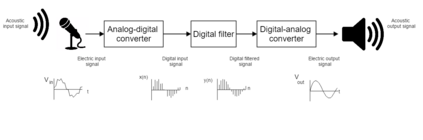
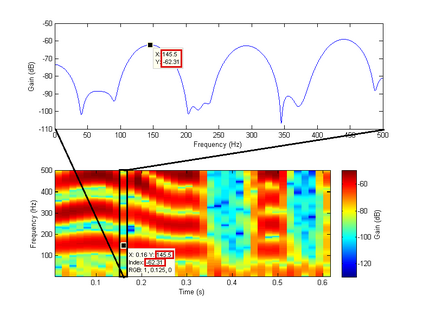
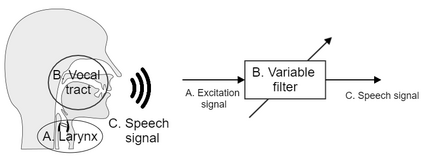
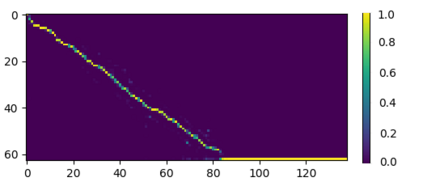
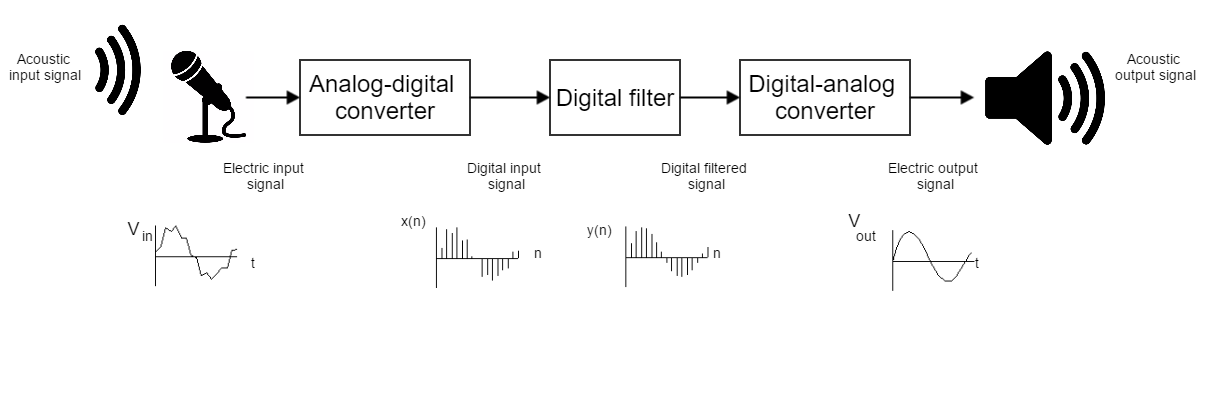
As part of the Human-Computer Interaction field, Expressive speech synthesis is a very rich domain as it requires knowledge in areas such as machine learning, signal processing, sociology, psychology. In this Chapter, we will focus mostly on the technical side. From the recording of expressive speech to its modeling, the reader will have an overview of the main paradigms used in this field, through some of the most prominent systems and methods. We explain how speech can be represented and encoded with audio features. We present a history of the main methods of Text-to-Speech synthesis: concatenative, parametric and statistical parametric speech synthesis. Finally, we focus on the last one, with the last techniques modeling Text-to-Speech synthesis as a sequence-to-sequence problem. This enables the use of Deep Learning blocks such as Convolutional and Recurrent Neural Networks as well as Attention Mechanism. The last part of the Chapter intends to assemble the different aspects of the theory and summarize the concepts.
翻译:作为人类-计算机互动领域的一部分,表达式语音合成是一个非常丰富的领域,因为它需要机器学习、信号处理、社会学、心理学等领域的知识。 在本章中,我们将主要侧重于技术方面。从记录表达式发言到模型制作,读者将概述该领域使用的主要范式,通过一些最突出的系统和方法。我们解释如何代表语言,并用音频特征编码。我们展示了文本到语音合成的主要方法的历史:解析、参数和统计等分数语音合成。最后,我们侧重于最后一个方面,即将文字到语音合成作为最后一种技术模型,作为按顺序排列的问题。这样就能够使用深层学习块,如演进和常规神经网络以及注意机制。本章最后一部分打算汇集理论的不同方面并总结概念。