【论文推荐】最新六篇推荐系统相关论文—注意力机制、多任务、协同跨网络、非结构化文本、TransRev、章节推荐
【导读】专知内容组整理了最近六篇推荐系统(Recommended System)相关文章,为大家进行介绍,欢迎查看!
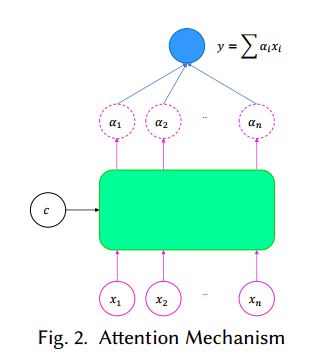
1. Attention-based Group Recommendation(基于注意力机制的群组推荐)
作者:Tran Dang Quang Vinh,Tuan-Anh Nguyen Pham,Gao Cong,Xiao-Li Li
机构:Nanyang Technological University
摘要:Recommender systems are widely used in big information-based companies such as Google, Twitter, LinkedIn, and Netflix. A recommender system deals with the problem of information overload by filtering important information fragments according to users' preferences. In light of the increasing success of deep learning, recent studies have proved the benefits of using deep learning in various recommendation tasks. However, most proposed techniques only aim to target individuals, which cannot be efficiently applied in group recommendation. In this paper, we propose a deep learning architecture to solve the group recommendation problem. On the one hand, as different individual preferences in a group necessitate preference trade-offs in making group recommendations, it is essential that the recommendation model can discover substitutes among user behaviors. On the other hand, it has been observed that a user as an individual and as a group member behaves differently. To tackle such problems, we propose using an attention mechanism to capture the impact of each user in a group. Specifically, our model automatically learns the influence weight of each user in a group and recommends items to the group based on its members' weighted preferences. We conduct extensive experiments on four datasets. Our model significantly outperforms baseline methods and shows promising results in applying deep learning to the group recommendation problem.
期刊:arXiv, 2018年4月18日
网址:
http://www.zhuanzhi.ai/document/ad7353f0987cd74ed6237b8cb9e38788
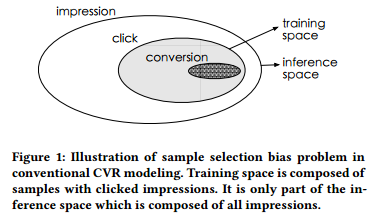
2. Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate
作者:Xiao Ma,Liqin Zhao,Guan Huang,Zhi Wang,Zelin Hu,Xiaoqiang Zhu,Kun Gai
摘要:Estimating post-click conversion rate (CVR) accurately is crucial for ranking systems in industrial applications such as recommendation and advertising. Conventional CVR modeling applies popular deep learning methods and achieves state-of-the-art performance. However it encounters several task-specific problems in practice, making CVR modeling challenging. For example, conventional CVR models are trained with samples of clicked impressions while utilized to make inference on the entire space with samples of all impressions. This causes a sample selection bias problem. Besides, there exists an extreme data sparsity problem, making the model fitting rather difficult. In this paper, we model CVR in a brand-new perspective by making good use of sequential pattern of user actions, i.e., impression -> click -> conversion. The proposed Entire Space Multi-task Model (ESMM) can eliminate the two problems simultaneously by i) modeling CVR directly over the entire space, ii) employing a feature representation transfer learning strategy. Experiments on dataset gathered from Taobao's recommender system demonstrate that ESMM significantly outperforms competitive methods. We also release a sampling version of this dataset to enable future research. To the best of our knowledge, this is the first public dataset which contains samples with sequential dependence of click and conversion labels for CVR modeling.
期刊:arXiv, 2018年4月24日
网址:
http://www.zhuanzhi.ai/document/f0dafe80cfb123dc602fdf62a25b33d4
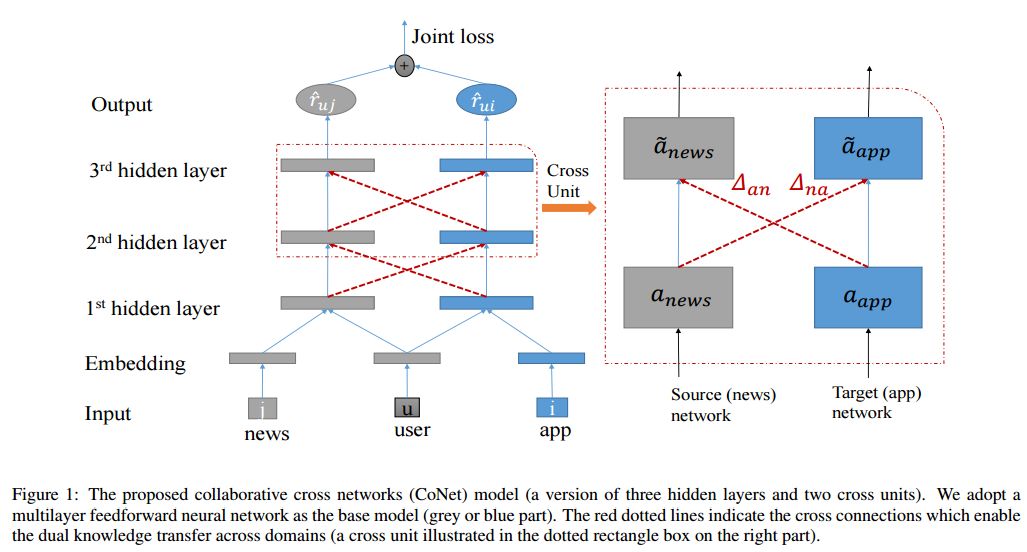
3. CoNet: Collaborative Cross Networks for Cross-Domain Recommendation(CoNet:基于协同跨网络的跨域推荐)
作者:Guangneng Hu,Yu Zhang,Qiang Yang
摘要:The cross-domain recommendation technique is an effective way of alleviating the data sparsity in recommender systems by leveraging the knowledge from relevant domains. Transfer learning is a class of algorithms underlying these techniques. In this paper, we propose a novel transfer learning approach for cross-domain recommendation by using neural networks as the base model. We assume that hidden layers in two base networks are connected by cross mappings, leading to the collaborative cross networks (CoNet). CoNet enables dual knowledge transfer across domains by introducing cross connections from one base network to another and vice versa. CoNet is achieved in multi-layer feedforward networks by adding dual connections and joint loss functions, which can be trained efficiently by back-propagation. The proposed model is evaluated on two real-world datasets and it outperforms baseline models by relative improvements of 3.56\% in MRR and 8.94\% in NDCG, respectively.
期刊:arXiv, 2018年4月21日
网址:
http://www.zhuanzhi.ai/document/f889ca156daabf8974d0792df1901a13
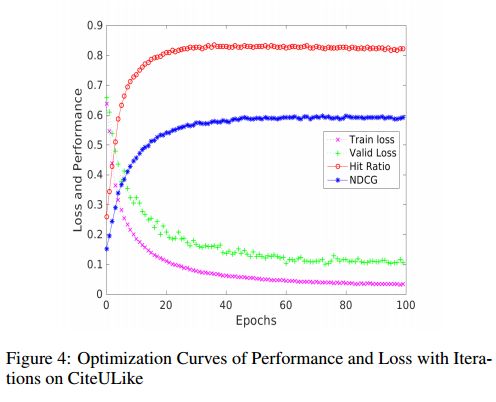
4. LCMR: Local and Centralized Memories for Collaborative Filtering with Unstructured Text(LCMR:对非结构化文本基于局部和中心记忆的协同过滤)
作者:Guangneng Hu,Yu Zhang,Qiang Yang
机构:HKUST
摘要:Collaborative filtering (CF) is the key technique for recommender systems. Pure CF approaches exploit the user-item interaction data (e.g., clicks, likes, and views) only and suffer from the sparsity issue. Items are usually associated with content information such as unstructured text (e.g., abstracts of articles and reviews of products). CF can be extended to leverage text. In this paper, we develop a unified neural framework to exploit interaction data and content information seamlessly. The proposed framework, called LCMR, is based on memory networks and consists of local and centralized memories for exploiting content information and interaction data, respectively. By modeling content information as local memories, LCMR attentively learns what to exploit with the guidance of user-item interaction. On real-world datasets, LCMR shows better performance by comparing with various baselines in terms of the hit ratio and NDCG metrics. We further conduct analyses to understand how local and centralized memories work for the proposed framework.
期刊:arXiv, 2018年4月21日
网址:
http://www.zhuanzhi.ai/document/42f792ba461f483e2b6e1058449a08d1
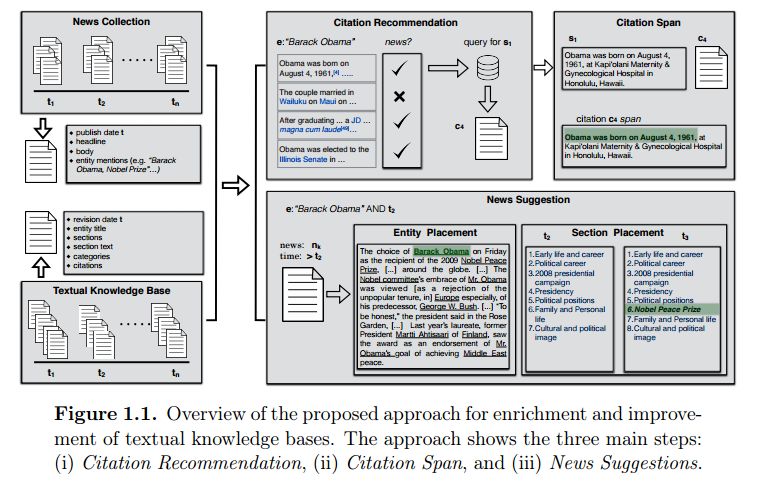
5. TransRev: Modeling Reviews as Translations from Users to Items(TransRev)
作者:Alberto Garcia-Duran,Roberto Gonzalez,Daniel Onoro-Rubio,Mathias Niepert,Hui Li
机构:der Gottfried Wilhelm Leibniz Universität Hannover
摘要:The text of a review expresses the sentiment a customer has towards a particular product. This is exploited in sentiment analysis where machine learning models are used to predict the review score from the text of the review. Furthermore, the products costumers have purchased in the past are indicative of the products they will purchase in the future. This is what recommender systems exploit by learning models from purchase information to predict the items a customer might be interested in. We propose TransRev, an approach to the product recommendation problem that integrates ideas from recommender systems, sentiment analysis, and multi-relational learning into a joint learning objective. TransRev learns vector representations for users, items, and reviews. The embedding of a review is learned such that (a) it performs well as input feature of a regression model for sentiment prediction; and (b) it always translates the reviewer embedding to the embedding of the reviewed items. This allows TransRev to approximate a review embedding at test time as the difference of the embedding of each item and the user embedding. The approximated review embedding is then used with the regression model to predict the review score for each item. TransRev outperforms state of the art recommender systems on a large number of benchmark data sets. Moreover, it is able to retrieve, for each user and item, the review text from the training set whose embedding is most similar to the approximated review embedding.
期刊:arXiv, 2018年4月18日
网址:
http://www.zhuanzhi.ai/document/d414a76c4b97a6c3c04e89e5c79cf28e
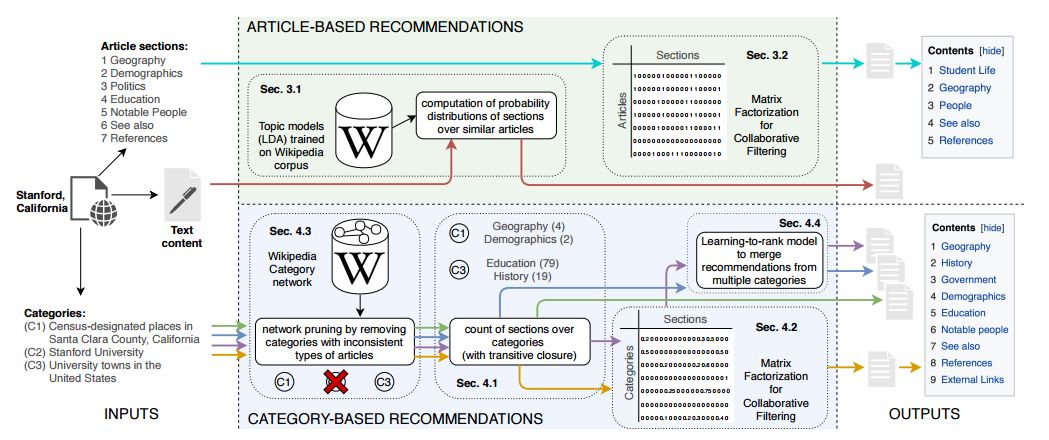
6. Structuring Wikipedia Articles with Section Recommendations(基于维基百科文章的章节推荐)
作者:Tiziano Piccardi,Michele Catasta,Leila Zia,Robert West
机构:Stanford University
摘要:Sections are the building blocks of Wikipedia articles. They enhance readability and can be used as a structured entry point for creating and expanding articles. Structuring a new or already existing Wikipedia article with sections is a hard task for humans, especially for newcomers or less experienced editors, as it requires significant knowledge about how a well-written article looks for each possible topic. Inspired by this need, the present paper defines the problem of section recommendation for Wikipedia articles and proposes several approaches for tackling it. Our systems can help editors by recommending what sections to add to already existing or newly created Wikipedia articles. Our basic paradigm is to generate recommendations by sourcing sections from articles that are similar to the input article. We explore several ways of defining similarity for this purpose (based on topic modeling, collaborative filtering, and Wikipedia's category system). We use both automatic and human evaluation approaches for assessing the performance of our recommendation system, concluding that the category--based approach works best, achieving precision and recall at 10 of about 80\% in the crowdsourcing evaluation.
期刊:arXiv, 2018年4月17日
网址:
http://www.zhuanzhi.ai/document/e3ffa96ad1c10c337f747573d295f27c
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知订阅】人工智能知识资料全集与专知AI知识技术服务群
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
投稿&广告&商务合作:fangquanyi@gmail.com
点击“阅读原文”,使用专知




