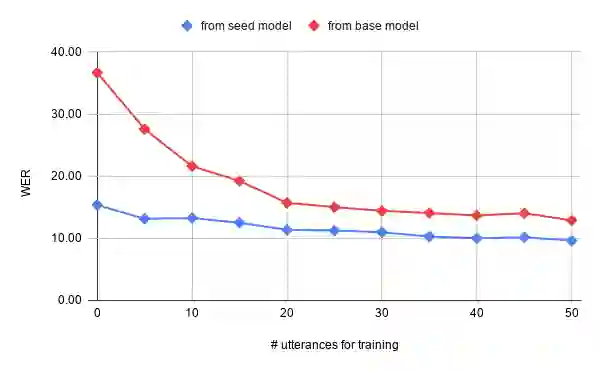
While current state-of-the-art Automatic Speech Recognition (ASR) systems achieve high accuracy on typical speech, they suffer from significant performance degradation on disordered speech and other atypical speech patterns. Personalization of ASR models, a commonly applied solution to this problem, is usually performed in a server-based training environment posing problems around data privacy, delayed model-update times, and communication cost for copying data and models between mobile device and server infrastructure. In this paper, we present an approach to on-device based ASR personalization with very small amounts of speaker-specific data. We test our approach on a diverse set of 100 speakers with disordered speech and find median relative word error rate improvement of 71% with only 50 short utterances required per speaker. When tested on a voice-controlled home automation platform, on-device personalized models show a median task success rate of 81%, compared to only 40% of the unadapted models.
翻译:虽然目前最先进的自动语音识别系统在典型演讲中达到了很高的精确度,但它们在无序演讲和其他非典型演讲模式方面表现严重退化。ASR模型的个性化通常在基于服务器的培训环境中进行,其问题围绕数据隐私、延迟的模型更新时间以及复制移动设备与服务器基础设施之间数据和模型的通信成本。在本文中,我们提出了一个基于基于设备ASR的个人化方法,使用极小的发言者专用数据。我们测试了一套由100名发言者组成的不同组合,使用无序演讲并发现71%的相对字误差率中位数改进,每个发言者只需50个短话。在语音控制的家庭自动化平台上测试时,个人化模型显示中位任务成功率为81%,而未调整的模型只有40%。