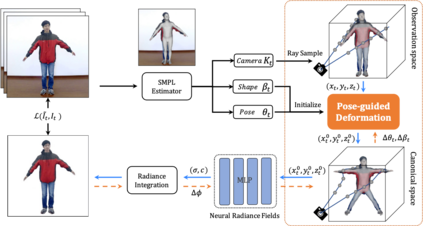
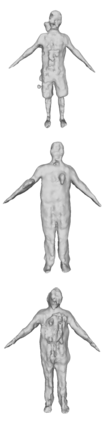
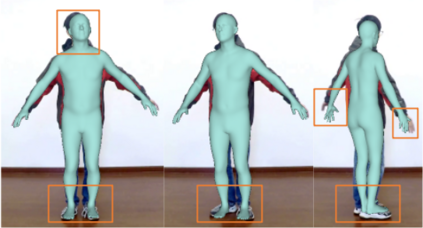
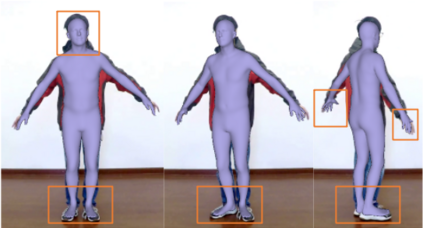
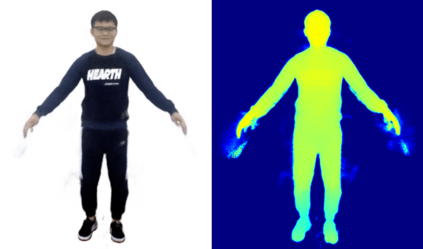
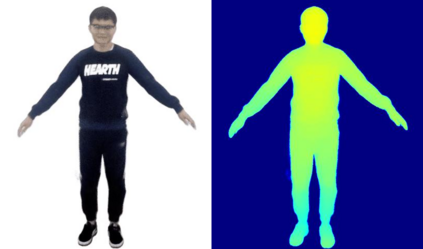
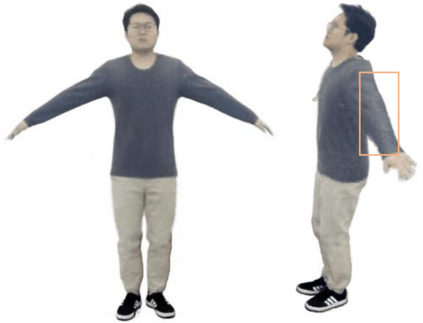
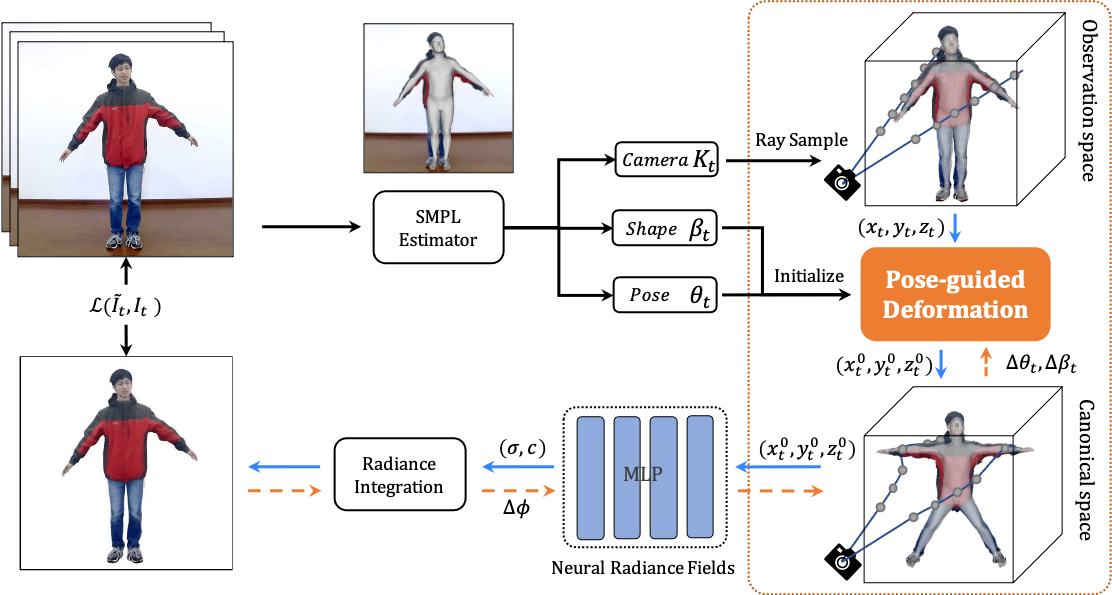
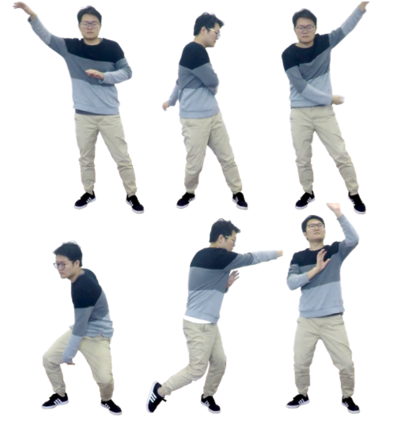We present animatable neural radiance fields (animatable NeRF) for detailed human avatar creation from monocular videos. Our approach extends neural radiance fields (NeRF) to the dynamic scenes with human movements via introducing explicit pose-guided deformation while learning the scene representation network. In particular, we estimate the human pose for each frame and learn a constant canonical space for the detailed human template, which enables natural shape deformation from the observation space to the canonical space under the explicit control of the pose parameters. To compensate for inaccurate pose estimation, we introduce the pose refinement strategy that updates the initial pose during the learning process, which not only helps to learn more accurate human reconstruction but also accelerates the convergence. In experiments we show that the proposed approach achieves 1) implicit human geometry and appearance reconstruction with high-quality details, 2) photo-realistic rendering of the human from novel views, and 3) animation of the human with novel poses.
翻译:我们用单视录象来展示人造动的详细神经光亮场。我们的方法通过在学习场景展示网络的同时引入清晰的外形引导变形,将神经光亮场延伸到人类运动的动态场景。特别是,我们估计每个框架的人类面貌,并学习详细的人类样板的常态光亮空间,使人类从观察空间自然形状变形到由表面参数明确控制的金字塔空间。为了弥补不准确的外观估计,我们引入了在学习过程中更新最初面貌的外形改进战略,这不仅有助于学习更准确的人类重建,而且还加快了趋同速度。在实验中,我们证明拟议方法取得了以下成果:(1) 隐含的人类几何学和外观重建,具有高质量的细节,(2) 人类从新观点中呈现出真实的图像,以及(3) 人造新面的动画。