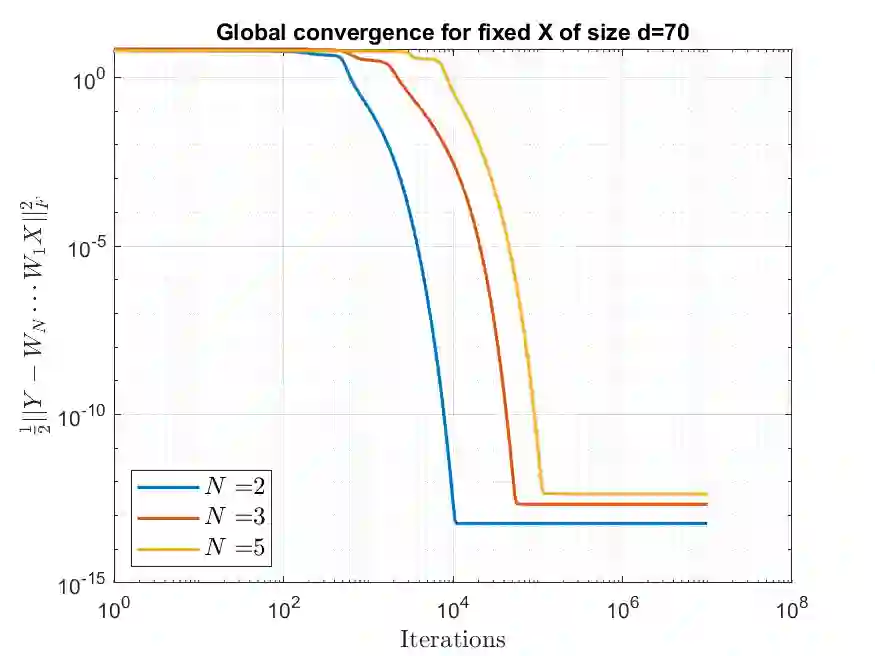
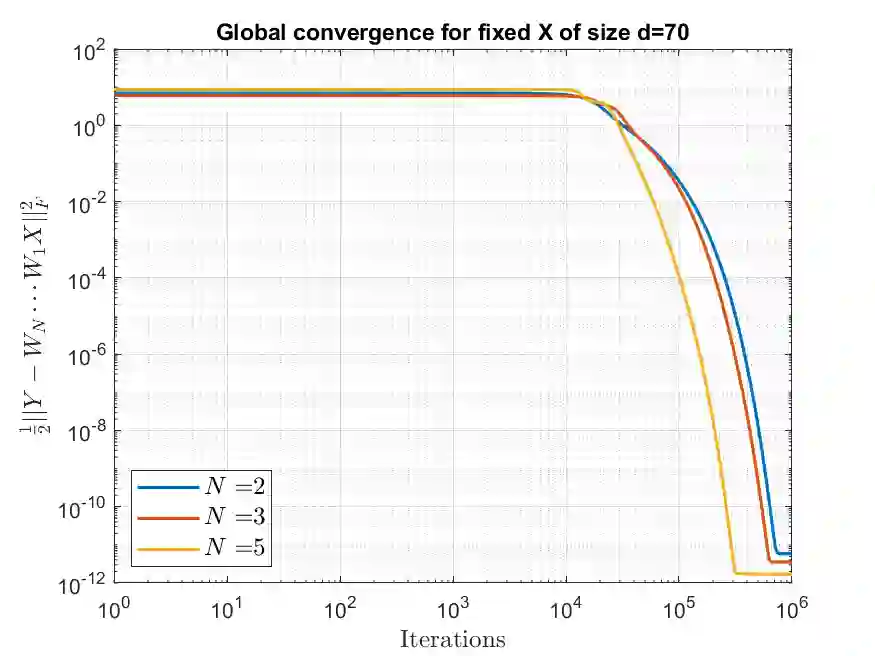
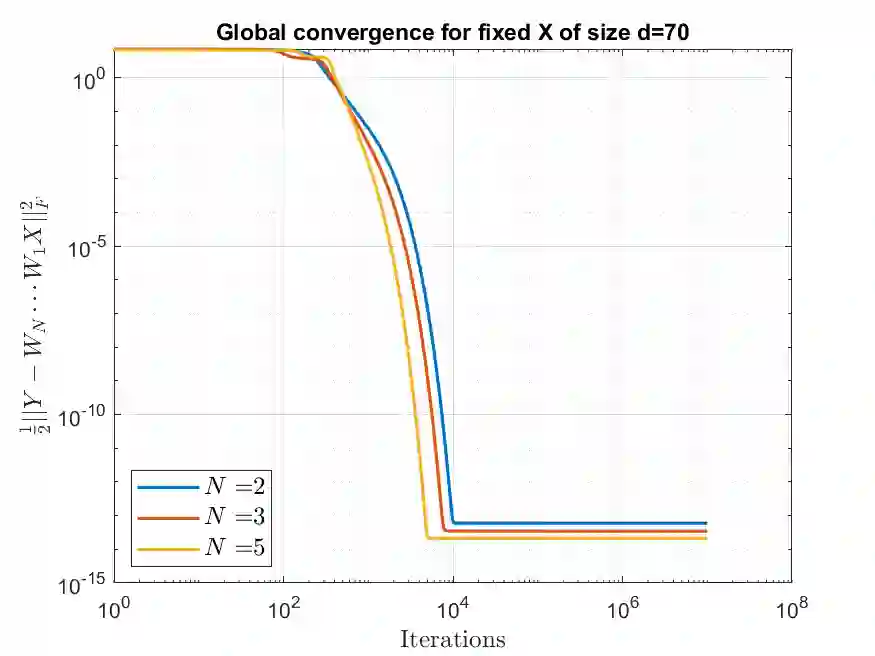
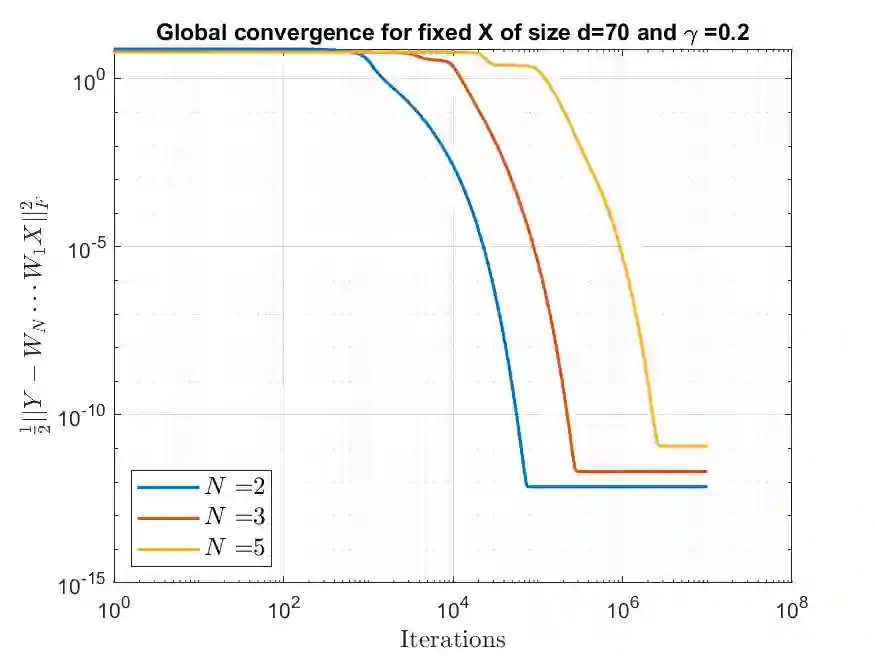
We study the convergence properties of gradient descent for training deep linear neural networks, i.e., deep matrix factorizations, by extending a previous analysis for the related gradient flow. We show that under suitable conditions on the step sizes gradient descent converges to a critical point of the loss function, i.e., the square loss in this article. Furthermore, we demonstrate that for almost all initializations gradient descent converges to a global minimum in the case of two layers. In the case of three or more layers we show that gradient descent converges to a global minimum on the manifold matrices of some fixed rank, where the rank cannot be determined a priori.
翻译:我们通过扩大先前对相关梯度流的分析,研究梯度下降的趋同特性,以培训深线神经网络,即深矩阵因子化。我们表明,在适当条件下,梯度下降会汇合到损失功能的临界点,即本条中的平方损失。此外,我们证明,几乎所有初始化的梯度下降在两层情况下都汇合到全球最低点。在三层或更多层的情况下,我们表明,梯度下降会汇合到某些固定等级的多元矩阵的全球最低点,在这种情况下,等级无法确定。