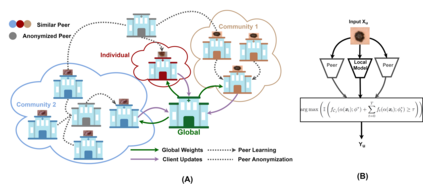
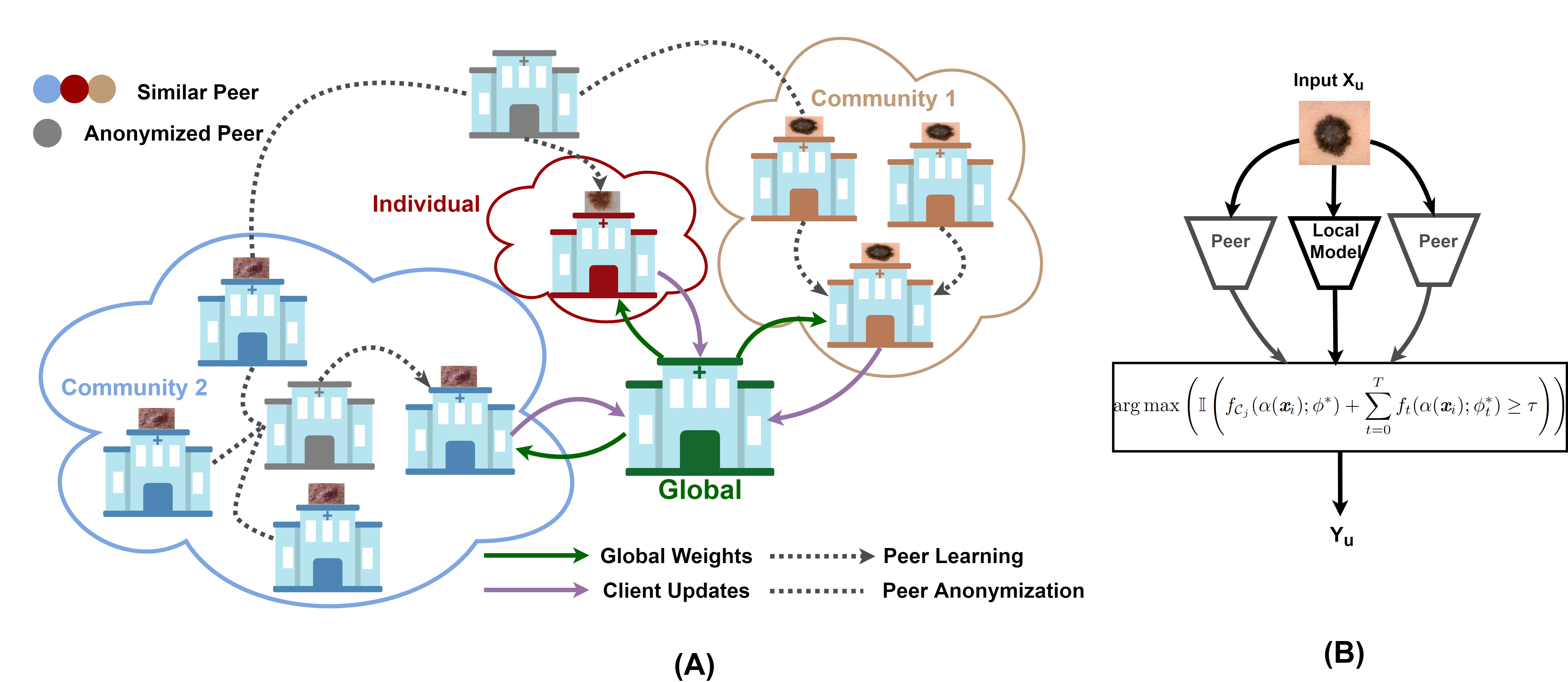
Skin cancer is one of the most deadly cancers worldwide. Yet, it can be reduced by early detection. Recent deep-learning methods have shown a dermatologist-level performance in skin cancer classification. Yet, this success demands a large amount of centralized data, which is oftentimes not available. Federated learning has been recently introduced to train machine learning models in a privacy-preserved distributed fashion demanding annotated data at the clients, which is usually expensive and not available, especially in the medical field. To this end, we propose FedPerl, a semi-supervised federated learning method that utilizes peer learning from social sciences and ensemble averaging from committee machines to build communities and encourage its members to learn from each other such that they produce more accurate pseudo labels. We also propose the peer anonymization (PA) technique as a core component of FedPerl. PA preserves privacy and reduces the communication cost while maintaining the performance without additional complexity. We validated our method on 38,000 skin lesion images collected from 4 publicly available datasets. FedPerl achieves superior performance over the baselines and state-of-the-art SSFL by 15.8%, and 1.8% respectively. Further, FedPerl shows less sensitivity to noisy clients.
翻译:皮肤癌是全世界最致命的癌症之一。 然而,可以通过早期检测来降低癌症。 最近的深层学习方法已经显示了皮肤癌分类方面的皮肤病学水平性能。 然而,这一成功需要大量集中数据,而这些数据往往是没有的。 最近还引入了联邦学习,以在保密的分布式中培训机器学习模式,要求客户提供附加说明数据,通常费用昂贵,且在医疗领域尤其如此。 为此,我们提出了FedPerl, 这是一种半监督的联合会式学习方法,利用社会科学的同行学习,以及从委员会机器中平均从委员会机器中获得的共性学习,建设社区,鼓励其成员相互学习,从而产生更准确的假标签。我们还建议将同行匿名化技术作为FedPerl的核心内容。 PA保护隐私,降低通信成本,同时保持不增加复杂性。 我们验证了我们从4个公开数据集收集的38 000个皮肤病素图像的方法。 FedPerl实现在基线和州-P- SS- 18 客户的敏感度上更高的业绩,分别显示为15.8 % 。