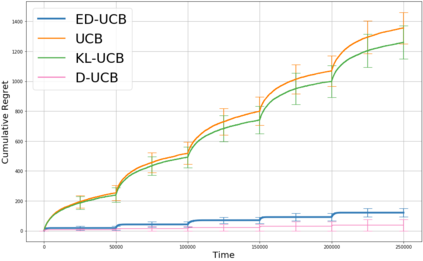
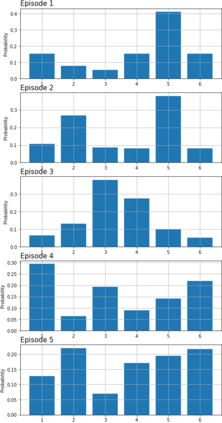
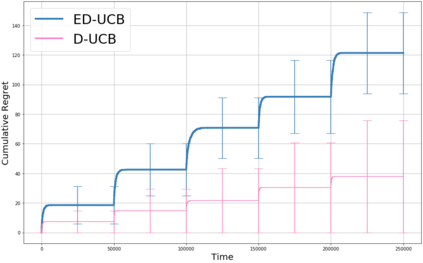
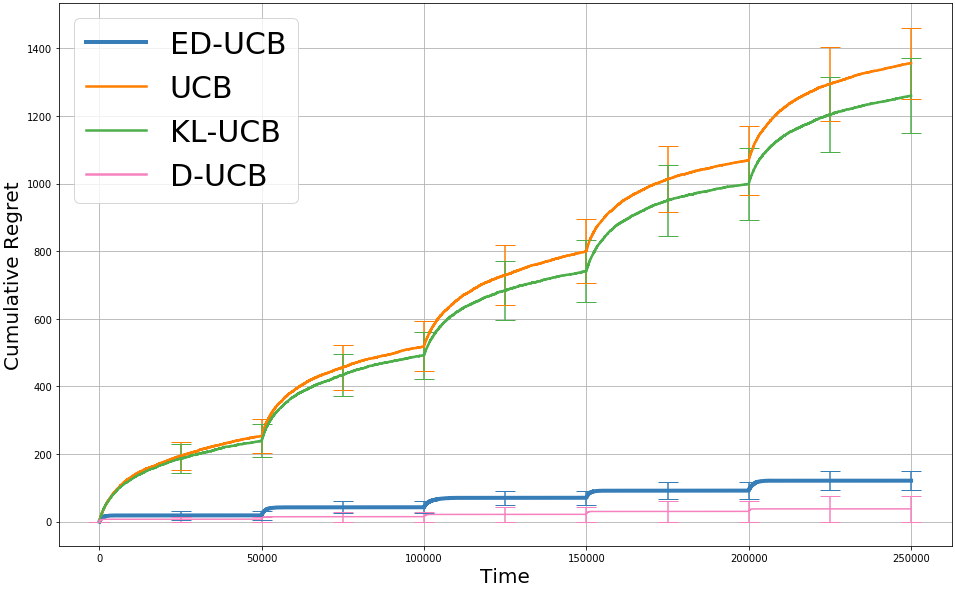
We study a version of the contextual bandit problem where an agent is given soft control of a node in a graph-structured environment through a set of stochastic expert policies. The agent interacts with the environment over episodes, with each episode having different context distributions; this results in the `best expert' changing across episodes. Our goal is to develop an agent that tracks the best expert over episodes. We introduce the Empirical Divergence-based UCB (ED-UCB) algorithm in this setting where the agent does not have any knowledge of the expert policies or changes in context distributions. With mild assumptions, we show that bootstrapping from $\tilde{O}(N\log(NT^2\sqrt{E}))$ samples results in a regret of $\tilde{O}(E(N+1) + \frac{N\sqrt{E}}{T^2})$. If the expert policies are known to the agent a priori, then we can improve the regret to $\tilde{O}(EN)$ without requiring any bootstrapping. Our analysis also tightens pre-existing logarithmic regret bounds to a problem-dependent constant in the non-episodic setting when expert policies are known. We finally empirically validate our findings through simulations.
翻译:我们研究背景土匪问题的版本, 代理商通过一套随机专家政策,在图形结构环境中对节点进行软控制。 代理商与环境互动, 每件事件都有不同的上下文分布; 这导致“ 最佳专家” 随事件变化。 我们的目标是开发一个代理商, 跟踪最优秀的专家。 我们在此环境下引入基于 UCB (ED- UCB) (ED- UCB) 的算法, 代理商对专家政策或上下文分布的变化一无所知。 稍有假设, 我们显示, 美元( N\ tilde{ O} (N\\\\ t\\\\\\\\\\\\\\\\\\\ sqrt{E}) 对环境的采样导致$\ tillde{O} (E( N+1) +\ frac{N\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\