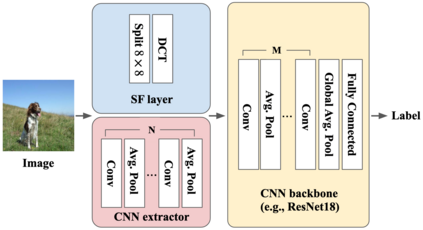
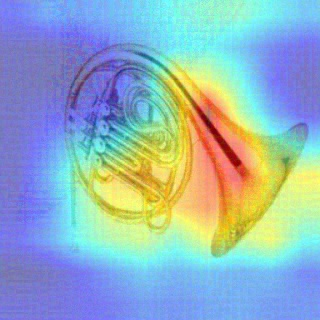
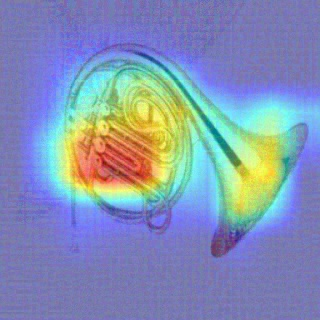
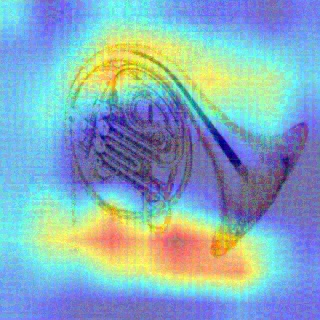
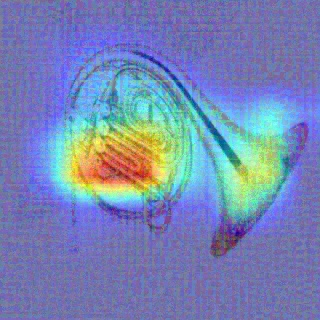
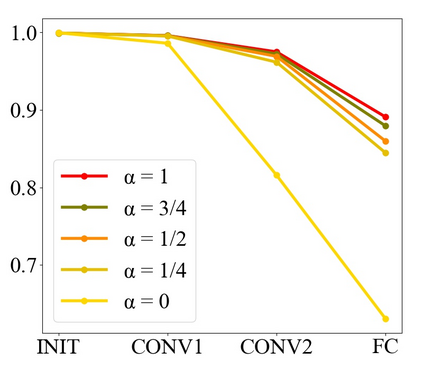
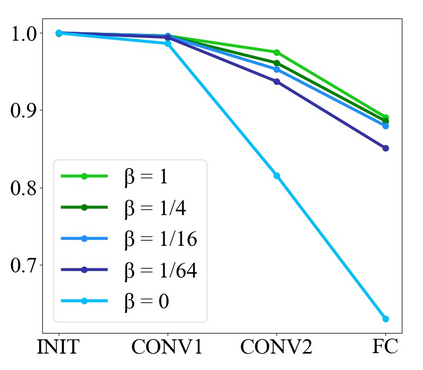
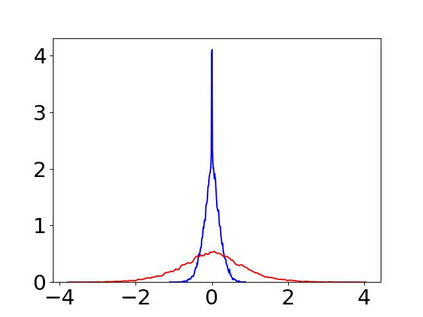
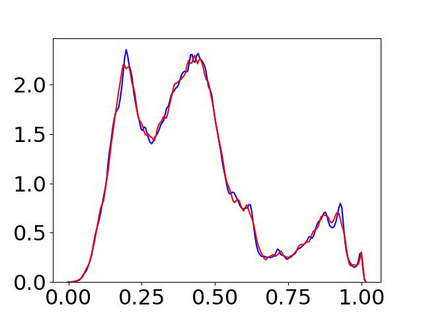
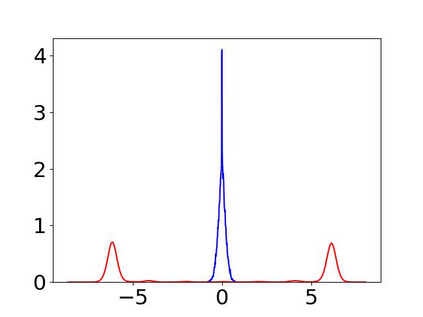
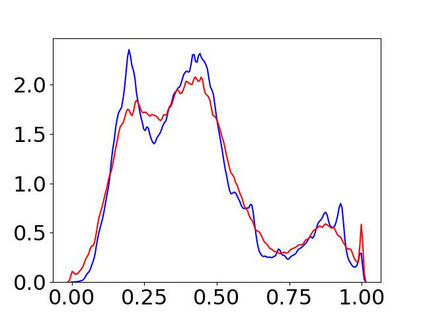
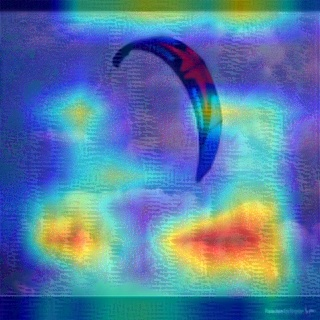
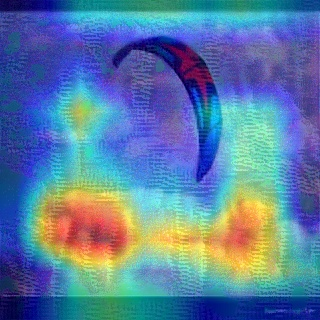
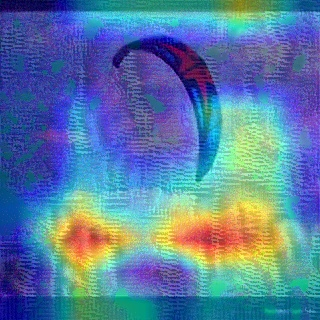
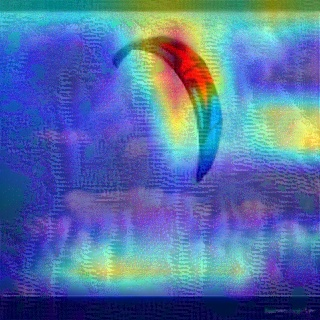
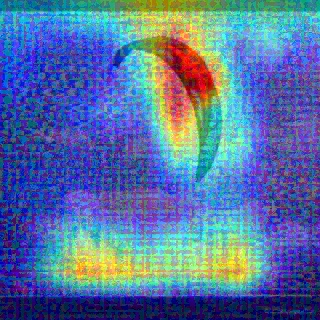
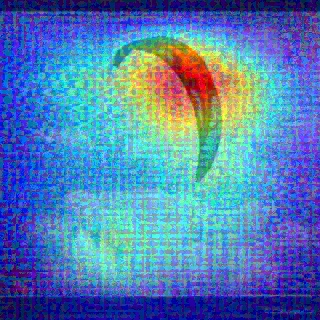
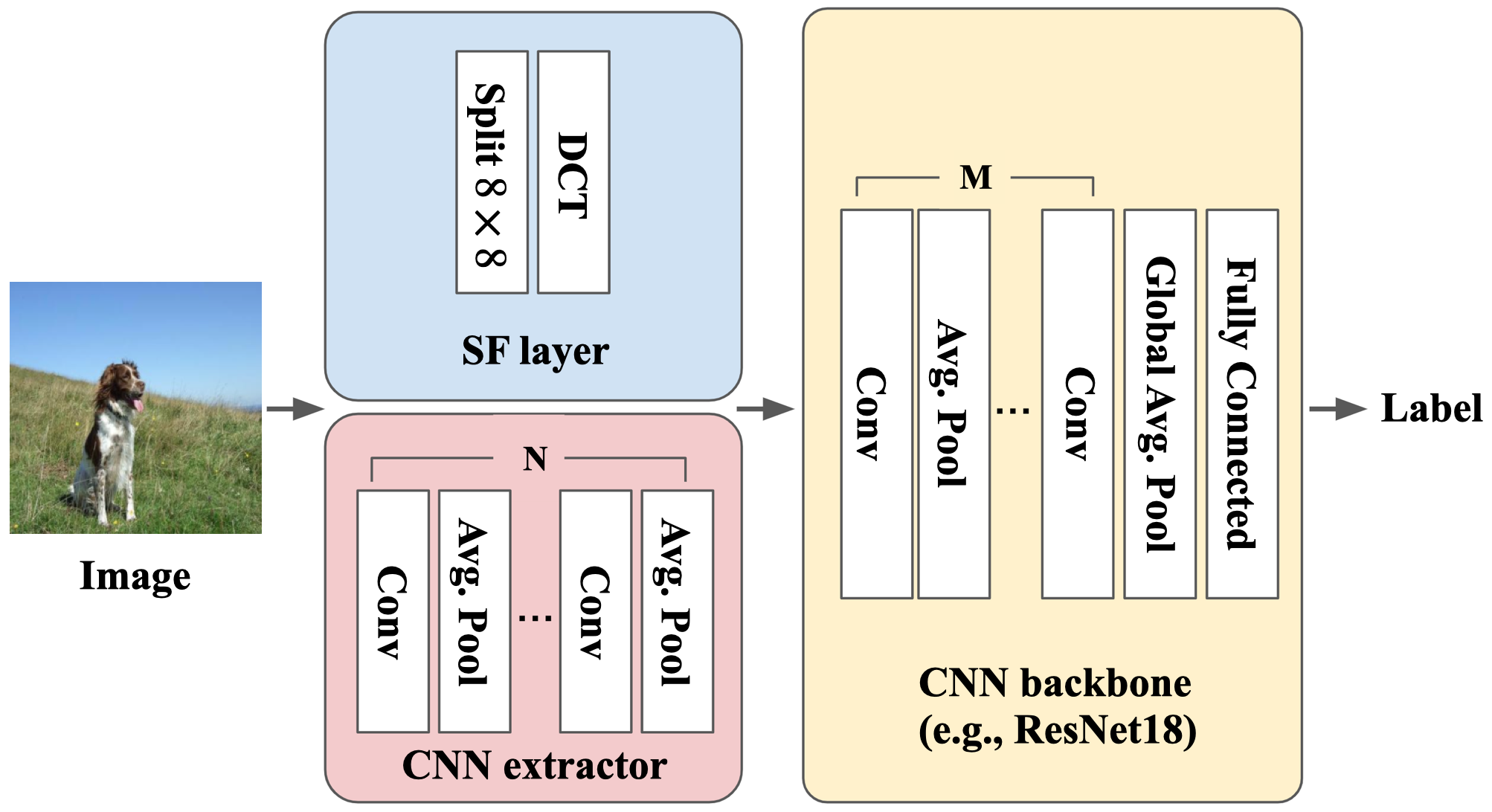
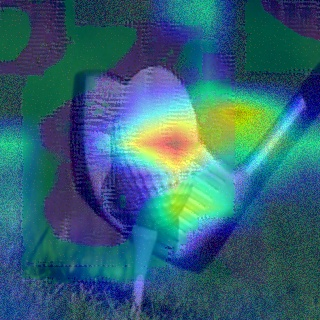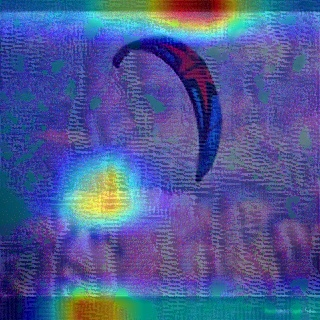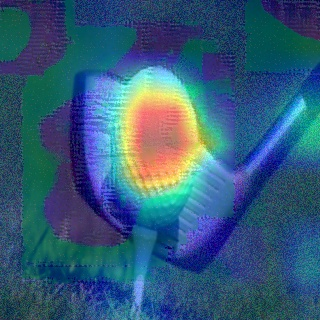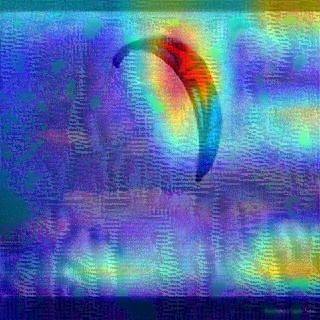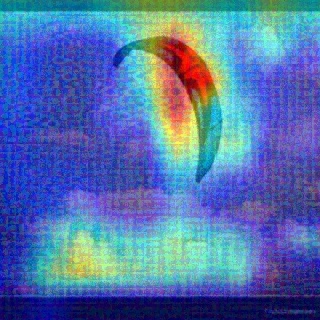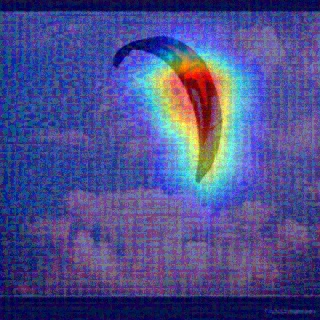Convolutional Neural Networks (CNNs) have dominated the majority of computer vision tasks. However, CNNs' vulnerability to adversarial attacks has raised concerns about deploying these models to safety-critical applications. In contrast, the Human Visual System (HVS), which utilizes spatial frequency channels to process visual signals, is immune to adversarial attacks. As such, this paper presents an empirical study exploring the vulnerability of CNN models in the frequency domain. Specifically, we utilize the discrete cosine transform (DCT) to construct the Spatial-Frequency (SF) layer to produce a block-wise frequency spectrum of an input image and formulate Spatial Frequency CNNs (SF-CNNs) by replacing the initial feature extraction layers of widely-used CNN backbones with the SF layer. Through extensive experiments, we observe that SF-CNN models are more robust than their CNN counterparts under both white-box and black-box attacks. To further explain the robustness of SF-CNNs, we compare the SF layer with a trainable convolutional layer with identical kernel sizes using two mixing strategies to show that the lower frequency components contribute the most to the adversarial robustness of SF-CNNs. We believe our observations can guide the future design of robust CNN models.
翻译:暂无翻译