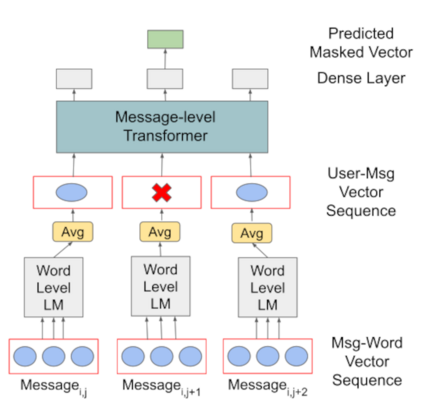
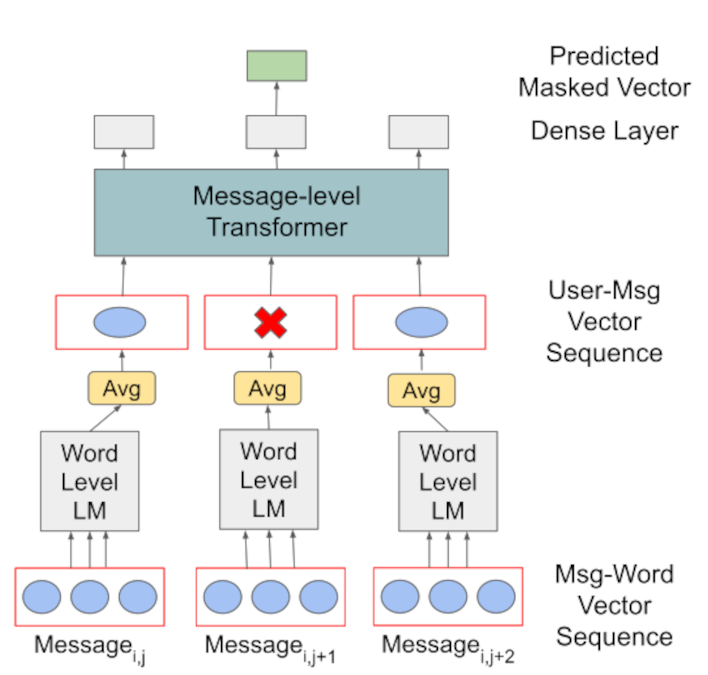
Much of natural language processing is focused on leveraging large capacity language models, typically trained over single messages with a task of predicting one or more tokens. However, modeling human language at higher-levels of context (i.e., sequences of messages) is under-explored. In stance detection and other social media tasks where the goal is to predict an attribute of a message, we have contextual data that is loosely semantically connected by authorship. Here, we introduce Message-Level Transformer (MeLT) -- a hierarchical message-encoder pre-trained over Twitter and applied to the task of stance prediction. We focus on stance prediction as a task benefiting from knowing the context of the message (i.e., the sequence of previous messages). The model is trained using a variant of masked-language modeling; where instead of predicting tokens, it seeks to generate an entire masked (aggregated) message vector via reconstruction loss. We find that applying this pre-trained masked message-level transformer to the downstream task of stance detection achieves F1 performance of 67%.
翻译:自然语言处理的大部分内容都集中在利用大型能力语言模型上,通常在单条电文上经过培训,任务是预测一种或多种符号。然而,在上层背景(即电文序列)模拟人类语言方面,探索不足。在定位探测和其他社交媒体任务中,目标是预测电文的属性,我们掌握的是背景数据,这种数据通过作者机进行松散的语义连接。在这里,我们引入了信息级别变异器(MeLT) -- -- 一种在推特上经过预先培训并应用于定位预测任务的等级级电文变异器(MeLT) -- -- 一种通过了解信息背景(即以往电文序列)而获益于定位预测的任务。该模型经过培训,使用了隐蔽语言模型的变异种;如果不是预测标语,而是试图通过重建损失生成一个完整的遮蔽(隔离)电文矢量。我们发现,将这一经过预先培训的隐蔽电文级变异器用于下游定位探测任务,实现了67%的F1性表现。