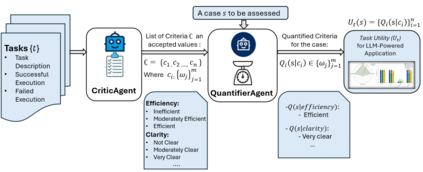
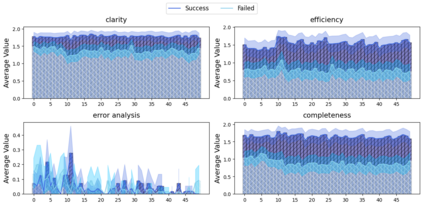
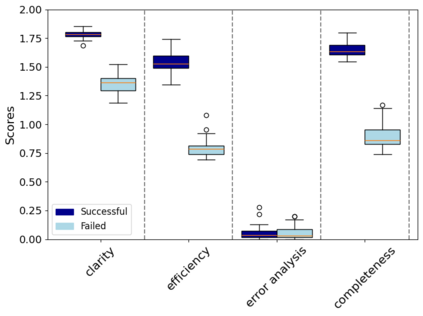
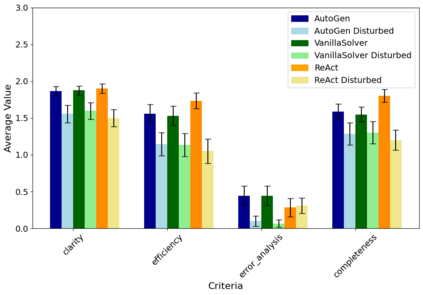
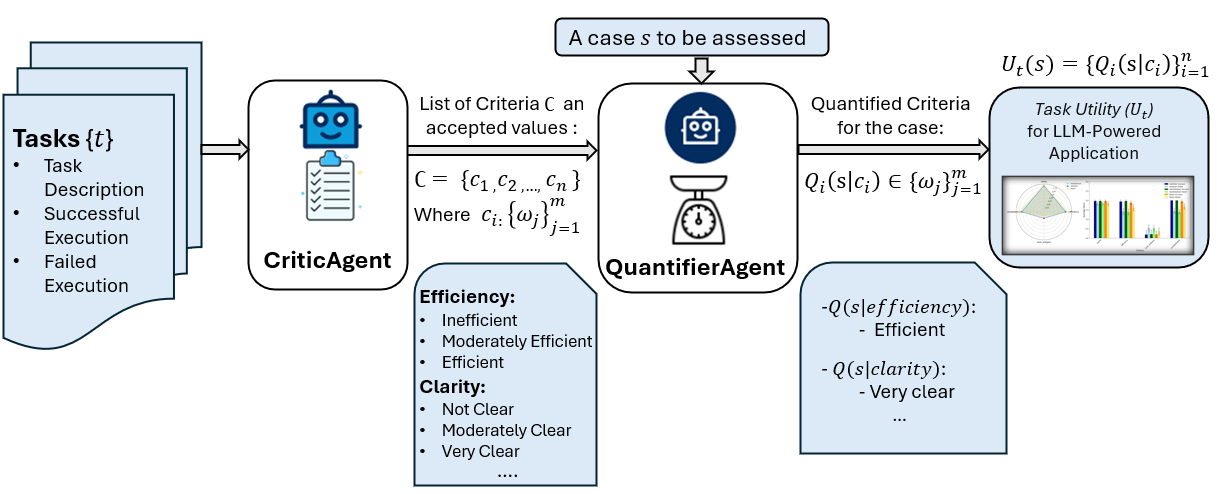
The rapid development in the field of Large Language Models (LLMs) has led to a surge in applications that facilitate collaboration among multiple agents to assist humans in their daily tasks. However, a significant gap remains in assessing whether LLM-powered applications genuinely enhance user experience and task execution efficiency. This highlights the pressing need for methods to verify utility of LLM-powered applications, particularly by ensuring alignment between the application's functionality and end-user needs. We introduce AgentEval provides an implementation for the math problems}, a novel framework designed to simplify the utility verification process by automatically proposing a set of criteria tailored to the unique purpose of any given application. This allows for a comprehensive assessment, quantifying the utility of an application against the suggested criteria. We present a comprehensive analysis of the robustness of quantifier's work.
翻译:暂无翻译