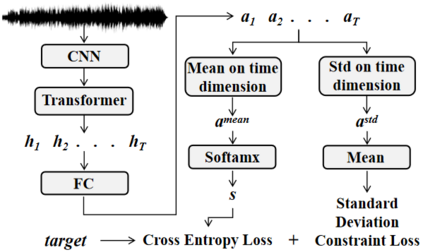
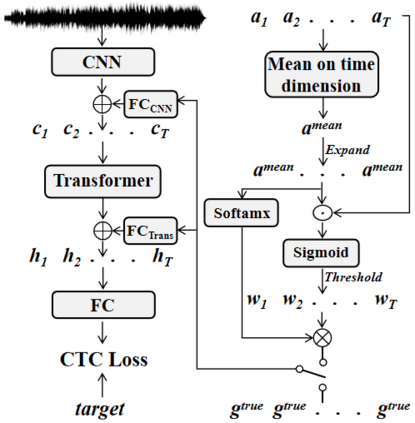
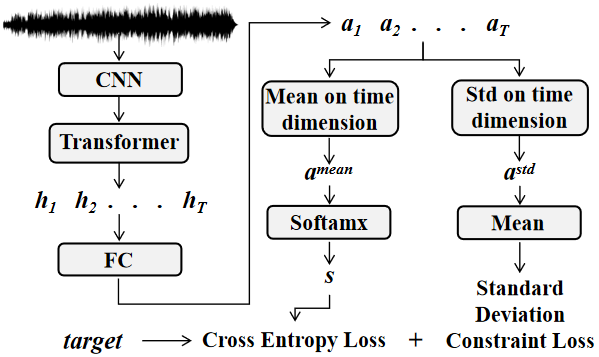
Recently, self-supervised pre-training has gained success in automatic speech recognition (ASR). However, considering the difference between speech accents in real scenarios, how to identify accents and use accent features to improve ASR is still challenging. In this paper, we employ the self-supervised pre-training method for both accent identification and accented speech recognition tasks. For the former task, a standard deviation constraint loss (SDC-loss) based end-to-end (E2E) architecture is proposed to identify accents under the same language. As for accented speech recognition task, we design an accent-dependent ASR system, which can utilize additional accent input features. Furthermore, we propose a frame-level accent feature, which is extracted based on the proposed accent identification model and can be dynamically adjusted. We pre-train our models using 960 hours unlabeled LibriSpeech dataset and fine-tune them on AESRC2020 speech dataset. The experimental results show that our proposed accent-dependent ASR system is significantly ahead of the AESRC2020 baseline and achieves $6.5\%$ relative word error rate (WER) reduction compared with our accent-independent ASR system.
翻译:最近,在自动语音识别(ASR)方面,自我监督的预培训在自动语音识别(ASR)方面取得了成功。然而,考虑到真实情景中语音口音的差异,如何识别口音和使用口音特征来改进ASR仍是一个挑战性的问题。在本文中,我们采用自我监督的训练前方法,既进行口音识别,又进行口音识别。对于前一项任务,建议采用基于端对端的基于端对端标准差限制损失(SDC-损失)结构来识别同一语言下的口音。关于重音识别任务,我们设计了一个依赖口音的ASR系统,该系统可以使用额外的口音输入功能。此外,我们提议采用基于拟议口音识别模式的基调一级口音特征特征特征特征特征,并可以动态调整。我们先用960小时未标的LibriSpeech数据集对模型进行设计,然后用AESRC2020语音数据集对其进行微调。实验结果表明,我们提议的口音依赖的ASR系统大大领先于AESRC2020基线,并实现了6.5美元相对字性错误率。