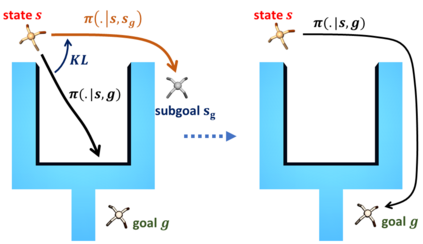
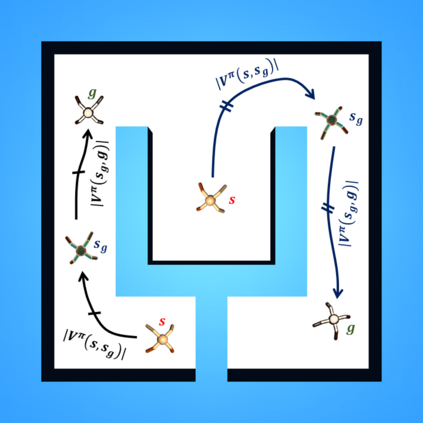
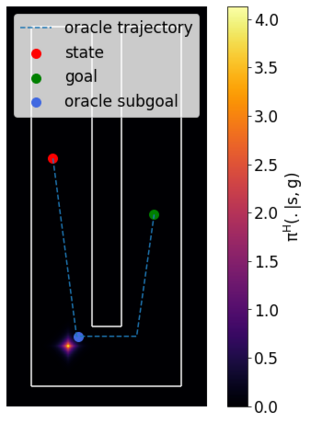
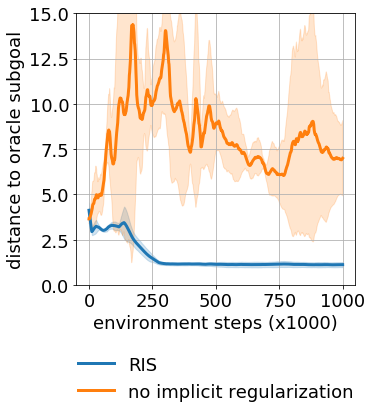
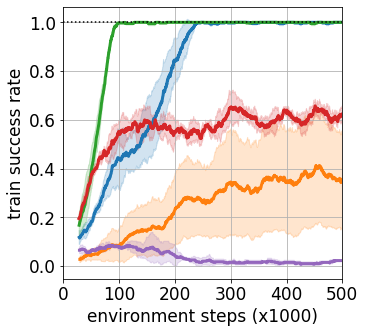
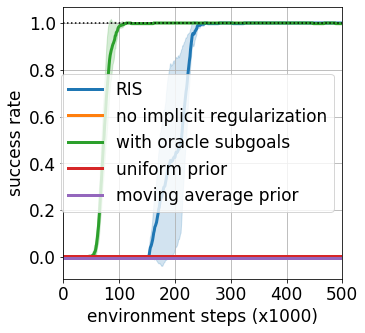
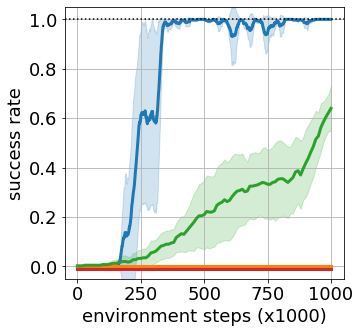
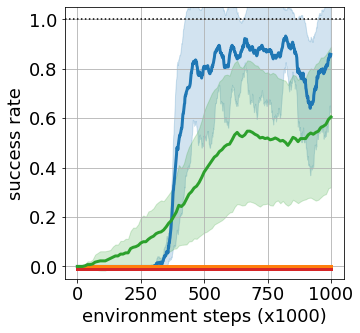
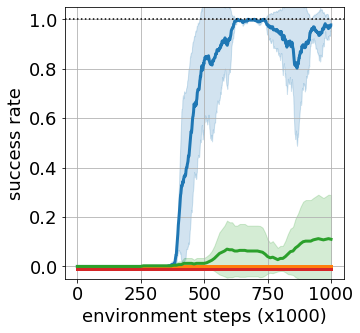
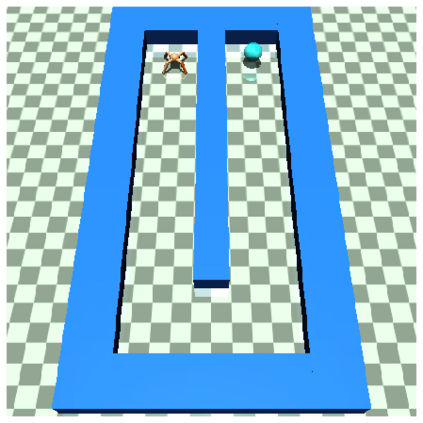
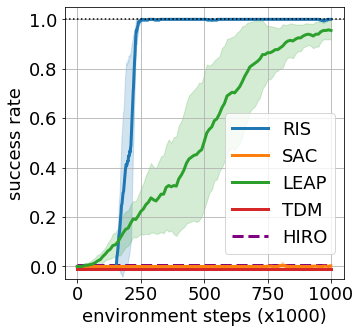
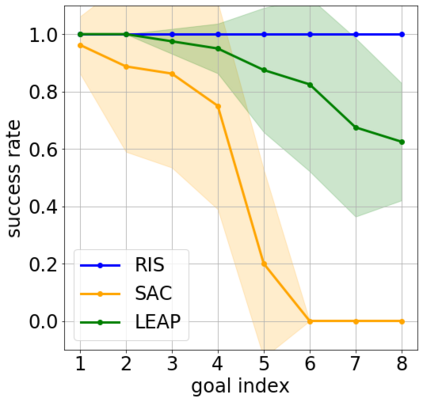
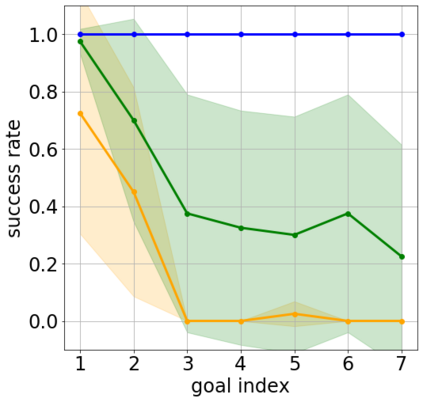
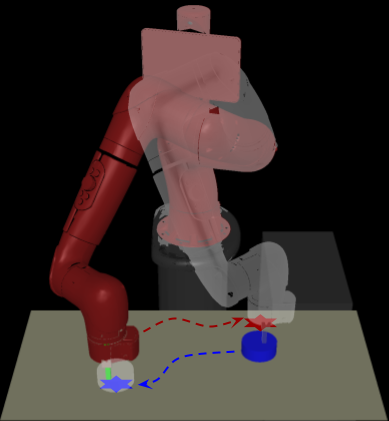
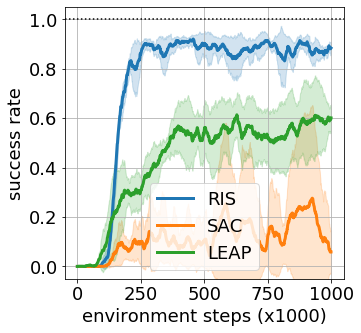
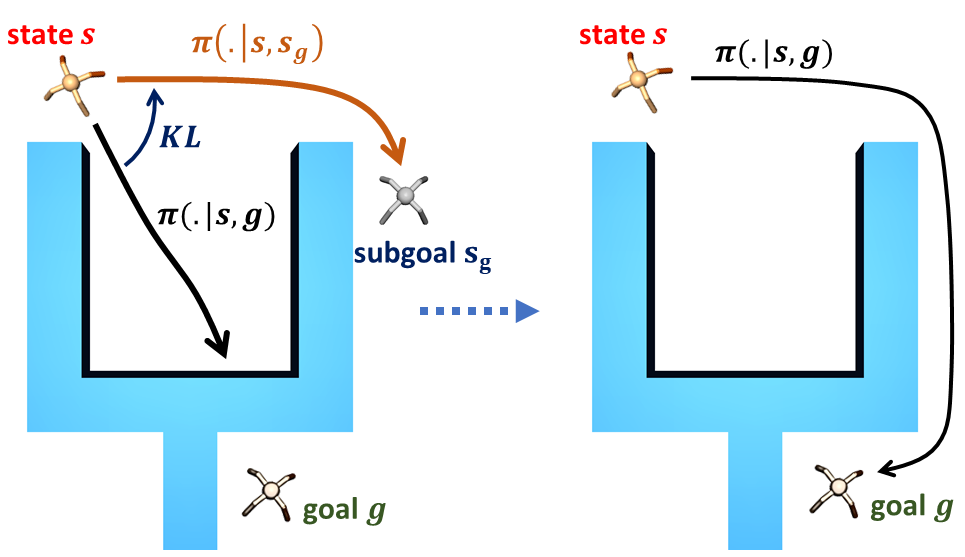
Goal-conditioned reinforcement learning endows an agent with a large variety of skills, but it often struggles to solve tasks that require more temporally extended reasoning. In this work, we propose to incorporate imagined subgoals into policy learning to facilitate learning of complex tasks. Imagined subgoals are predicted by a separate high-level policy, which is trained simultaneously with the policy and its critic. This high-level policy predicts intermediate states halfway to the goal using the value function as a reachability metric. We don't require the policy to reach these subgoals explicitly. Instead, we use them to define a prior policy, and incorporate this prior into a KL-constrained policy iteration scheme to speed up and regularize learning. Imagined subgoals are used during policy learning, but not during test time, where we only apply the learned policy. We evaluate our approach on complex robotic navigation and manipulation tasks and show that it outperforms existing methods by a large margin.
翻译:以强化为条件的强化学习让一个具有多种技能的代理机构具备了丰富的技能,但是它常常在努力解决需要更长时间推理的任务。 在这项工作中,我们提议将想象中的次级目标纳入政策学习,以促进学习复杂任务。想象中的次级目标由单独的高级政策预测,该高级政策与政策及其批评者同时培训。这一高级政策预测以价值函数作为可达性衡量标准,向目标的中点过渡。我们并不要求政策明确达到这些次级目标。相反,我们用它们来定义先前的政策,并将它纳入一个受KL制约的政策循环计划,以加快和规范学习。想象中的次级目标在政策学习期间使用,而不是在测试期间使用,我们只是在那里应用了所学的政策。我们评估了我们复杂的机器人导航和操作任务的方法,并表明它比现有方法大幅度要长。