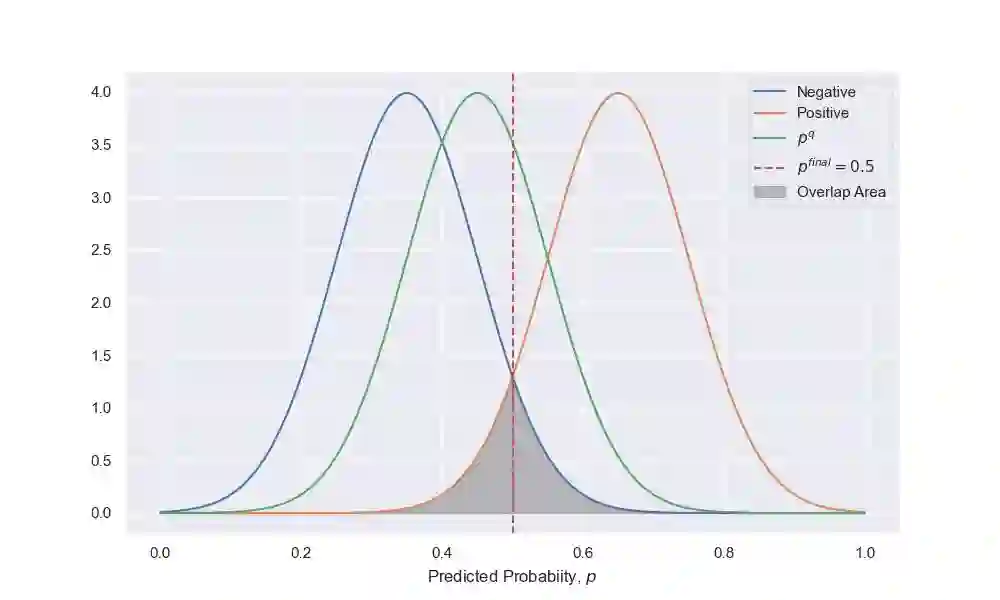
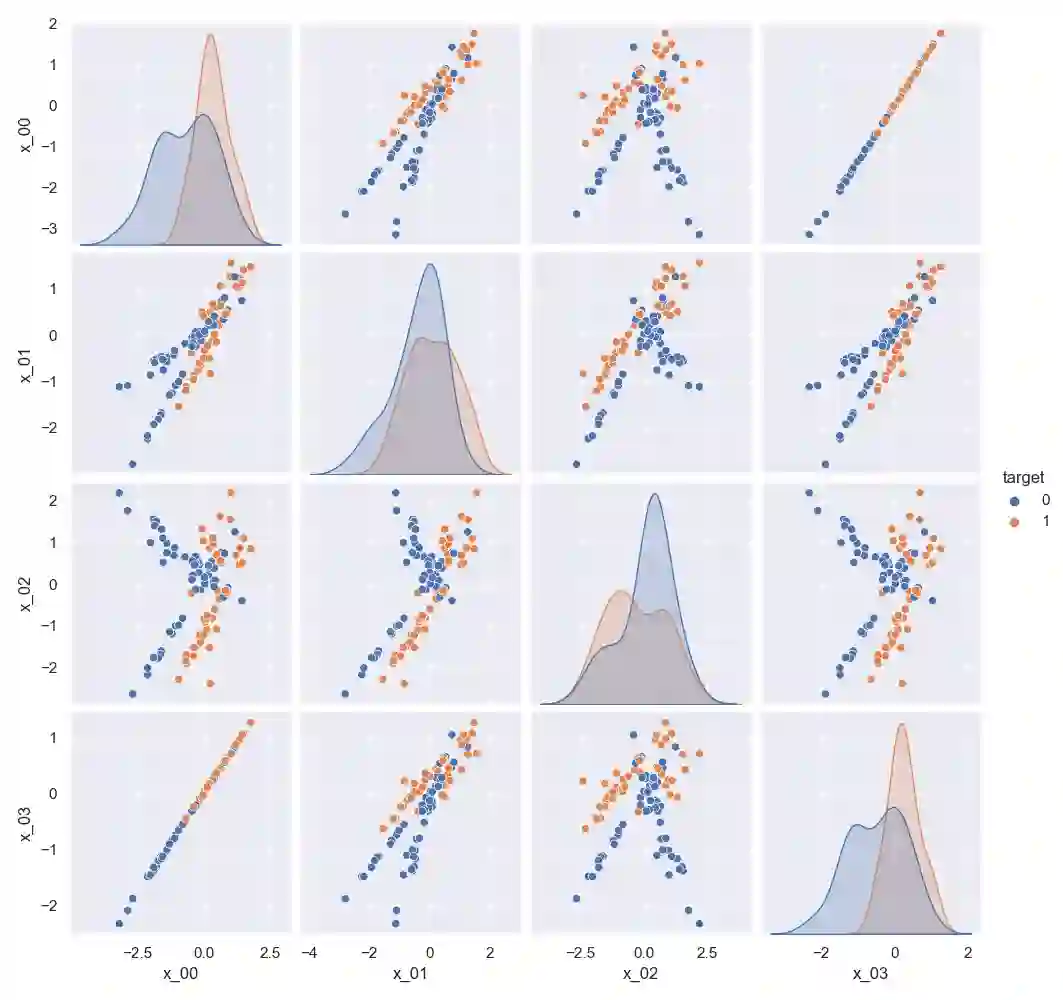
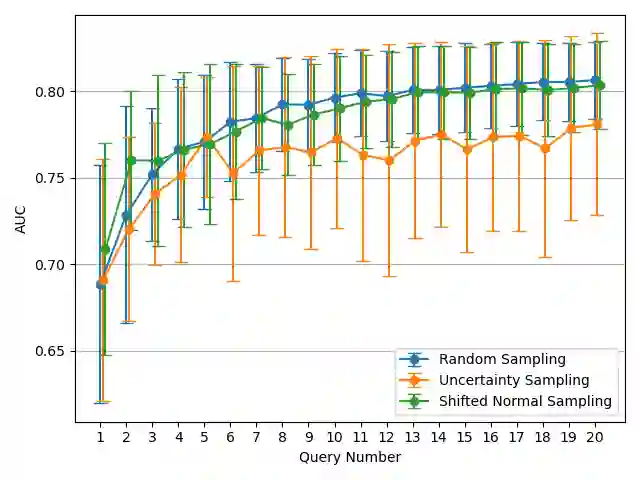
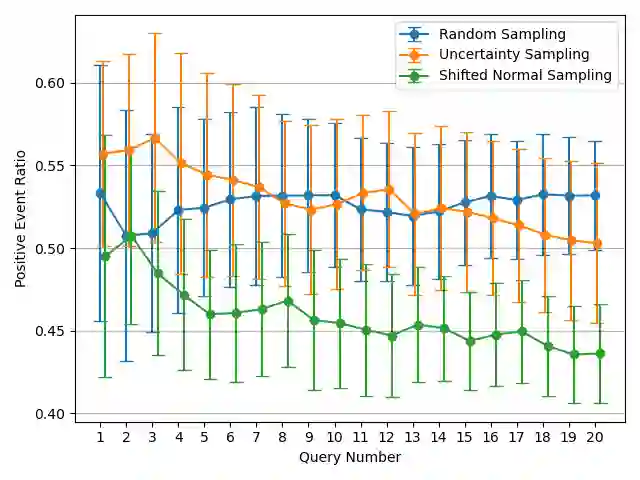
Active learning is a learning strategy whereby the machine learning algorithm actively identifies and labels data points to optimize its learning. This strategy is particularly effective in domains where an abundance of unlabeled data exists, but the cost of labeling these data points is prohibitively expensive. In this paper, we consider cases of binary classification, where acquiring a positive instance incurs a significantly higher cost compared to that of negative instances. For example, in the financial industry, such as in money-lending businesses, a defaulted loan constitutes a positive event leading to substantial financial loss. To address this issue, we propose a shifted normal distribution sampling function that samples from a wider range than typical uncertainty sampling. Our simulation underscores that our proposed sampling function limits both noisy and positive label selection, delivering between 20% and 32% improved cost efficiency over different test datasets.
翻译:暂无翻译