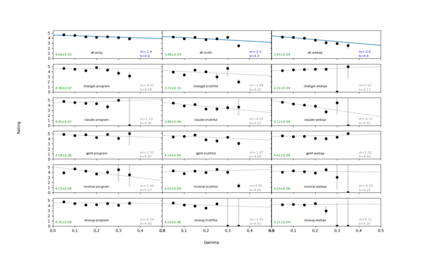
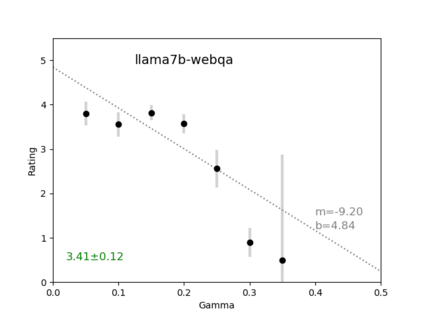
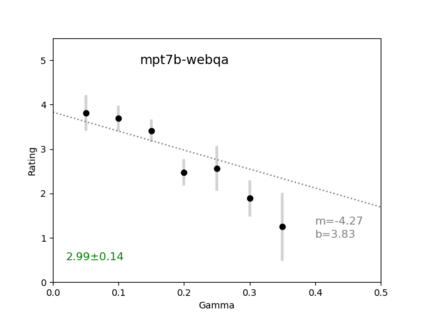
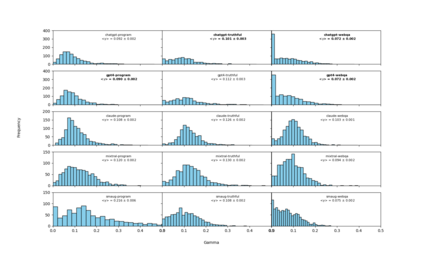
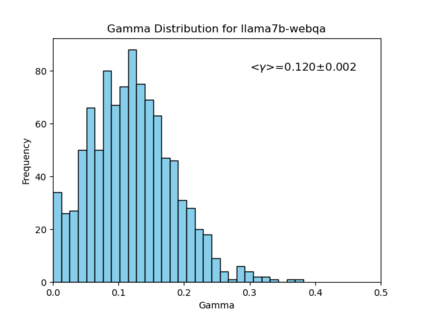
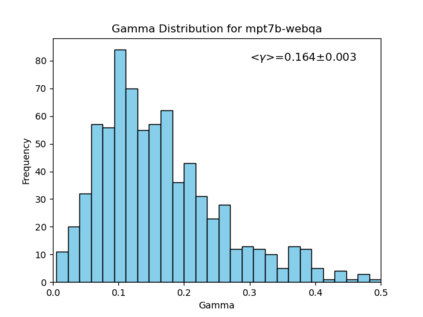
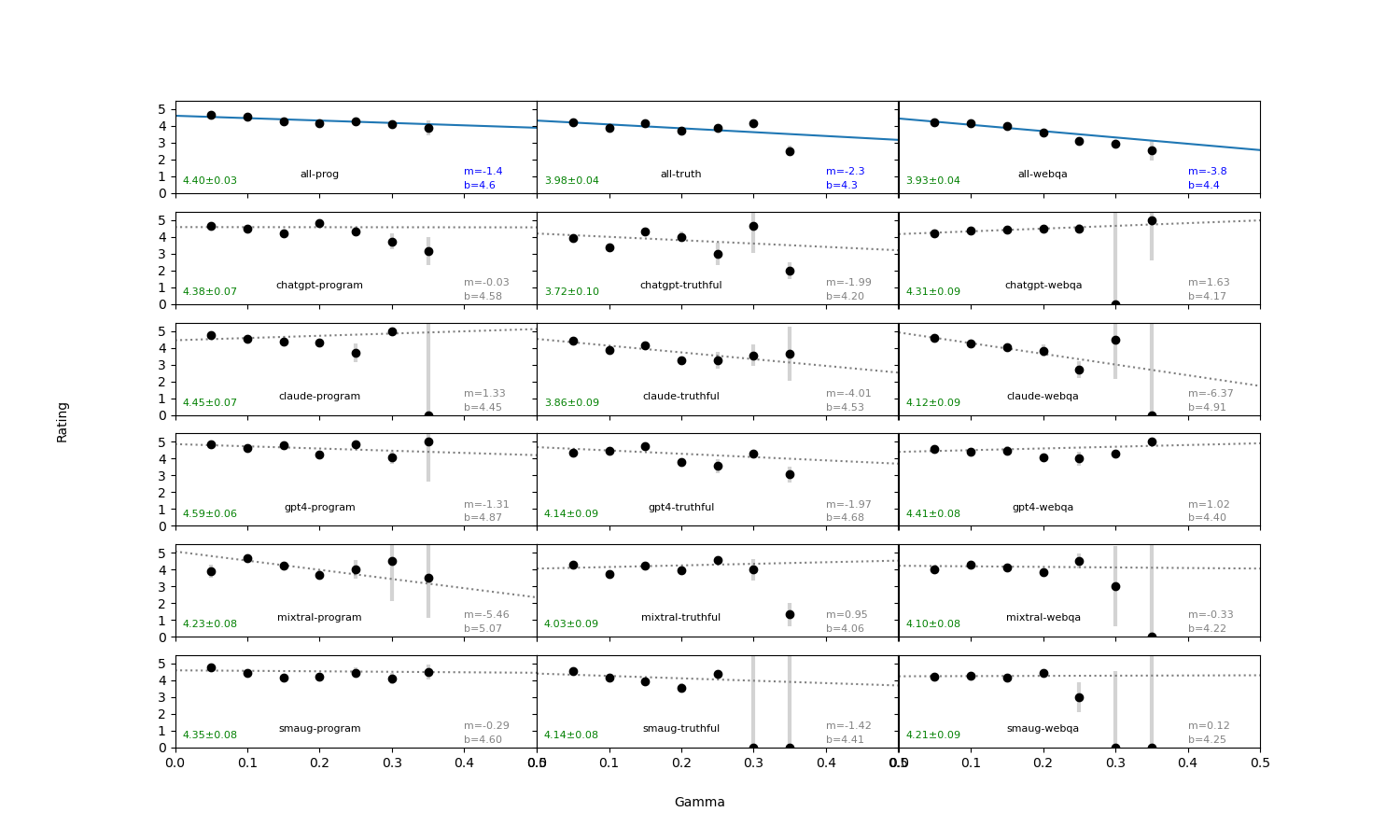
We introduce an intuitive method to test the robustness (stability and explainability) of any black-box LLM in real-time, based upon the local deviation from harmoniticity, denoted as $\gamma$. To the best of our knowledge this is the first completely model-agnostic and unsupervised method of measuring the robustness of any given response from an LLM, based upon the model itself conforming to a purely mathematical standard. We conduct human annotation experiments to show the positive correlation of $\gamma$ with false or misleading answers, and demonstrate that following the gradient of $\gamma$ in stochastic gradient ascent efficiently exposes adversarial prompts. Measuring $\gamma$ across thousands of queries in popular LLMs (GPT-4, ChatGPT, Claude-2.1, Mixtral-8x7B, Smaug-72B, Llama2-7B, and MPT-7B) allows us to estimate the liklihood of wrong or hallucinatory answers automatically and quantitatively rank the reliability of these models in various objective domains (Web QA, TruthfulQA, and Programming QA). Across all models and domains tested, human ratings confirm that $\gamma \to 0$ indicates trustworthiness, and the low-$\gamma$ leaders among these models are GPT-4, ChatGPT, and Smaug-72B.
翻译:暂无翻译