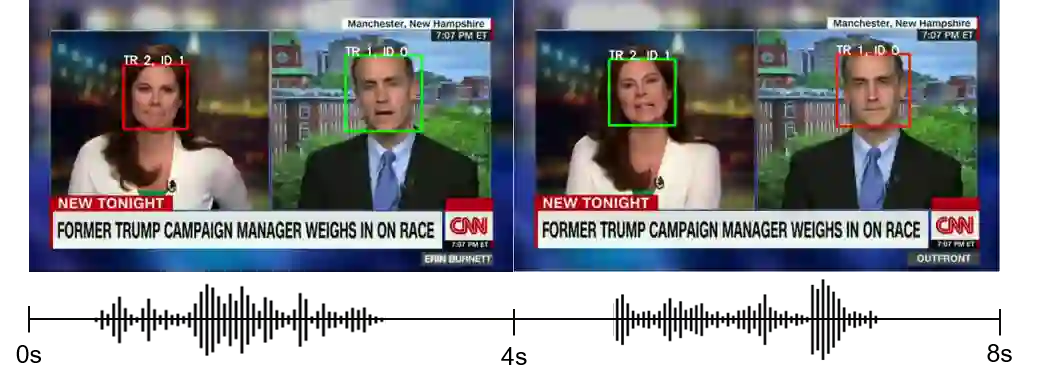
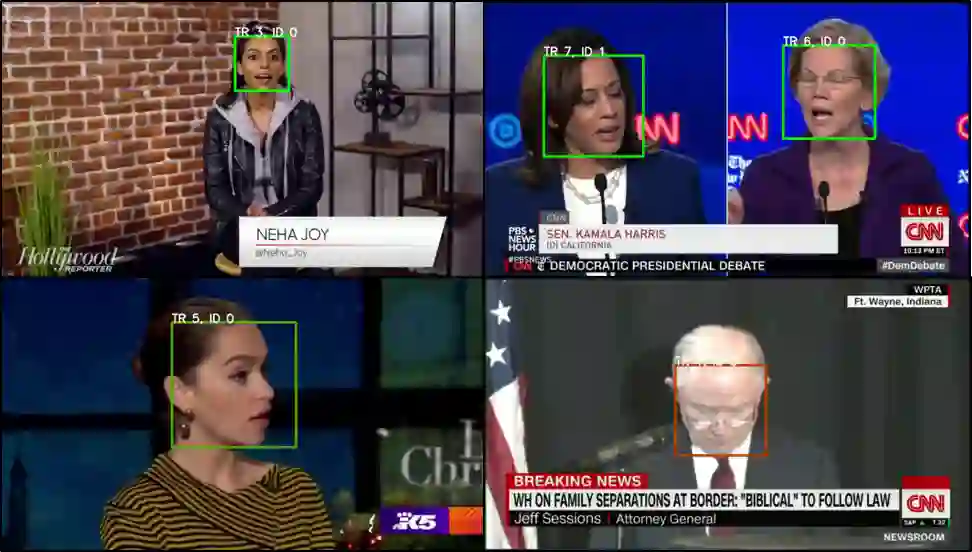
In this work, we present a novel audio-visual dataset for active speaker detection in the wild. A speaker is considered active when his or her face is visible and the voice is audible simultaneously. Although active speaker detection is a crucial pre-processing step for many audio-visual tasks, there is no existing dataset of natural human speech to evaluate the performance of active speaker detection. We therefore curate the Active Speakers in the Wild (ASW) dataset which contains videos and co-occurring speech segments with dense speech activity labels. Videos and timestamps of audible segments are parsed and adopted from VoxConverse, an existing speaker diarisation dataset that consists of videos in the wild. Face tracks are extracted from the videos and active segments are annotated based on the timestamps of VoxConverse in a semi-automatic way. Two reference systems, a self-supervised system and a fully supervised one, are evaluated on the dataset to provide the baseline performances of ASW. Cross-domain evaluation is conducted in order to show the negative effect of dubbed videos in the training data.
翻译:在这项工作中,我们展示了一个用于在野外积极语音检测的新颖的视听数据集。 当一个发言者的面部可见且声音同时可听时,该发言者被视为活跃的视听数据集。虽然积极语音检测是许多视听任务的关键预处理步骤,但目前没有关于自然人类言语的现有数据集来评价积极语音检测的性能。因此,我们在野外(ASW)数据集中,我们翻译了活跃的发言者数据集,该数据集包含带密集语音活动标签的视频和共同发声部分。在VoxConvers提供并采纳了可听部分的视频和时间戳。VoxConvers是现有由野外视频组成的语音对称数据集。从视频中提取了面迹,根据VoxConvers的时标半自动方式,对活动部分作了附加说明。在数据集上评价了两个参考系统,一个是自我监督的系统,一个是完全受监督的系统,以提供ASW的基线性能。进行了交叉评价,以显示培训数据中被涂饰的视频的负面效果。