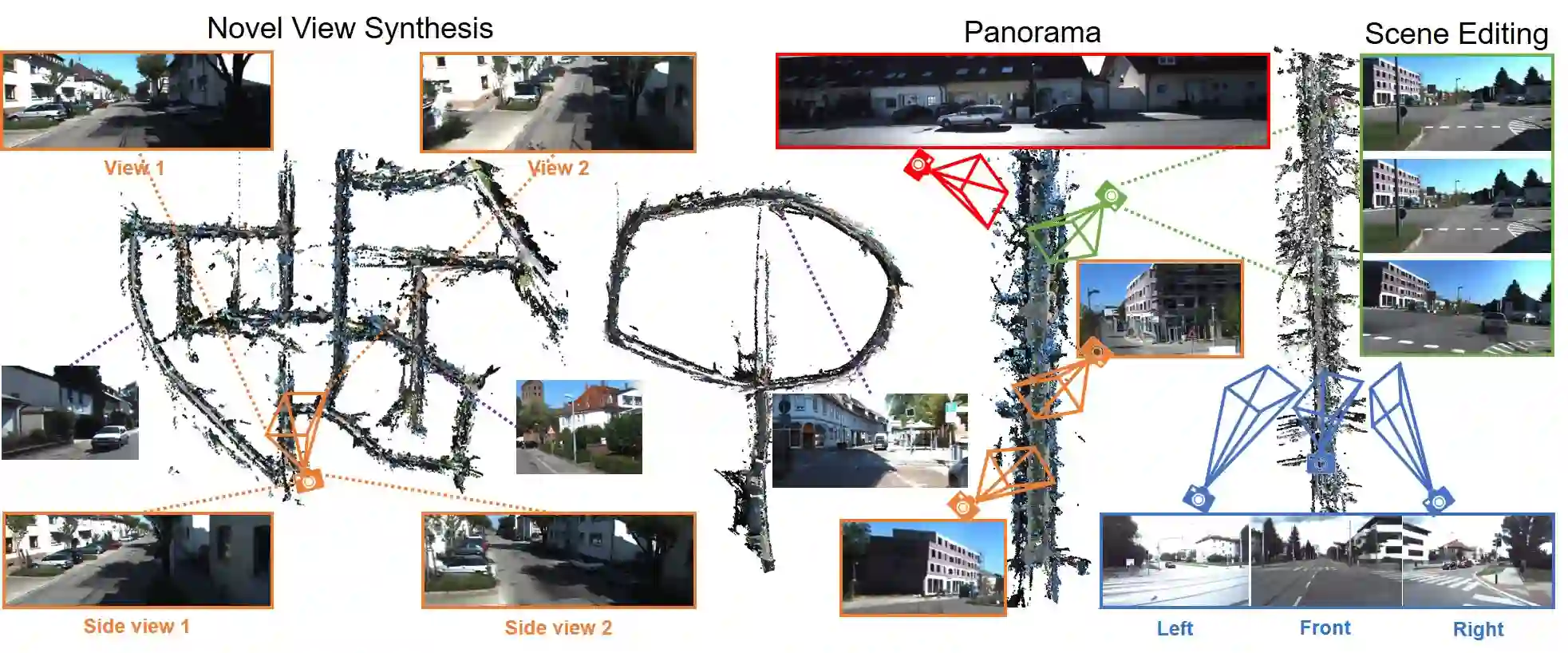
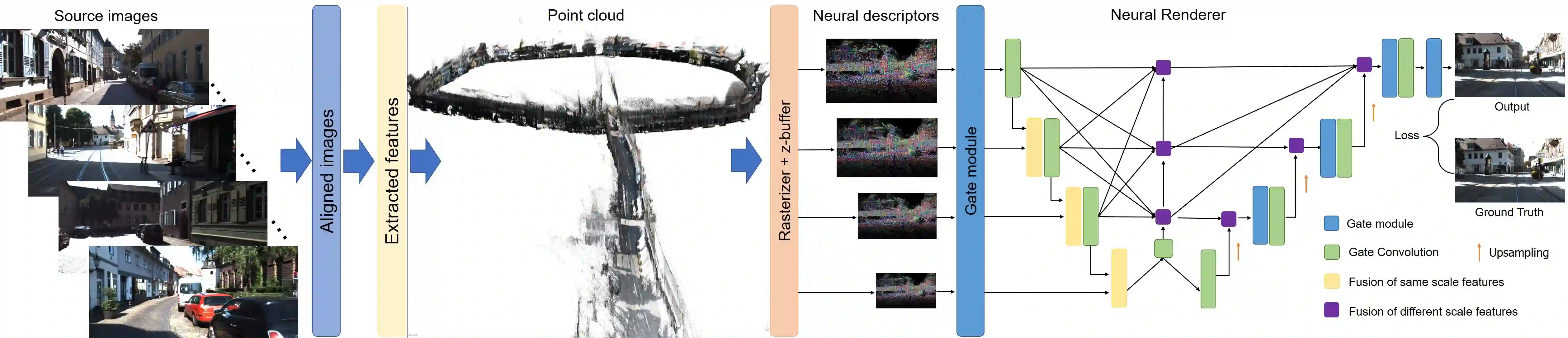
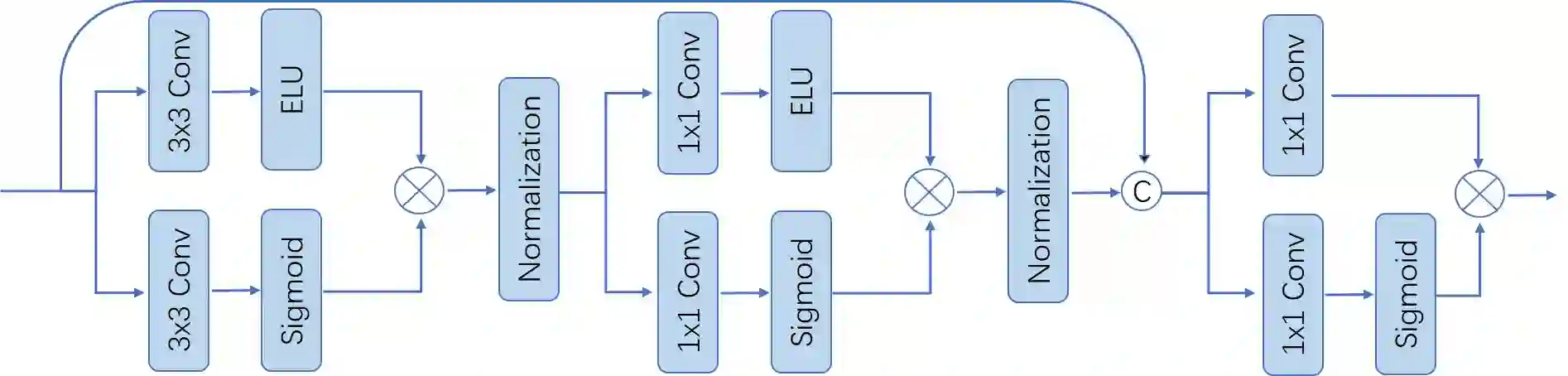
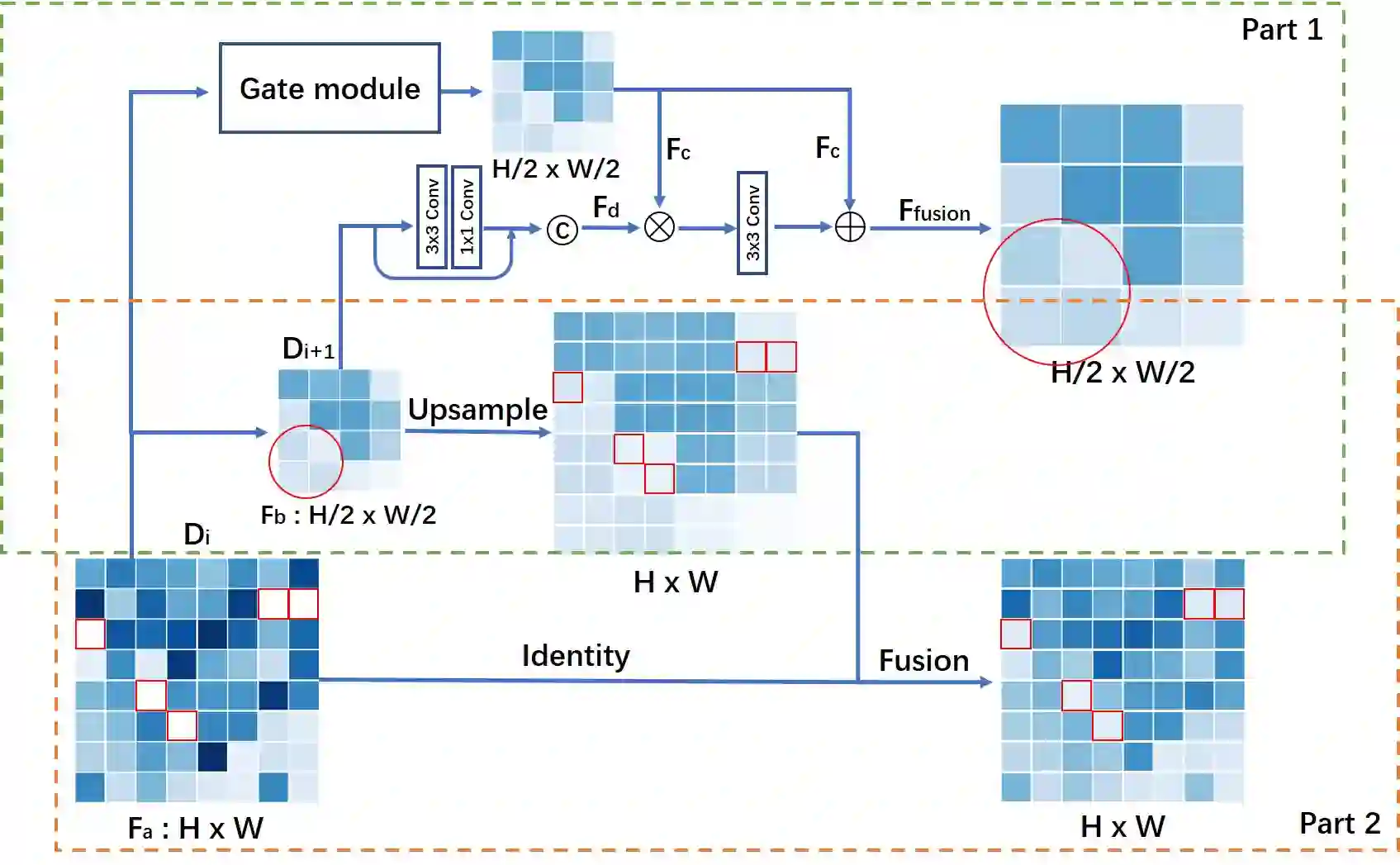
Synthesizing free-view photo-realistic images is an important task in multimedia. With the development of advanced driver assistance systems~(ADAS) and their applications in autonomous vehicles, experimenting with different scenarios becomes a challenge. Although the photo-realistic street scenes can be synthesized by image-to-image translation methods, which cannot produce coherent scenes due to the lack of 3D information. In this paper, a large-scale neural rendering method is proposed to synthesize the autonomous driving scene~(READ), which makes it possible to synthesize large-scale driving scenarios on a PC through a variety of sampling schemes. In order to represent driving scenarios, we propose an {\omega} rendering network to learn neural descriptors from sparse point clouds. Our model can not only synthesize realistic driving scenes but also stitch and edit driving scenes. Experiments show that our model performs well in large-scale driving scenarios.
翻译:集成自由视觉照片现实图像是多媒体中的一项重要任务。 随着先进的驱动器协助系统~(ADAS)的开发及其在自主车辆中的应用,实验不同情景将成为一个挑战。虽然照片现实的街道场景可以通过图像到图像翻译方法合成,但由于缺乏3D信息,这些场景无法产生一致的场景。在本文中,提议了一种大型神经转换方法来合成自动驾驶场~(READ),这样就可以通过多种抽样方案在个人电脑上合成大型驾驶场景。为了代表驾驶场景,我们提议建立一个覆盖网络,从稀薄云中学习线条纹。我们的模型不仅可以合成现实的驾驶场景,还可以缝合和编辑驾驶场景。实验显示,我们的模型在大型驾驶场景中表现良好。