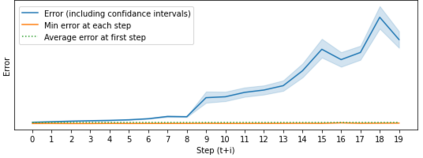
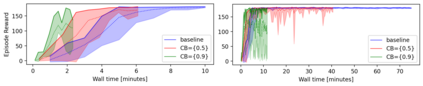
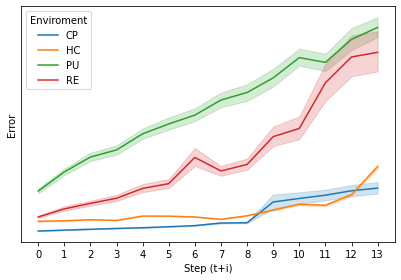
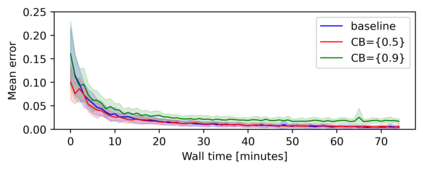
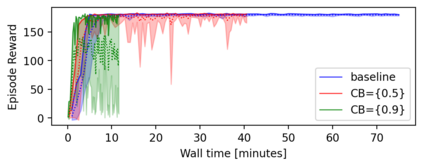
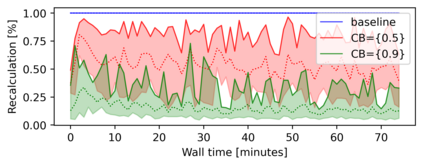
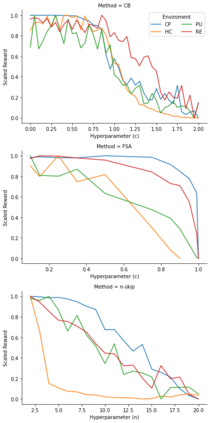
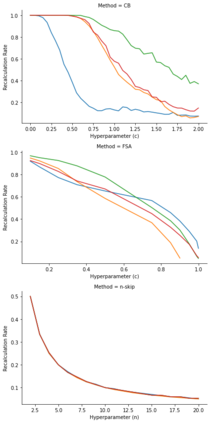
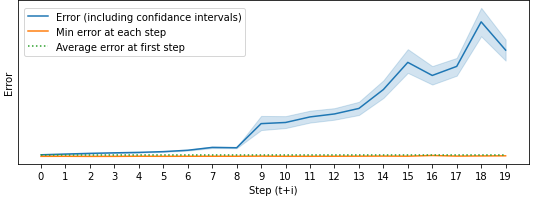
Model based reinforcement learning (MBRL) uses an imperfect model of the world to imagine trajectories of future states and plan the best actions to maximize a reward function. These trajectories are imperfect and MBRL attempts to overcome this by relying on model predictive control (MPC) to continuously re-imagine trajectories from scratch. Such re-generation of imagined trajectories carries the major computational cost and increasing complexity in tasks with longer receding horizon. This paper aims to investigate how far in the future the imagined trajectories can be relied upon while still maintaining acceptable reward. Firstly, an error analysis is presented for systematic skipping recalculations for varying number of consecutive steps.% in several challenging benchmark control tasks. Secondly, we propose two methods offering when to trust and act upon imagined trajectories, looking at recent errors with respect to expectations, or comparing the confidence in an action imagined against its execution. Thirdly, we evaluate the effects of acting upon imagination while training the model of the world. Results show that acting upon imagination can reduce calculations by at least 20% and up to 80%, depending on the environment, while retaining acceptable reward.
翻译:基于模型的强化学习(MBRL)使用一种不完善的世界模型来想象未来国家的轨迹,并规划最佳行动以最大限度地发挥奖励功能。这些轨迹是不完善的,而MBRL试图通过依靠模型预测控制(MPC)从零开始不断重新想象轨迹来克服这一点。这种想象的轨迹的再生成将带来重大的计算成本和在较长的后退地平线任务中日益复杂。本文件旨在调查未来在保持可接受的奖励的同时,能够依赖想象的轨迹有多远。首先,对连续步骤数量不等的系统跳过重新计算提出了错误分析。在几项具有挑战性的基准控制任务中,%。第二,我们提出了两种方法,在信任和根据想象的轨迹采取行动时提供两种方法,看看有关期望的最近错误,或者比较对执行中想象的行动的信心。第三,我们评估在培训世界模型时对想象力的影响。结果显示,根据想象力采取行动可以将计算减少至少20 %和高达80 %,这取决于环境,同时保留可接受的报酬。