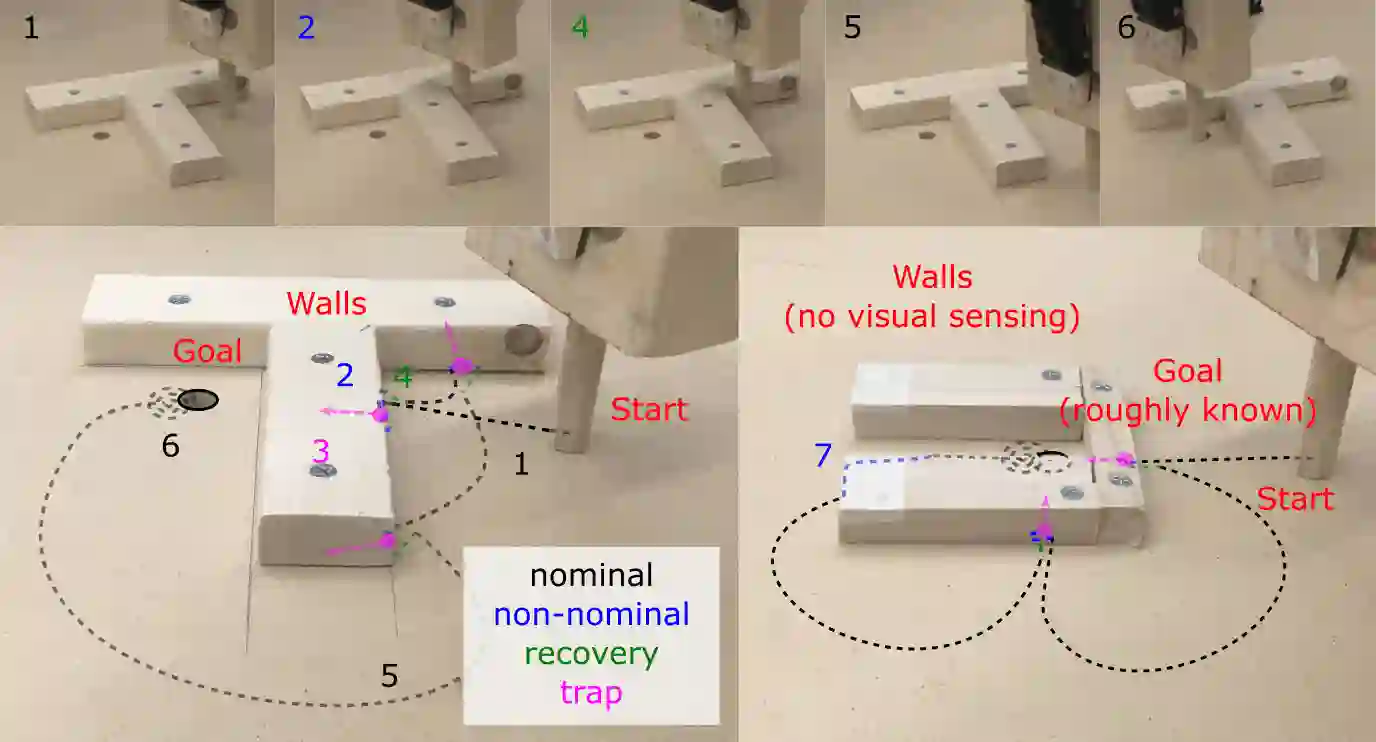
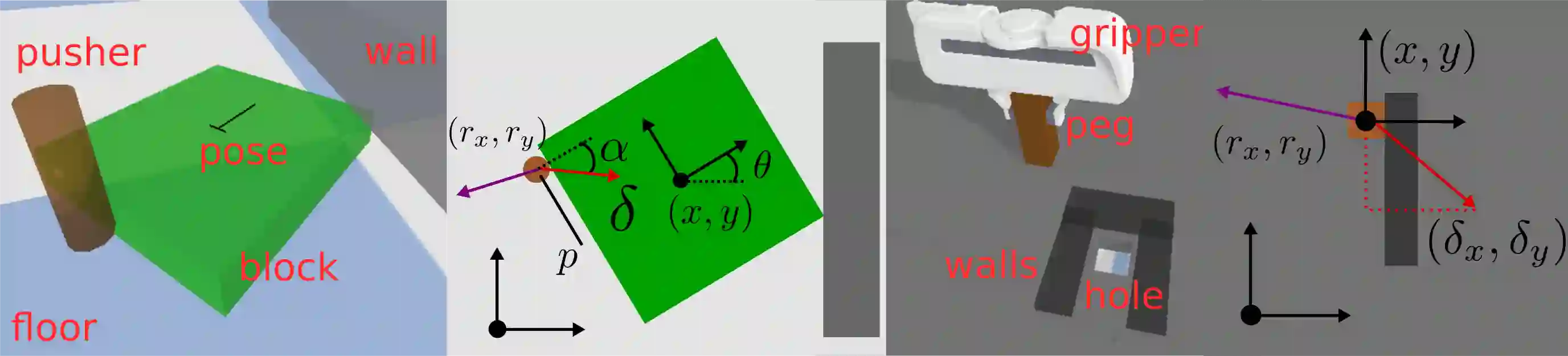
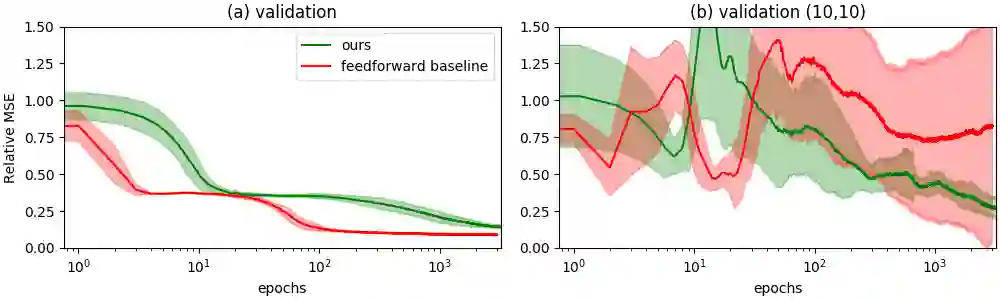
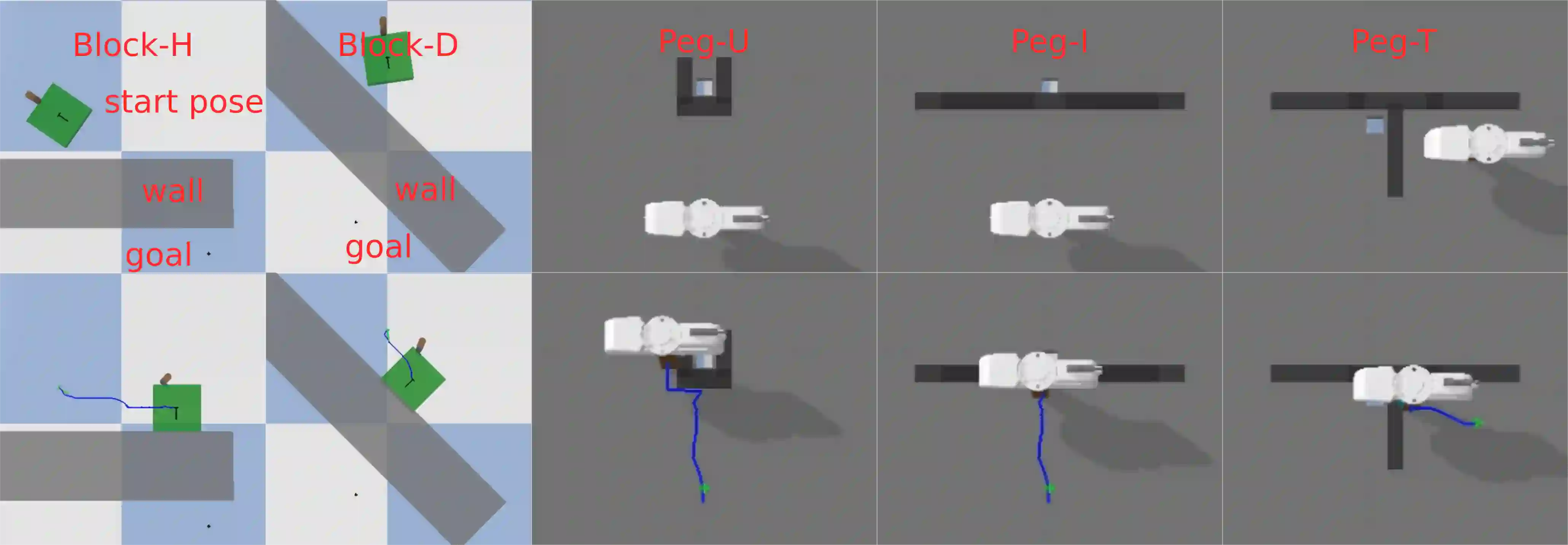
We propose an approach to online model adaptation and control in the challenging case of hybrid and discontinuous dynamics where actions may lead to difficult-to-escape "trap" states, under a given controller. We first learn dynamics for a system without traps from a randomly collected training set (since we do not know what traps will be encountered online). These "nominal" dynamics allow us to perform tasks in scenarios where the dynamics matches the training data, but when unexpected traps arise in execution, we must find a way to adapt our dynamics and control strategy and continue attempting the task. Our approach, Trap-Aware Model Predictive Control (TAMPC), is a two-level hierarchical control algorithm that reasons about traps and non-nominal dynamics to decide between goal-seeking and recovery policies. An important requirement of our method is the ability to recognize nominal dynamics even when we encounter data that is out-of-distribution w.r.t the training data. We achieve this by learning a representation for dynamics that exploits invariance in the nominal environment, thus allowing better generalization. We evaluate our method on simulated planar pushing and peg-in-hole as well as real robot peg-in-hole problems against adaptive control, reinforcement learning, trap-handling baselines, where traps arise due to unexpected obstacles that we only observe through contact. Our results show that our method outperforms the baselines on difficult tasks, and is comparable to prior trap-handling methods on easier tasks.
翻译:在具有挑战性的混合和不连续动态中,我们提出一种在线模式适应和控制方法,在这种具有挑战性的混合和不连续动态情况下,行动可能导致难以逃逸的“陷阱”状态,置于给定控制者之下。我们首先从随机收集的培训组合中学习一个没有陷阱的系统的动态(因为我们不知道在网上会遇到什么陷阱)。这些“名义”动态使我们能够在动态与培训数据相匹配但在执行过程中出现意外陷阱的情况下执行任务。我们必须找到一种方法,以适应我们的动态和控制战略,并继续尝试这项任务。我们的方法,Trap-Aware模型预测控制(TAMPC)是一个两级的等级控制算法,其原因是要从一个没有陷阱和非标识的动态的角度来决定追求目标与恢复政策之间的陷阱。我们方法的一个重要要求是,即使我们遇到动态与培训数据相匹配,但当我们在执行过程中出现意外的陷阱陷阱陷阱时,我们也必须找到一种表达方式,在名义环境中利用不易变的动态,从而得以更好地概括化。我们的方法是,我们用来模拟规划推进和非标识的系统动态的方法,我们只能通过前的升级式的升级式的升级的定位方法来学习我们之前的升级式的升级式的升级式的升级式的升级式的升级式的连接方法,作为机器人的升级式的升级式的连接方法,从而显示真正的升级式的升级式的升级式的升级式的升级式的升级式的升级式的升级式的连接方法,从而显示,从而显示真正的升级式的升级式的升级式的升级式的升级式的升级式的方法,作为真实的升级式的升级式的升级式的方法,作为真实的升级式的升级式的升级式的升级式的升级式的升级式的升级式的升级式的升级式的升级式的升级式的升级式的方法。