【论文推荐】最新八篇生成对抗网络相关论文—条件翻译、RGB-D动作识别、量子生成对抗网络、语义对齐、视频摘要、视觉-文本注意力
【导读】专知内容组昨天为大家推荐了八篇生成对抗网络(Generative Adversarial Networks )相关文章,今天又整理了最近八篇生成对抗网络相关文章,为大家进行介绍,欢迎查看!
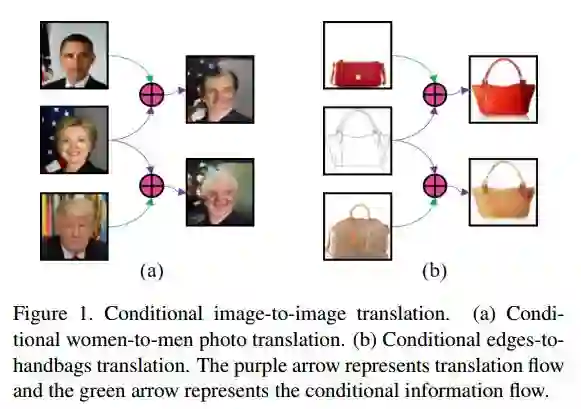
9.Conditional Image-to-Image Translation(图像到图像的条件翻译)
作者:Jianxin Lin,Yingce Xia,Tao Qin,Zhibo Chen,Tie-Yan Liu
IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
机构:University of Science and Technology of China
摘要:Image-to-image translation tasks have been widely investigated with Generative Adversarial Networks (GANs) and dual learning. However, existing models lack the ability to control the translated results in the target domain and their results usually lack of diversity in the sense that a fixed image usually leads to (almost) deterministic translation result. In this paper, we study a new problem, conditional image-to-image translation, which is to translate an image from the source domain to the target domain conditioned on a given image in the target domain. It requires that the generated image should inherit some domain-specific features of the conditional image from the target domain. Therefore, changing the conditional image in the target domain will lead to diverse translation results for a fixed input image from the source domain, and therefore the conditional input image helps to control the translation results. We tackle this problem with unpaired data based on GANs and dual learning. We twist two conditional translation models (one translation from A domain to B domain, and the other one from B domain to A domain) together for inputs combination and reconstruction while preserving domain independent features. We carry out experiments on men's faces from-to women's faces translation and edges to shoes&bags translations. The results demonstrate the effectiveness of our proposed method.
期刊:arXiv, 2018年5月1日
网址:
http://www.zhuanzhi.ai/document/5e9a09890db9c0011620962558c385f1
10.Learning Human Pose Models from Synthesized Data for Robust RGB-D Action Recognition(从合成数据中学习人类姿态模型以实现鲁棒的RGB-D动作识别)
作者:Jian Liu,Naveed Akhtar,Ajmal Mian
Revision submitted to IJCV
摘要:We propose Human Pose Models that represent RGB and depth images of human poses independent of clothing textures, backgrounds, lighting conditions, body shapes and camera viewpoints. Learning such universal models requires training images where all factors are varied for every human pose. Capturing such data is prohibitively expensive. Therefore, we develop a framework for synthesizing the training data. First, we learn representative human poses from a large corpus of real motion captured human skeleton data. Next, we fit synthetic 3D humans with different body shapes to each pose and render each from 180 camera viewpoints while randomly varying the clothing textures, background and lighting. Generative Adversarial Networks are employed to minimize the gap between synthetic and real image distributions. CNN models are then learned that transfer human poses to a shared high-level invariant space. The learned CNN models are then used as invariant feature extractors from real RGB and depth frames of human action videos and the temporal variations are modelled by Fourier Temporal Pyramid. Finally, linear SVM is used for classification. Experiments on three benchmark cross-view human action datasets show that our algorithm outperforms existing methods by significant margins for RGB only and RGB-D action recognition.

期刊:arXiv, 2018年5月1日
网址:
http://www.zhuanzhi.ai/document/be034b5f8f292668a58ec5b53f5a3e0e
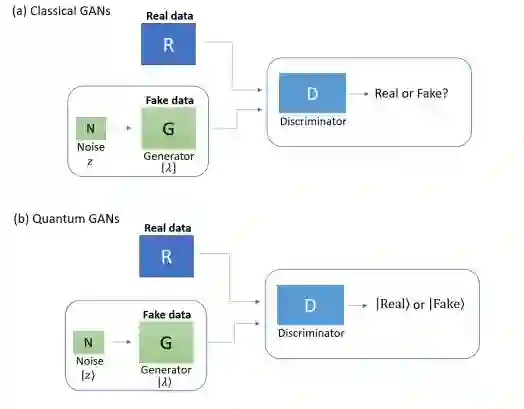
11.Quantum generative adversarial networks(量子生成对抗网络)
作者:Pierre-Luc Dallaire-Demers,Nathan Killoran
摘要:Quantum machine learning is expected to be one of the first potential general-purpose applications of near-term quantum devices. A major recent breakthrough in classical machine learning is the notion of generative adversarial training, where the gradients of a discriminator model are used to train a separate generative model. In this work and a companion paper, we extend adversarial training to the quantum domain and show how to construct generative adversarial networks using quantum circuits. Furthermore, we also show how to compute gradients -- a key element in generative adversarial network training -- using another quantum circuit. We give an example of a simple practical circuit ansatz to parametrize quantum machine learning models and perform a simple numerical experiment to demonstrate that quantum generative adversarial networks can be trained successfully.
期刊:arXiv, 2018年5月1日
网址:
http://www.zhuanzhi.ai/document/99499d8bdb6a265172b5047b36ab3cb1
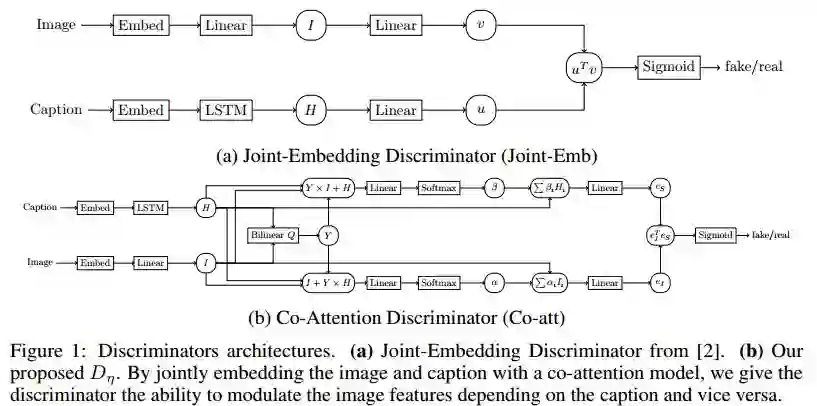
12.Improved Image Captioning with Adversarial Semantic Alignment(改进的图像描述与对抗的语义对齐)
作者:Igor Melnyk,Tom Sercu,Pierre L. Dognin,Jarret Ross,Youssef Mroueh
机构:IBM Research
摘要:In this paper we propose a new conditional GAN for image captioning that enforces semantic alignment between images and captions through a co-attentive discriminator and a context-aware LSTM sequence generator. In order to train these sequence GANs, we empirically study two algorithms: Self-critical Sequence Training (SCST) and Gumbel Straight-Through. Both techniques are confirmed to be viable for training sequence GANs. However, SCST displays better gradient behavior despite not directly leveraging gradients from the discriminator. This ensures a stronger stability of sequence GANs training and ultimately produces models with improved results under human evaluation. Automatic evaluation of GAN trained captioning models is an open question. To remedy this, we introduce a new semantic score with strong correlation to human judgement. As a paradigm for evaluation, we suggest that the generalization ability of the captioner to Out of Context (OOC) scenes is an important criterion to assess generalization and composition. To this end, we propose an OOC dataset which, combined with our automatic metric of semantic score, is a new benchmark for the captioning community to measure the generalization ability of automatic image captioning. Under this new OOC benchmark, and on the traditional MSCOCO dataset, our models trained with SCST have strong performance in both semantic score and human evaluation.
期刊:arXiv, 2018年5月1日
网址:
http://www.zhuanzhi.ai/document/ba4de394724144531093790fb8ad8250
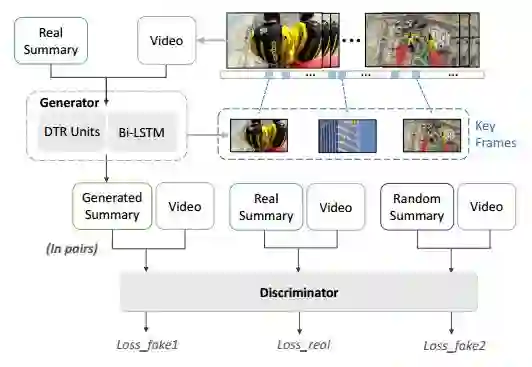
13.DTR-GAN: Dilated Temporal Relational Adversarial Network for Video Summarization(DTR-GAN:用于视频摘要的扩展的时间关系对抗网络)
作者:Yujia Zhang,Michael Kampffmeyer,Xiaodan Liang,Dingwen Zhang,Min Tan,Eric P. Xing
摘要:The large amount of videos popping up every day, make it is more and more critical that key information within videos can be extracted and understood in a very short time. Video summarization, the task of finding the smallest subset of frames, which still conveys the whole story of a given video, is thus of great significance to improve efficiency of video understanding. In this paper, we propose a novel Dilated Temporal Relational Generative Adversarial Network (DTR-GAN) to achieve frame-level video summarization. Given a video, it can select a set of key frames, which contains the most meaningful and compact information. Specifically, DTR-GAN learns a dilated temporal relational generator and a discriminator with three-player loss in an adversarial manner. A new dilated temporal relation (DTR) unit is introduced for enhancing temporal representation capturing. The generator aims to select key frames by using DTR units to effectively exploit global multi-scale temporal context and to complement the commonly used Bi-LSTM. To ensure that the summaries capture enough key video representation from a global perspective rather than a trivial randomly shorten sequence, we present a discriminator that learns to enforce both the information completeness and compactness of summaries via a three-player loss. The three-player loss includes the generated summary loss, the random summary loss, and the real summary (ground-truth) loss, which play important roles for better regularizing the learned model to obtain useful summaries. Comprehensive experiments on two public datasets SumMe and TVSum show the superiority of our DTR-GAN over the state-of-the-art approaches.
期刊:arXiv, 2018年4月30日
网址:
http://www.zhuanzhi.ai/document/35d90482a76f660a853cc8323d2fad6f
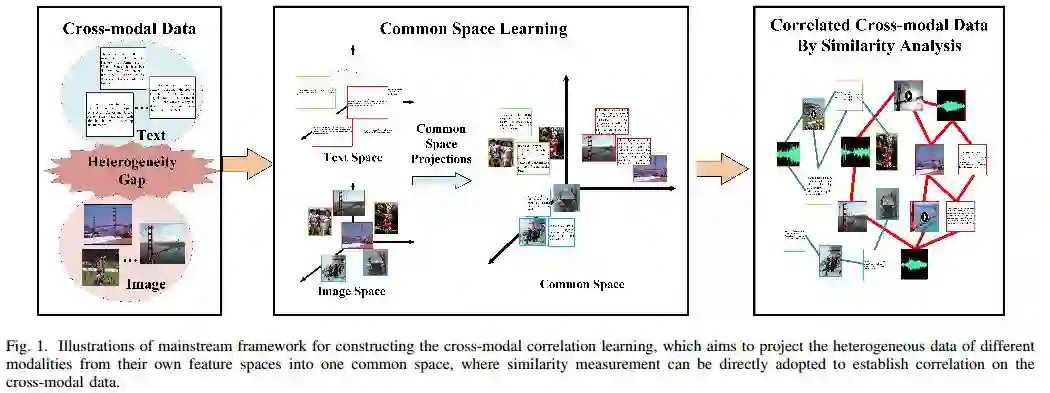
14.CM-GANs: Cross-modal Generative Adversarial Networks for Common Representation Learning(用于常见的表示学习的跨模态生成对抗网络)
作者:Yuxin Peng,Jinwei Qi,Yuxin Yuan
摘要:It is known that the inconsistent distribution and representation of different modalities, such as image and text, cause the heterogeneity gap that makes it challenging to correlate such heterogeneous data. Generative adversarial networks (GANs) have shown its strong ability of modeling data distribution and learning discriminative representation, existing GANs-based works mainly focus on generative problem to generate new data. We have different goal, aim to correlate heterogeneous data, by utilizing the power of GANs to model cross-modal joint distribution. Thus, we propose Cross-modal GANs to learn discriminative common representation for bridging heterogeneity gap. The main contributions are: (1) Cross-modal GANs architecture is proposed to model joint distribution over data of different modalities. The inter-modality and intra-modality correlation can be explored simultaneously in generative and discriminative models. Both of them beat each other to promote cross-modal correlation learning. (2) Cross-modal convolutional autoencoders with weight-sharing constraint are proposed to form generative model. They can not only exploit cross-modal correlation for learning common representation, but also preserve reconstruction information for capturing semantic consistency within each modality. (3) Cross-modal adversarial mechanism is proposed, which utilizes two kinds of discriminative models to simultaneously conduct intra-modality and inter-modality discrimination. They can mutually boost to make common representation more discriminative by adversarial training process. To the best of our knowledge, our proposed CM-GANs approach is the first to utilize GANs to perform cross-modal common representation learning. Experiments are conducted to verify the performance of our proposed approach on cross-modal retrieval paradigm, compared with 10 methods on 3 cross-modal datasets.
期刊:arXiv, 2018年4月27日
网址:
http://www.zhuanzhi.ai/document/221ccb277d72bf88478cd4d45b1375b2
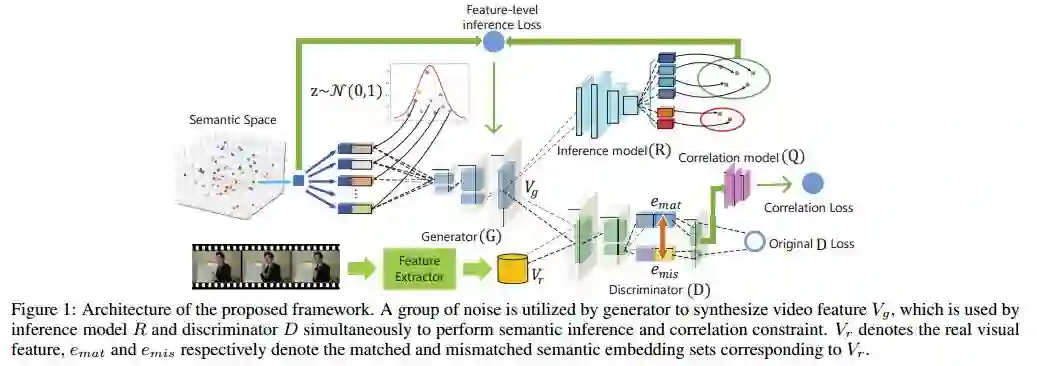
15.Visual Data Synthesis via GAN for Zero-Shot Video Classification(通过GAN进行可视化数据合成实现零样本视频分类)
作者:Chenrui Zhang,Yuxin Peng
accepted by International Joint Conference on Artificial Intelligence (IJCAI) 2018
机构:Peking University
摘要:Zero-Shot Learning (ZSL) in video classification is a promising research direction, which aims to tackle the challenge from explosive growth of video categories. Most existing methods exploit seen-to-unseen correlation via learning a projection between visual and semantic spaces. However, such projection-based paradigms cannot fully utilize the discriminative information implied in data distribution, and commonly suffer from the information degradation issue caused by "heterogeneity gap". In this paper, we propose a visual data synthesis framework via GAN to address these problems. Specifically, both semantic knowledge and visual distribution are leveraged to synthesize video feature of unseen categories, and ZSL can be turned into typical supervised problem with the synthetic features. First, we propose multi-level semantic inference to boost video feature synthesis, which captures the discriminative information implied in joint visual-semantic distribution via feature-level and label-level semantic inference. Second, we propose Matching-aware Mutual Information Correlation to overcome information degradation issue, which captures seen-to-unseen correlation in matched and mismatched visual-semantic pairs by mutual information, providing the zero-shot synthesis procedure with robust guidance signals. Experimental results on four video datasets demonstrate that our approach can improve the zero-shot video classification performance significantly.
期刊:arXiv, 2018年4月26日
网址:
http://www.zhuanzhi.ai/document/4ea8bdde291c58c698466e51a8d24c11
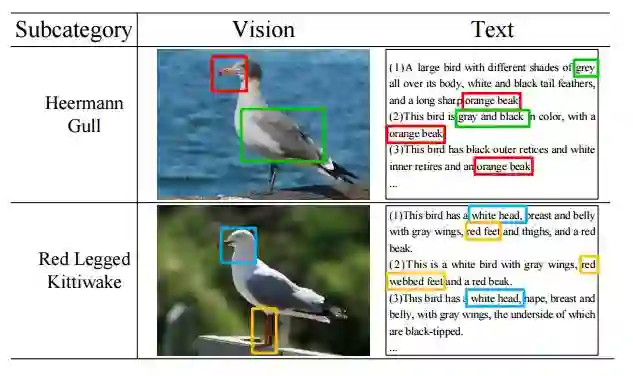
16.Visual-textual Attention Driven Fine-grained Representation Learning(视觉-文本注意力驱动的细粒度的表示学习)
作者:Xiangteng He,Yuxin Peng
机构:Peking University
摘要:Fine-grained image classification is to recognize hundreds of subcategories belonging to the same basic-level category, which is a highly challenging task due to the quite subtle visual distinctions among similar subcategories. Most existing methods generally learn part detectors to discover discriminative regions for better performance. However, not all localized parts are beneficial and indispensable for classification, and the setting for number of part detectors relies heavily on prior knowledge as well as experimental results. As is known to all, when we describe the object of an image into text via natural language, we only focus on the pivotal characteristics, and rarely pay attention to common characteristics as well as the background areas. This is an involuntary transfer from human visual attention to textual attention, which leads to the fact that textual attention tells us how many and which parts are discriminative and significant. So textual attention of natural language descriptions could help us to discover visual attention in image. Inspired by this, we propose a visual-textual attention driven fine-grained representation learning (VTA) approach, and its main contributions are: (1) Fine-grained visual-textual pattern mining devotes to discovering discriminative visual-textual pairwise information for boosting classification through jointly modeling vision and text with generative adversarial networks (GANs), which automatically and adaptively discovers discriminative parts. (2) Visual-textual representation learning jointly combine visual and textual information, which preserves the intra-modality and inter-modality information to generate complementary fine-grained representation, and further improve classification performance. Experiments on the two widely-used datasets demonstrate the effectiveness of our VTA approach, which achieves the best classification accuracy.
期刊:arXiv, 2018年4月26日
网址:
http://www.zhuanzhi.ai/document/7df20921cfd560670e34fe0a35976e7a
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知


