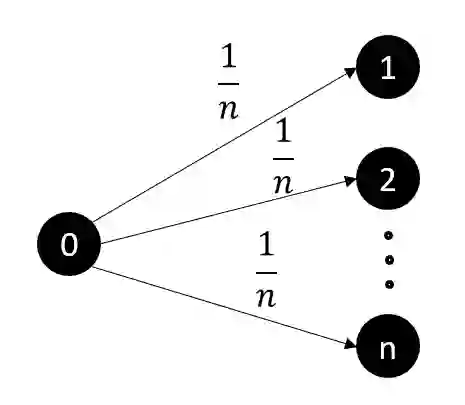
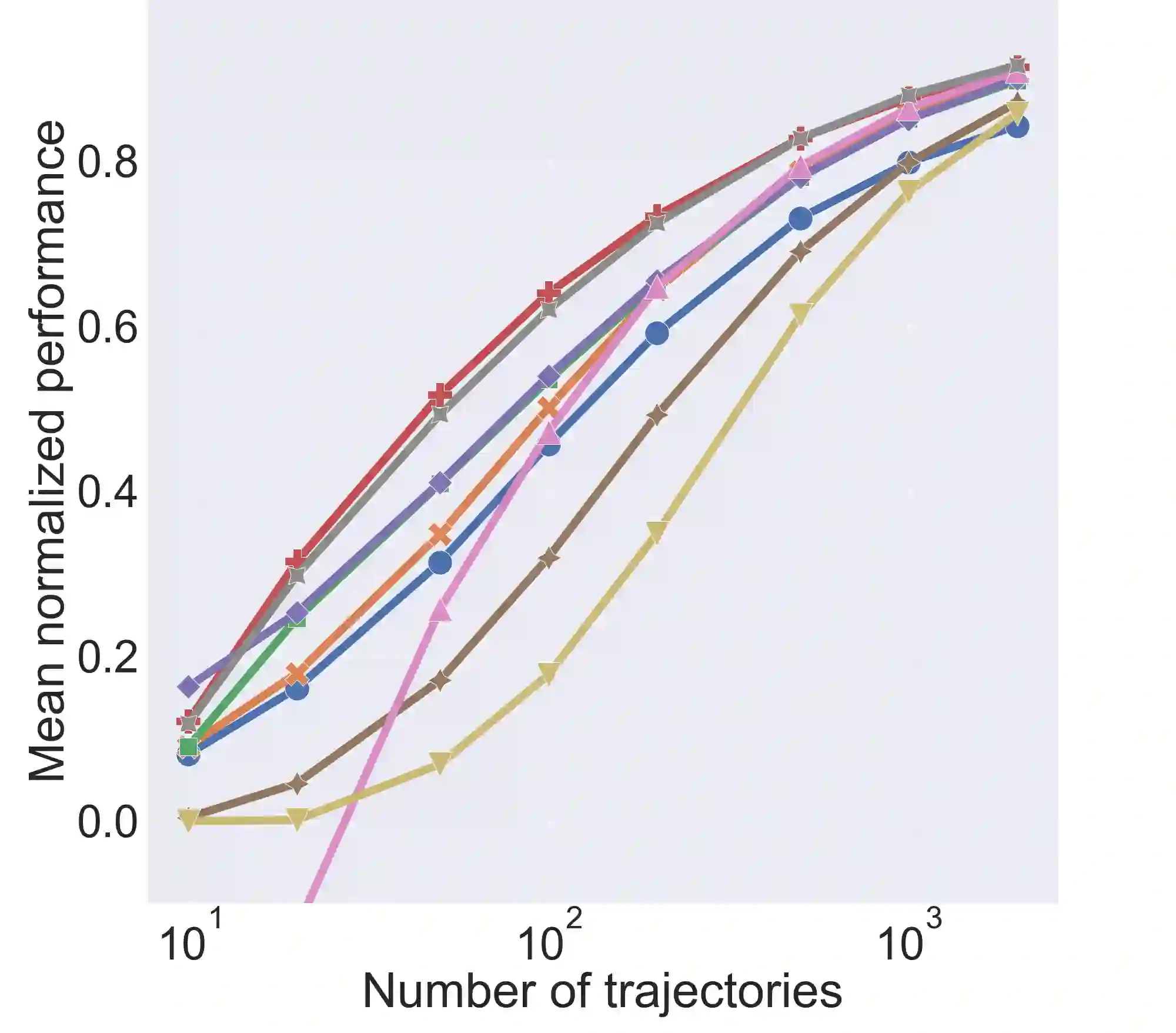
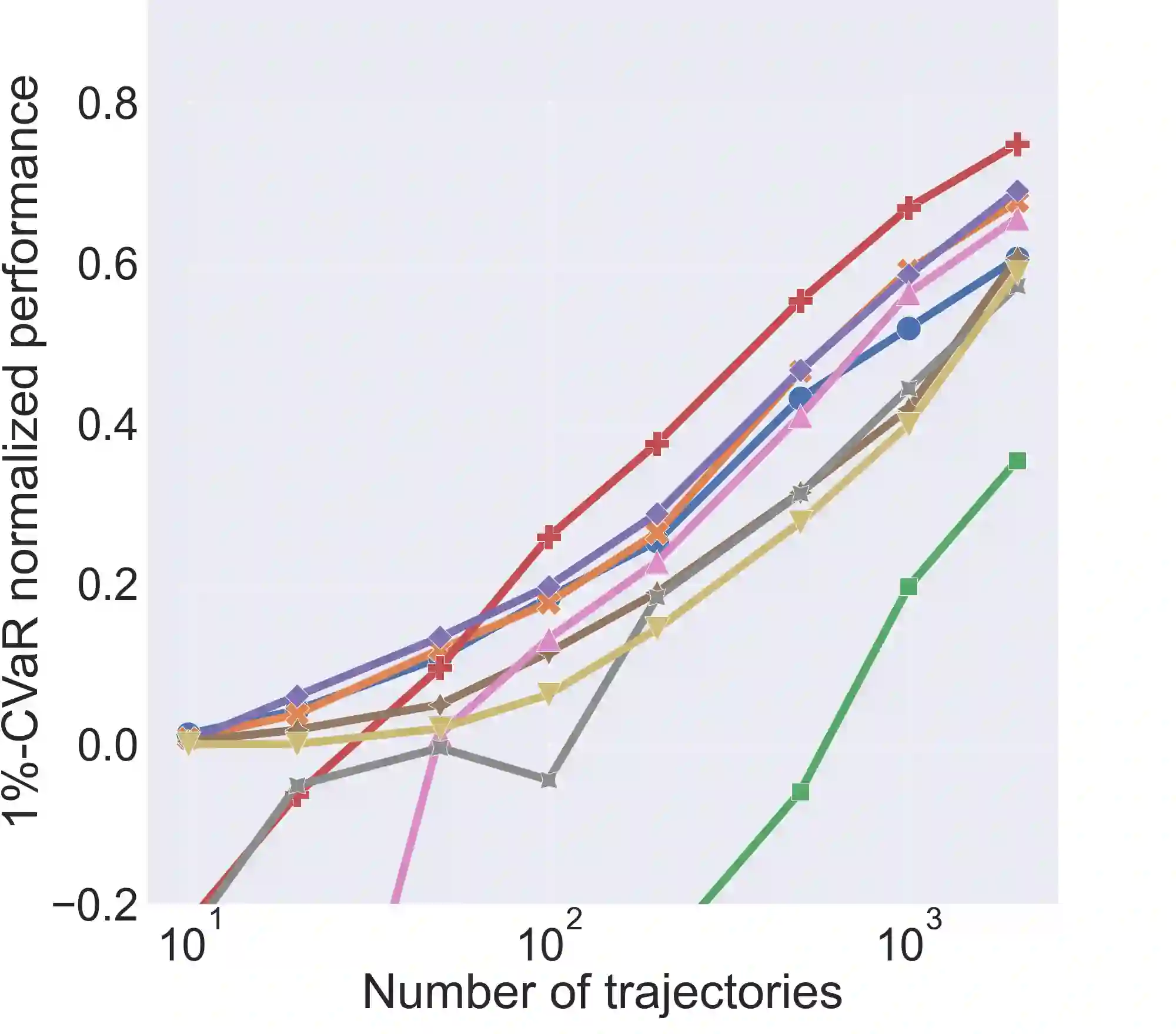
Safe Policy Improvement (SPI) aims at provable guarantees that a learned policy is at least approximately as good as a given baseline policy. Building on SPI with Soft Baseline Bootstrapping (Soft-SPIBB) by Nadjahi et al., we identify theoretical issues in their approach, provide a corrected theory, and derive a new algorithm that is provably safe on finite Markov Decision Processes (MDP). Additionally, we provide a heuristic algorithm that exhibits the best performance among many state of the art SPI algorithms on two different benchmarks. Furthermore, we introduce a taxonomy of SPI algorithms and empirically show an interesting property of two classes of SPI algorithms: while the mean performance of algorithms that incorporate the uncertainty as a penalty on the action-value is higher, actively restricting the set of policies more consistently produces good policies and is, thus, safer.
翻译:安全政策改进(SPI)旨在保证一项已学习的政策至少与既定基线政策大致相同。 在Nadjahi等人的SPI与Soft Base Boutstraping(Soft-SPIB)的基础上,我们找出了他们方法中的理论问题,提供了正确的理论,并得出了一种新的算法,在有限的Markov决策程序(MDP)上,这种算法是相当安全的。此外,我们提供了一种超常的算法,在两种不同的基准上,在先进的SPI算法的许多状态中表现出最佳的性能。 此外,我们采用了SPI算法的分类,从经验上显示了两类SPI算法的有趣属性:虽然将不确定性作为惩罚行动价值的手段的算法的平均性表现更高,但积极限制一套政策更一贯地产生良好的政策,因此更加安全。