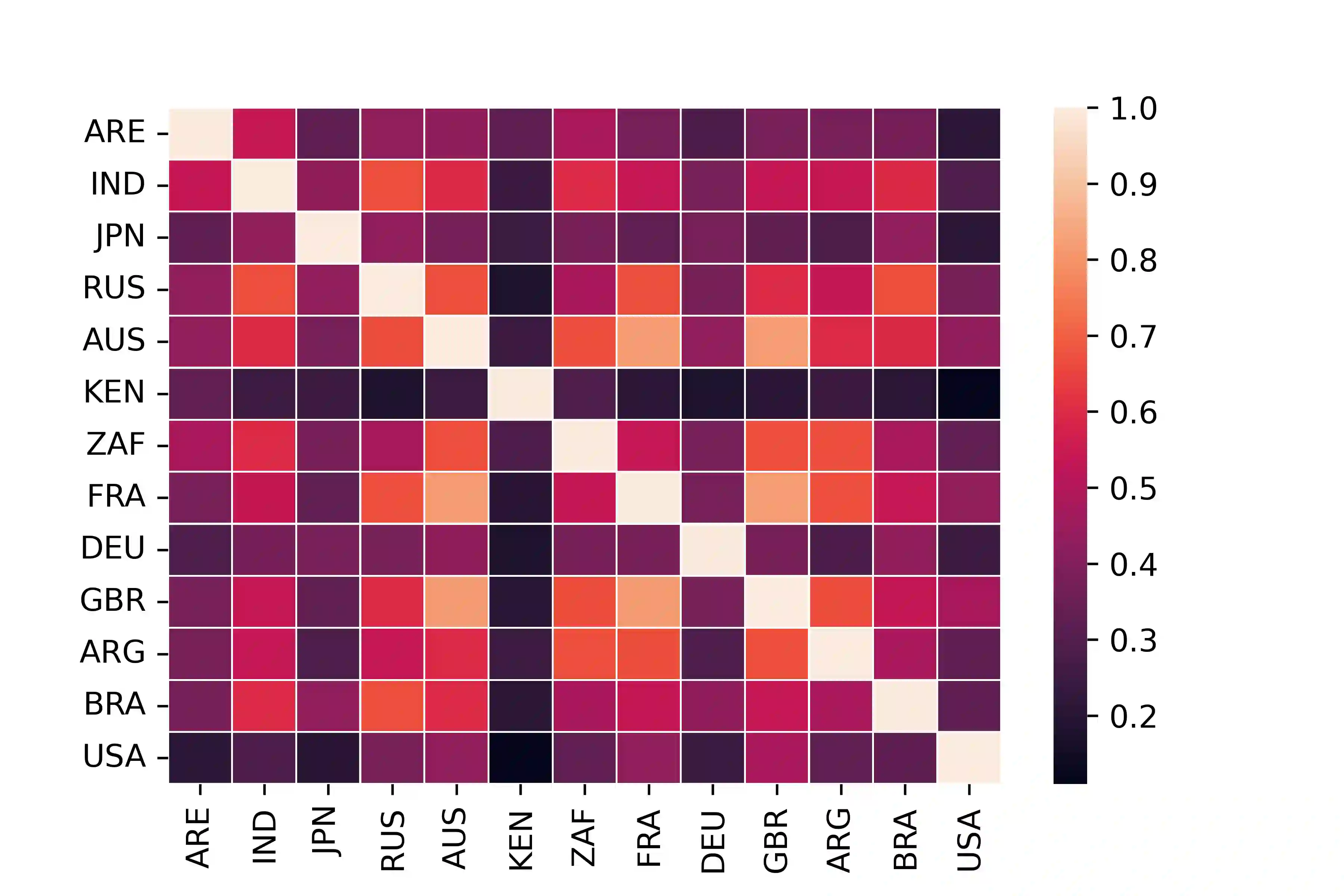
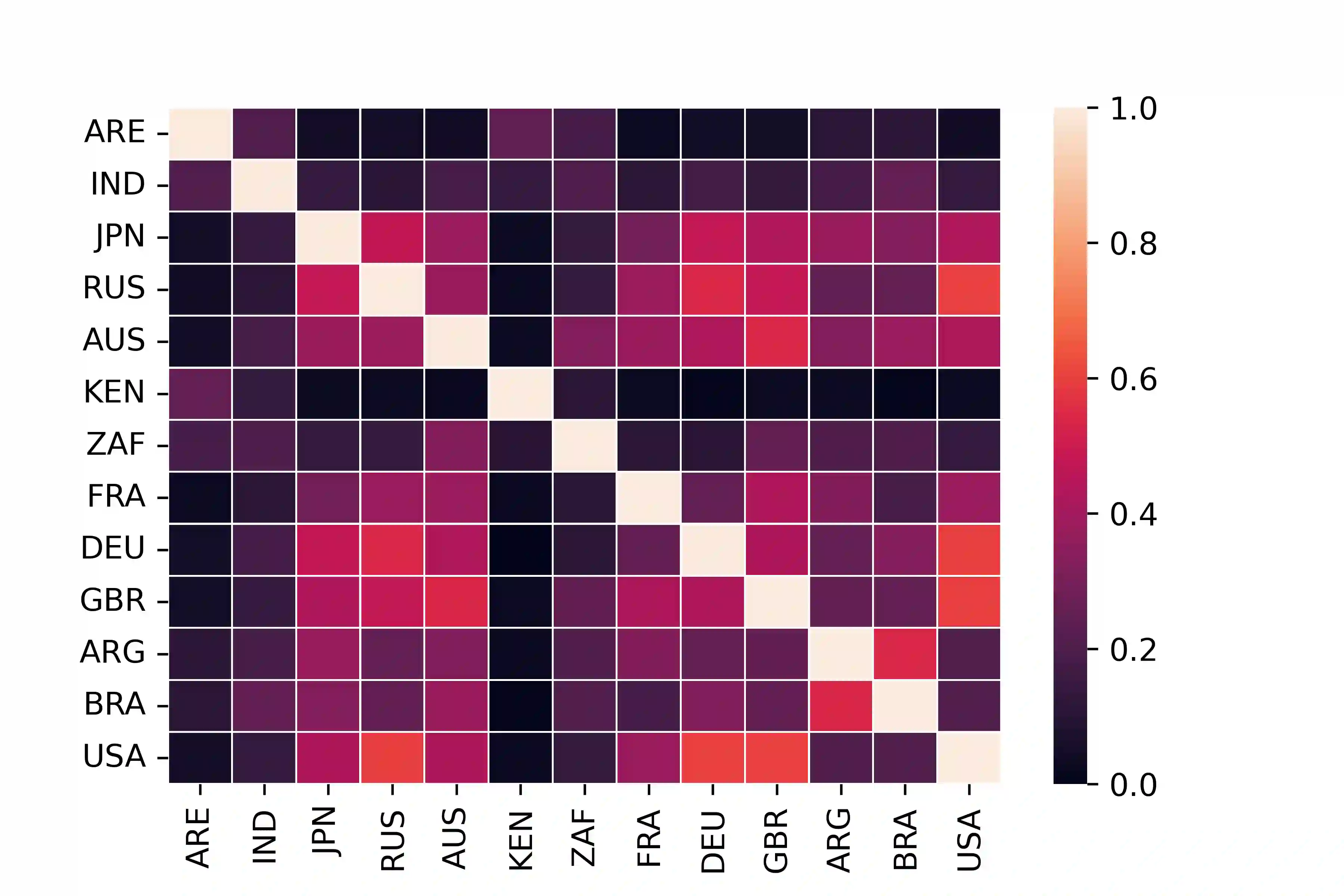
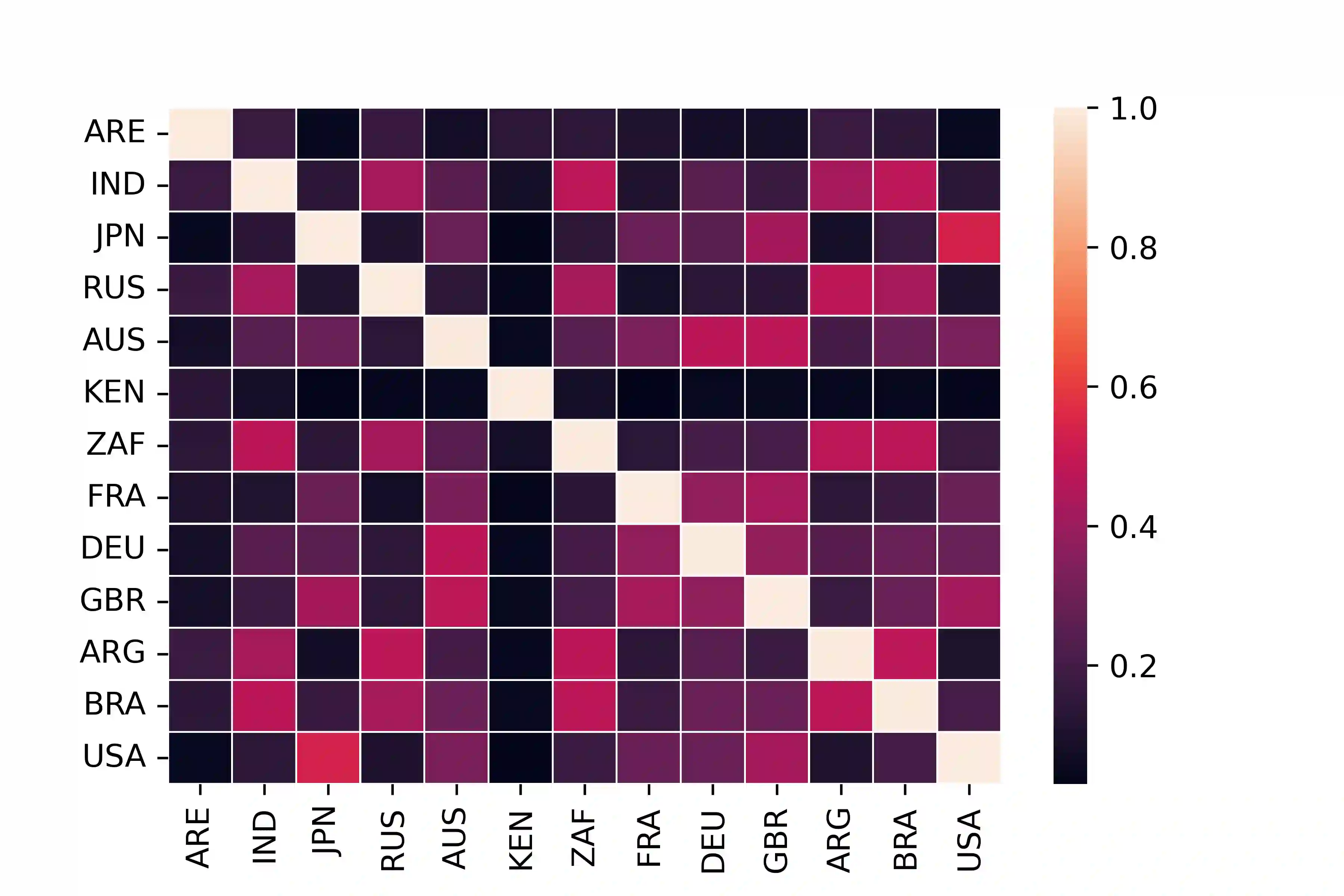
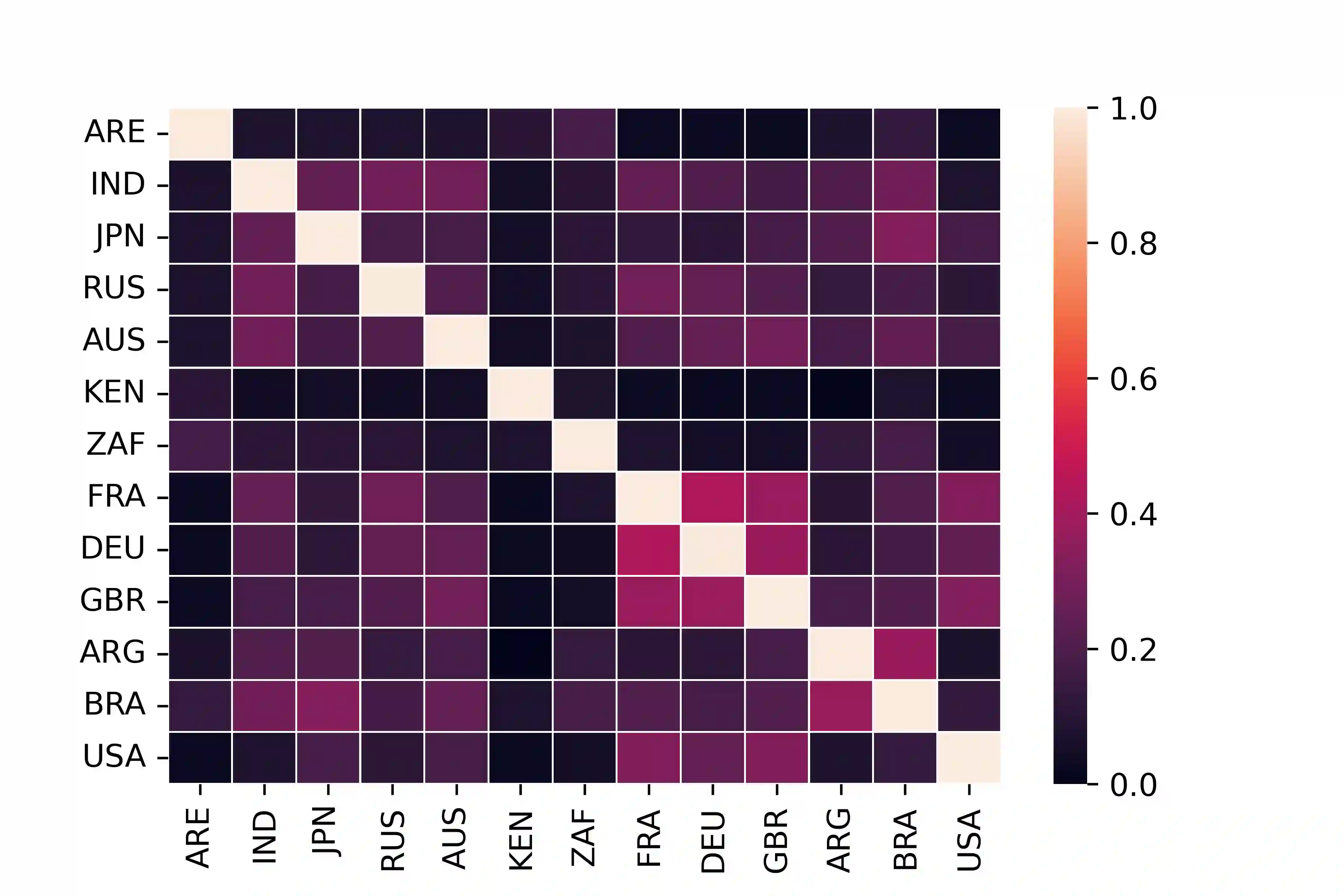
With the widespread use of knowledge graphs (KG) in various automated AI systems and applications, it is very important to ensure that information retrieval algorithms leveraging them are free from societal biases. Previous works have depicted biases that persist in KGs, as well as employed several metrics for measuring the biases. However, such studies lack the systematic exploration of the sensitivity of the bias measurements, through varying sources of data, or the embedding algorithms used. To address this research gap, in this work, we present a holistic analysis of bias measurement on the knowledge graph. First, we attempt to reveal data biases that surface in Wikidata for thirteen different demographics selected from seven continents. Next, we attempt to unfold the variance in the detection of biases by two different knowledge graph embedding algorithms - TransE and ComplEx. We conduct our extensive experiments on a large number of occupations sampled from the thirteen demographics with respect to the sensitive attribute, i.e., gender. Our results show that the inherent data bias that persists in KG can be altered by specific algorithm bias as incorporated by KG embedding learning algorithms. Further, we show that the choice of the state-of-the-art KG embedding algorithm has a strong impact on the ranking of biased occupations irrespective of gender. We observe that the similarity of the biased occupations across demographics is minimal which reflects the socio-cultural differences around the globe. We believe that this full-scale audit of the bias measurement pipeline will raise awareness among the community while deriving insights related to design choices of data and algorithms both and refrain from the popular dogma of ``one-size-fits-all''.
翻译:由于在各种自动化AI系统和应用中广泛使用知识图表(KG),因此非常重要的是要确保信息检索算法在利用这些算法时不带有社会偏见。以前的工作已经描绘了在KGs中持续存在的偏见,并使用了数度来衡量偏差。然而,这些研究缺乏系统探索偏差计量的敏感性,通过不同的数据来源或使用的嵌入算法,解决研究差距。为了解决这一研究差距,我们在本工作中对知识图中的偏差计量进行了全面分析。首先,我们试图揭示维基数据中显示的来自七大洲的13个不同人口组成的维基数据偏差。接下来,我们试图通过两种不同的知识图嵌入算法—— TransE和ComplEx,来展示在发现偏差方面的差异。然而,我们从13个人口统计中抽样的大量职业对敏感属性(即性别)进行广泛的实验。我们的结果显示,KG内嵌入学习算法的13个不同人口结构的偏差会改变公众的内在数据偏差。此外,我们试图通过两种不同的知识图表表达偏差的偏差的偏差,而我们则认为,整个KG内部的性别的计算法的偏差将反映整个统计的偏差的偏差的偏差的偏差将反映于整个的偏差。</s>