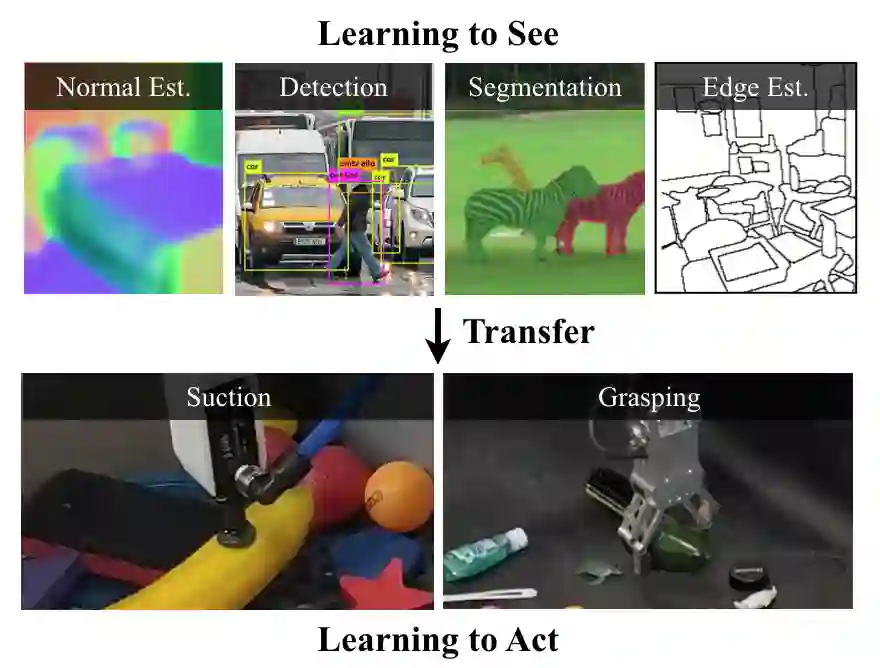
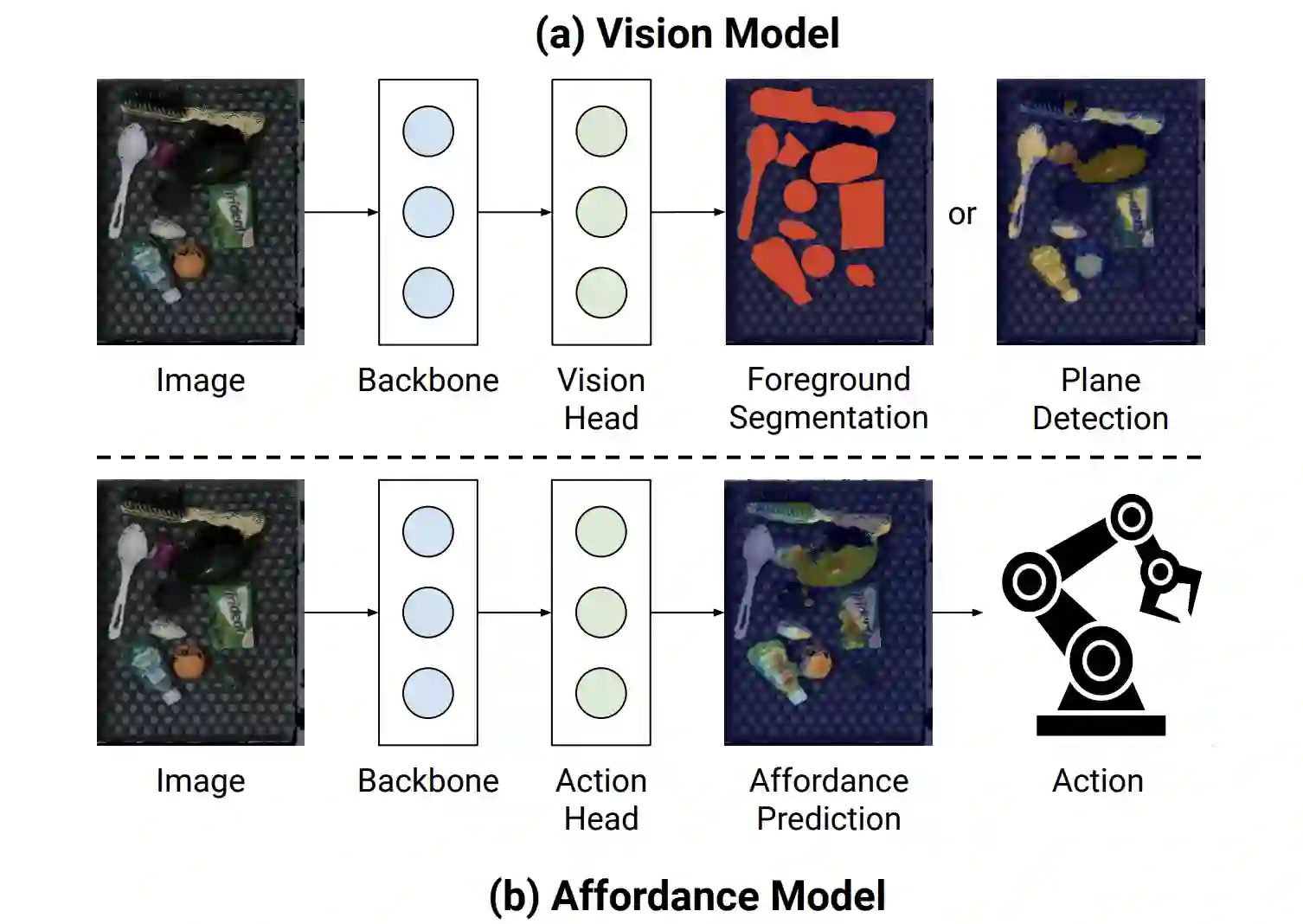
Does having visual priors (e.g. the ability to detect objects) facilitate learning to perform vision-based manipulation (e.g. picking up objects)? We study this problem under the framework of transfer learning, where the model is first trained on a passive vision task, and adapted to perform an active manipulation task. We find that pre-training on vision tasks significantly improves generalization and sample efficiency for learning to manipulate objects. However, realizing these gains requires careful selection of which parts of the model to transfer. Our key insight is that outputs of standard vision models highly correlate with affordance maps commonly used in manipulation. Therefore, we explore directly transferring model parameters from vision networks to affordance prediction networks, and show that this can result in successful zero-shot adaptation, where a robot can pick up certain objects with zero robotic experience. With just a small amount of robotic experience, we can further fine-tune the affordance model to achieve better results. With just 10 minutes of suction experience or 1 hour of grasping experience, our method achieves ~80% success rate at picking up novel objects.
翻译:具有视觉前科(例如,探测天体的能力)是否有助于学习进行基于视觉的操纵(例如,采集天体)?我们在转让学习的框架内研究这一问题,模型首先经过被动的视觉任务培训,并适应于积极的操纵任务。我们发现,关于视觉任务的培训前大大改进了一般化和抽样效率,以便学习操控天体。然而,实现这些收益需要仔细选择模式的哪些部分来转移。我们的关键见解是,标准视觉模型的输出与通常用于操作的廉价地图高度相关。因此,我们探索将模型参数从视觉网络直接转移,以支付预测网络的费用,并表明这可以导致成功的零点适应,使机器人能够拿起某些没有机器人经验的物体。只要有少量机器人经验,我们就能够进一步微调价格模型,以取得更好的结果。只要抽取10分钟的经验或1小时的掌握经验,我们的方法在取新物体时就达到~80%的成功率。