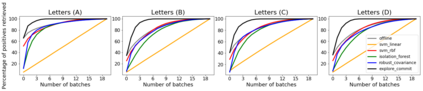
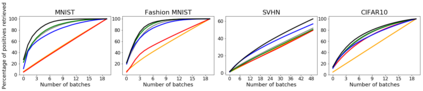
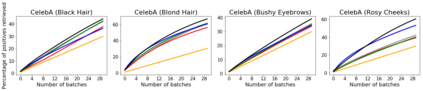
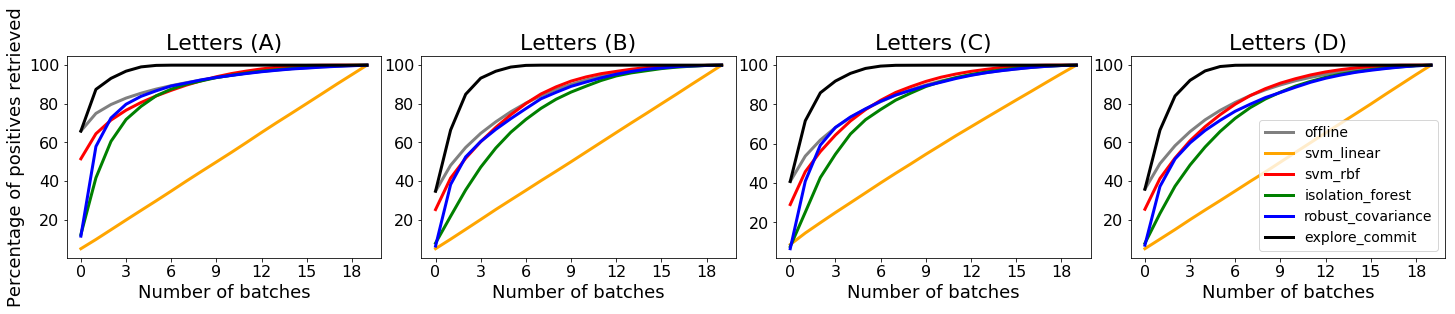
We analyze the problem of active covering, where the learner is given an unlabeled dataset and can sequentially label query examples. The objective is to label query all of the positive examples in the fewest number of total label queries. We show under standard non-parametric assumptions that a classical support estimator can be repurposed as an offline algorithm attaining an excess query cost of $\widetilde{\Theta}(n^{D/(D+1)})$ compared to the optimal learner, where $n$ is the number of datapoints and $D$ is the dimension. We then provide a simple active learning method that attains an improved excess query cost of $\widetilde{O}(n^{(D-1)/D})$. Furthermore, the proposed algorithms only require access to the positive labeled examples, which in certain settings provides additional computational and privacy benefits. Finally, we show that the active learning method consistently outperforms offline methods as well as a variety of baselines on a wide range of benchmark image-based datasets.
翻译:我们分析主动覆盖的问题, 向学习者提供未贴标签的数据集, 并可以按顺序标签查询示例。 目标是在标签查询总数中数量最少的查询中标出所有正面实例。 我们根据标准的非参数假设显示, 经典支持估计器可以重新定位为离线算法, 其查询成本超过$\ lobaltilde\ Theta}(n ⁇ D/ (D+1)}}), 与最佳学习者相比, 最优的查询者相比, 最优的查询者是 $n 是 数据点数, $D( D+1) 是 。 然后, 我们提供简单的主动学习方法, 以获得 $\ loblytilde{ (n ⁇ ( D-1)/ D}) $( $) 改进的超额查询成本。 此外, 拟议的算法仅需要访问正面的标签示例, 在某些环境下, 提供额外的计算和隐私的好处 。 最后, 我们显示, 主动学习方法始终超越离线方法, 以及一系列基于基准的数据集的基线。