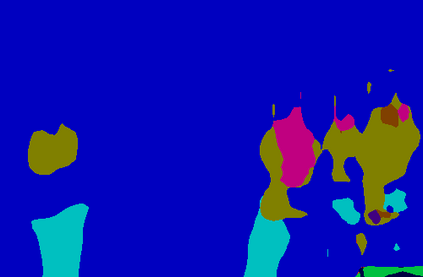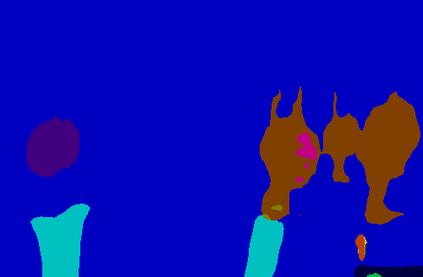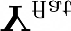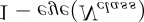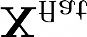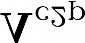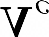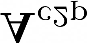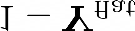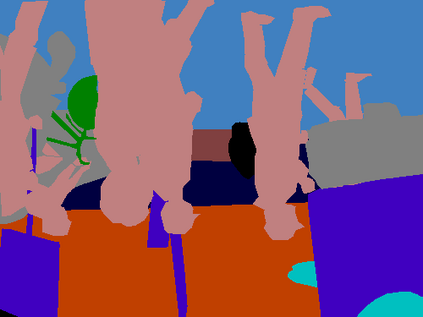Recent segmentation methods, such as OCR and CPNet, utilizing "class level" information in addition to pixel features, have achieved notable success for boosting the accuracy of existing network modules. However, the extracted class-level information was simply concatenated to pixel features, without explicitly being exploited for better pixel representation learning. Moreover, these approaches learn soft class centers based on coarse mask prediction, which is prone to error accumulation. In this paper, aiming to use class level information more effectively, we propose a universal Class-Aware Regularization (CAR) approach to optimize the intra-class variance and inter-class distance during feature learning, motivated by the fact that humans can recognize an object by itself no matter which other objects it appears with. Three novel loss functions are proposed. The first loss function encourages more compact class representations within each class, the second directly maximizes the distance between different class centers, and the third further pushes the distance between inter-class centers and pixels. Furthermore, the class center in our approach is directly generated from ground truth instead of from the error-prone coarse prediction. Our method can be easily applied to most existing segmentation models during training, including OCR and CPNet, and can largely improve their accuracy at no additional inference overhead. Extensive experiments and ablation studies conducted on multiple benchmark datasets demonstrate that the proposed CAR can boost the accuracy of all baseline models by up to 2.23% mIOU with superior generalization ability. The complete code is available at https://github.com/edwardyehuang/CAR.
翻译:除了像素特性外,使用“类级级”信息以及像素特性等最新分解方法,如OCR和CPNet等最近使用“类级”信息,在提高现有网络模块的准确性方面取得了显著的成功。然而,所提取的类级信息只是与像素特性相融合,没有被明确用于更好的像素代表性学习。此外,这些方法学习了基于粗化遮盖预测的软类级中心,这容易造成误差积累。在本文件中,为了更有效地使用类级信息,我们建议采用一种通用类级常规化(CAR)方法,在特征学习期间优化类内差异和类际距离,这是基于以下事实:人类可以自己识别一个对象,而不需要其他对象。提出了三个新的损失功能。第一个损失功能鼓励在每类中增加较紧凑的类级代表,第二个直接最大化不同类中心之间的距离,第三个进一步拉动了类级中心与像素之间的距离。此外,我们的方法是直接从地面真理中生成的,而不是从精确性精确性预测中直接生成的。我们的方法可以很容易地应用于在常规/级级级级/级级级级级级级级级级级级级的精确性测试中进行更多的分析研究。我们的方法,在现有的深度研究中可以展示中进行更多的分析模型,在现有的基础模型中可以显示。我们的方法可以用来在进行更多的分析,在进行。我们现有的深度研究中可以显示,在现有的基础模型中可以显示,在进行。在进行。在进行,在进行更多的研算,在进行更多的研算。在进行更多的研算,在进行。在进行。在进行更多的研算式标度模型中可以用来进行。我们级级级级级级级级级级级标度研究中可以用来进行。