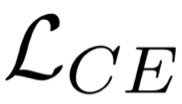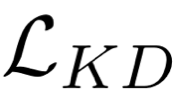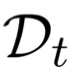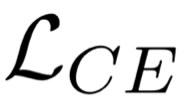Large pre-trained language models such as BERT have shown their effectiveness in various natural language processing tasks. However, the huge parameter size makes them difficult to be deployed in real-time applications that require quick inference with limited resources. Existing methods compress BERT into small models while such compression is task-independent, i.e., the same compressed BERT for all different downstream tasks. Motivated by the necessity and benefits of task-oriented BERT compression, we propose a novel compression method, AdaBERT, that leverages differentiable Neural Architecture Search to automatically compress BERT into task-adaptive small models for specific tasks. We incorporate a task-oriented knowledge distillation loss to provide search hints and an efficiency-aware loss as search constraints, which enables a good trade-off between efficiency and effectiveness for task-adaptive BERT compression. We evaluate AdaBERT on several NLP tasks, and the results demonstrate that those task-adaptive compressed models are 12.7x to 29.3x faster than BERT in inference time and 11.5x to 17.0x smaller in terms of parameter size, while comparable performance is maintained.
翻译:在各种自然语言处理任务中,如BERT等经过预先培训的大型语言模型显示了其有效性。然而,由于参数大小巨大,难以在需要利用有限资源快速推断的实时应用中应用。现有的方法将BERT压缩成小型模型,而这种压缩是任务独立的,即对所有不同的下游任务而言,同样的压缩BERT。我们根据任务导向的BERT压缩工作的必要性和好处,提出了一种新的压缩方法AdaBERT, 利用可区分的神经结构搜索来自动压缩BERT进入任务适应的小模型。我们纳入了以任务为导向的知识蒸馏损失,以提供搜索提示和效率意识损失作为搜索限制,从而在任务适应的BERT压缩工作效率和效果之间实现良好的交换。我们评估了几项任务导向的压缩任务,结果显示这些任务适应性压缩模型比BERT在延长时间中的速度要快12.7x至29.3x,在参数大小方面比BERT要快11.5x小至17.0x。