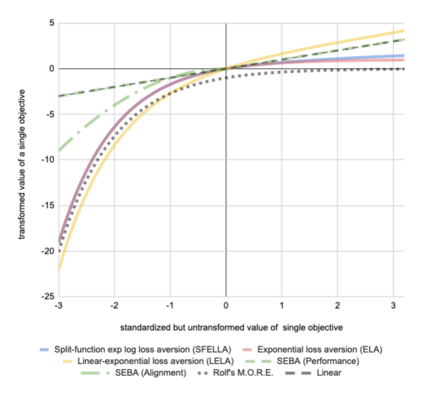
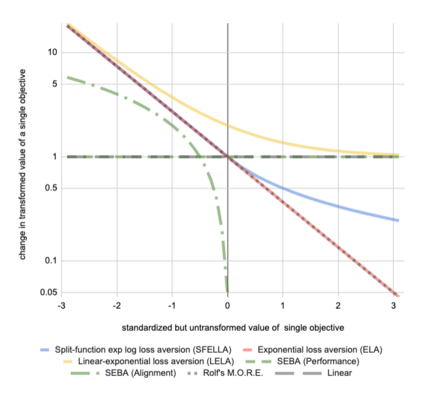
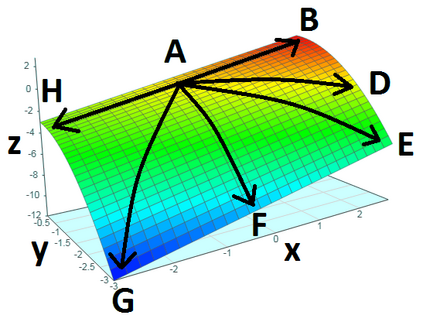
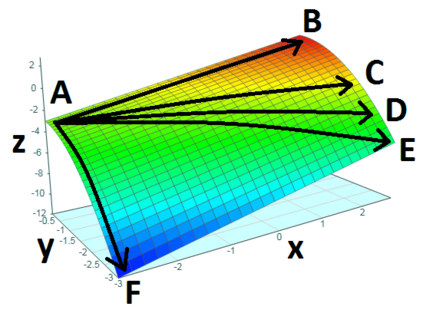
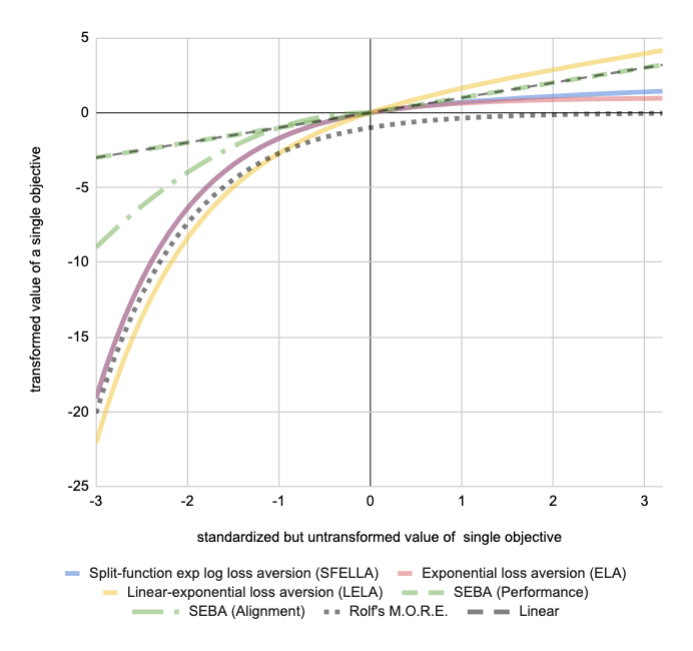
Balancing multiple competing and conflicting objectives is an essential task for any artificial intelligence tasked with satisfying human values or preferences. Conflict arises both from misalignment between individuals with competing values, but also between conflicting value systems held by a single human. Starting with principle of loss-aversion, we designed a set of soft maximin function approaches to multi-objective decision-making. Bench-marking these functions in a set of previously-developed environments, we found that one new approach in particular, `split-function exp-log loss aversion' (SFELLA), learns faster than the state of the art thresholded alignment objective method \cite{vamplew_potential-based_2021} on three of four tasks it was tested on, and achieved the same optimal performance after learning. SFELLA also showed relative robustness improvements against changes in objective scale, which may highlight an advantage dealing with distribution shifts in the environment dynamics. Further work had to be omitted from the preprint, but in the final published version, we will further compare SFELLA to the multi-objective reward exponentials (MORE) approach, demonstrating that SFELLA performs similarly to MORE in a simple previously-described foraging task, but in a modified foraging environment with a new resource that was not depleted as the agent worked, SFELLA collected more of the new resource with very little cost incurred in terms of the old resource. Overall, we found SFELLA useful for avoiding problems that sometimes occur with a thresholded approach, and more reward-responsive than MORE while retaining its conservative, loss-averse incentive structure.
翻译:在满足人类价值或偏好的任何人工智能中,平衡多种相互竞争和相互冲突的目标是一项基本任务。冲突产生于具有相互竞争价值的个人之间的不匹配,但也产生于单个人持有的相互冲突的价值体系。从亏损反转原则开始,我们设计了一套针对多重目标决策的软最大功能方法。用一套以前开发的环境来标注这些功能,我们发现,特别是一种新的方法,即“重复功能爆炸损失反转”(SFELLA),其学习速度快于最起码的调整目标方法(MOE)的状态。在它测试了四项任务中的三项任务中,冲突也发生在一个相互冲突的价值系统之间。从亏损反原则开始,我们设计了一套软最大功能功能的软功能,用于多重目标决策决策。 将这些功能标注在一系列以前开发的环境分布变化中的优势。 进一步的工作不得不从预印中省略下来,但在最后的版本中,我们将SFELLA进一步将SFALA与多目标的奖励指数指数化指数化指数化(MOE)的状态,在SFELE-LA的常规成本上表现了一种类似的成本上,在SFALA的新的成本上,在SFAL-RILE-RI-RIFA的增值成本上,一个新的成本上,在以前的增值成本上,在新的成本上也以一个新的成本上,在新的成本上进行同样的成本上进行着一个新的成本上。