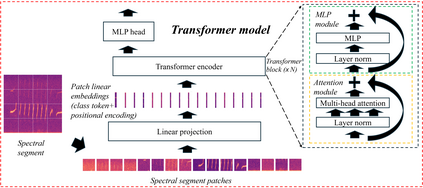
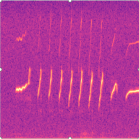
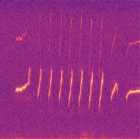
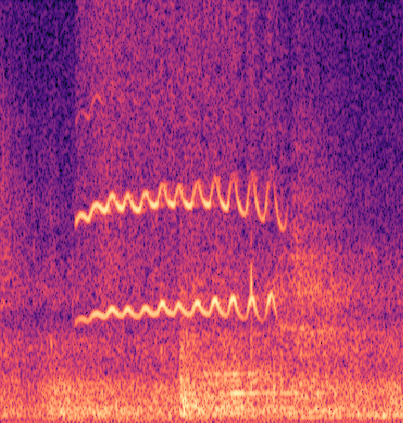
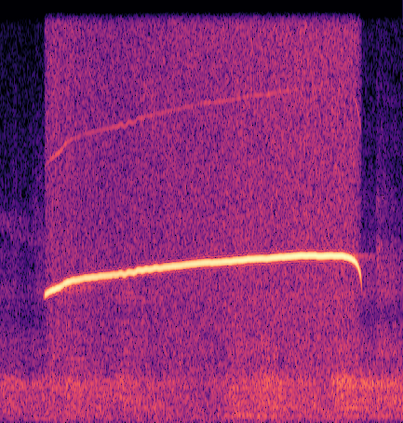
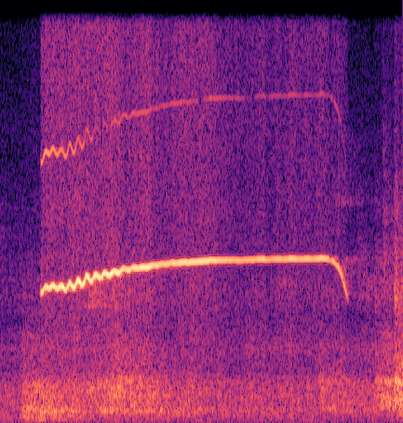
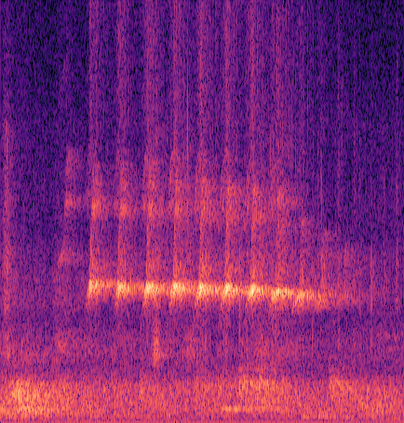
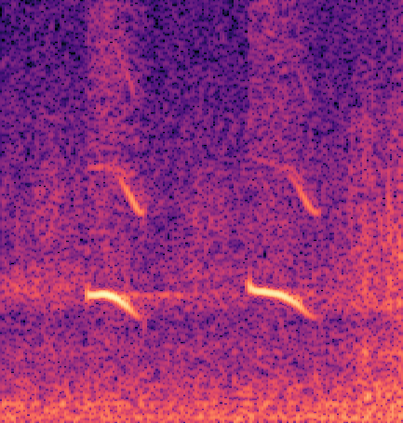
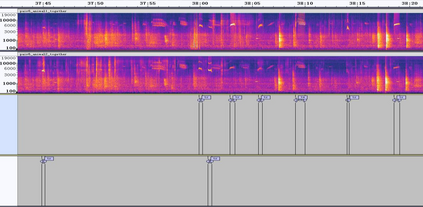
Marmoset, a highly vocalized primate, has become a popular animal model for studying social-communicative behavior and its underlying mechanism comparing with human infant linguistic developments. In the study of vocal communication, it is vital to know the caller identities, call contents, and vocal exchanges. Previous work of a CNN has achieved a joint model for call segmentation, classification, and caller identification for marmoset vocalizations. However, the CNN has limitations in modeling long-range acoustic patterns; the Transformer architecture that has been shown to outperform CNNs, utilizes the self-attention mechanism that efficiently segregates information parallelly over long distances and captures the global structure of marmoset vocalization. We propose using the Transformer to jointly segment and classify the marmoset calls and identify the callers for each vocalization.
翻译:暂无翻译