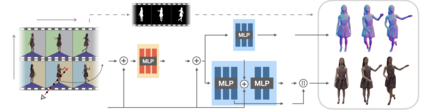
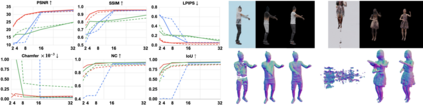
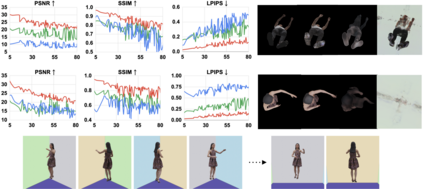
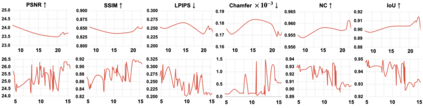
We present H-NeRF, neural radiance fields for rendering and temporal (4D) reconstruction of a human in motion as captured by a sparse set of cameras or even from a monocular video. Our NeRF-inspired approach combines ideas from neural scene representation, novel-view synthesis, and implicit statistical geometric human representations. H-NeRF allows to accurately synthesize images of the observed subject under novel camera views and human poses. Instead of learning a radiance field in empty space, we attach it to a structured implicit human body model, represented using signed distance functions. This allows us to robustly fuse information from sparse views and, at test time, to extrapolate beyond the observed poses or views. Moreover, we apply geometric constraints to co-learn the structure of the observed subject (including both body and clothing) and to regularize the radiance field to geometrical plausible solutions. Extensive experiments on multiple datasets demonstrate the robustness and accuracy of our approach and its generalization capabilities beyond the sparse training set of poses and views.
翻译:我们展示了H-NERF, 用于复制和时间(4D)的神经光亮场, 用于复制和时间(4D) 由一组稀少的相机或甚至从一个单视视频所捕获的人类运动重建的神经光亮场。 我们的NERF所启发的方法结合了神经场演示、新观点合成和隐含的统计几何人类表现等观点。H-NERF允许在新的相机视图和人造外表下准确合成观测到的物体的图像。 我们把它附加在一个结构化的隐含人体模型上,它代表着一个结构化的光亮场上,使用签名的距离功能。这使我们能够从稀少的视图中强有力地整合信息,并在测试时将信息推到所观察到的外观或外观之外。 此外,我们对所观测到的物体的结构(包括身体和衣服)适用几何限制,并将光光场规范为几何貌合理的解决方案。关于多套数据集的广泛实验表明我们的方法的坚固性和准确性及其一般能力,超过了稀少的姿势和视觉训练组合。