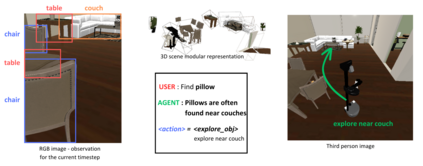
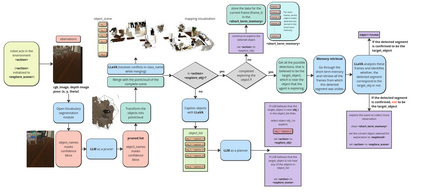
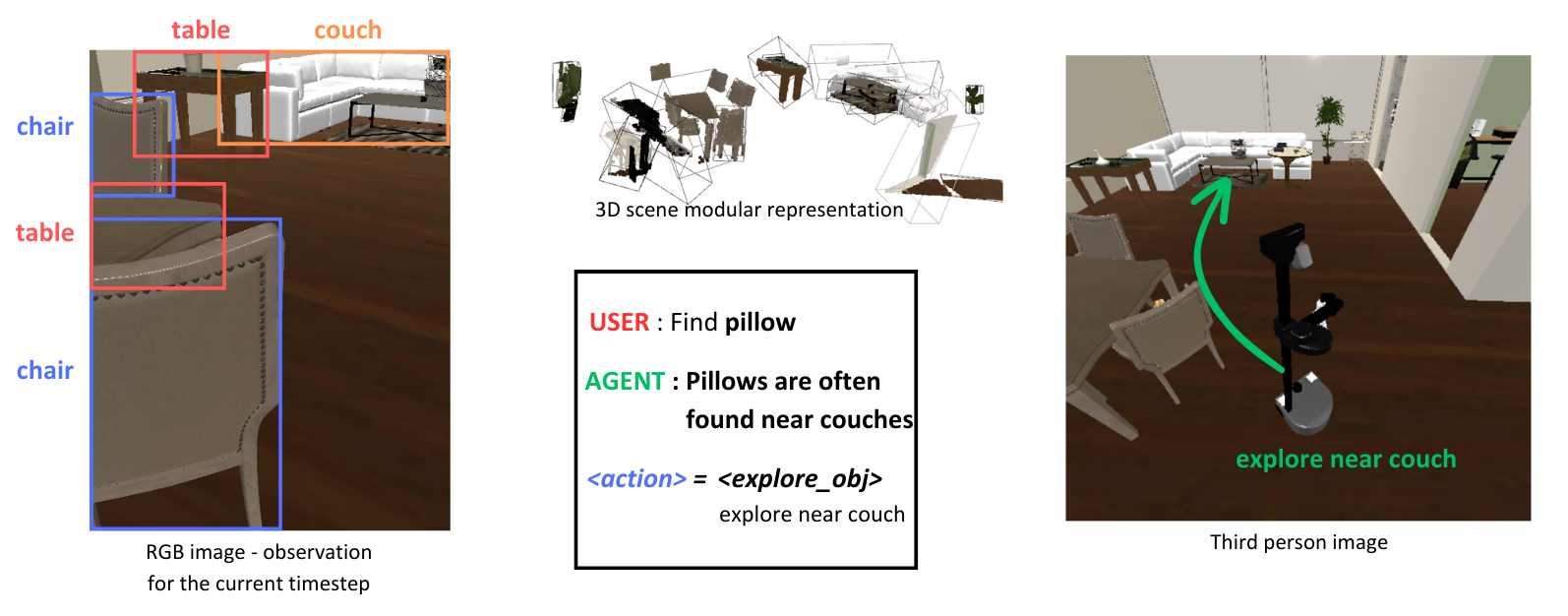
Recent advancements in Generative AI, particularly in Large Language Models (LLMs) and Large Vision-Language Models (LVLMs), offer new possibilities for integrating cognitive planning into robotic systems. In this work, we present a novel framework for solving the object goal navigation problem that generates efficient exploration strategies. Our approach enables a robot to navigate unfamiliar environments by leveraging LLMs and LVLMs to understand the semantic structure of the scene. To address the challenge of representing complex environments without overwhelming the system, we propose a 3D modular scene representation, enriched with semantic descriptions. This representation is dynamically pruned using an LLM-based mechanism, which filters irrelevant information and focuses on task-specific data. By combining these elements, our system generates high-level sub-goals that guide the exploration of the robot toward the target object. We validate our approach in simulated environments, demonstrating its ability to enhance object search efficiency while maintaining scalability in complex settings.
翻译:暂无翻译