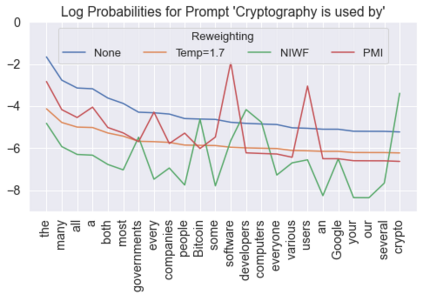
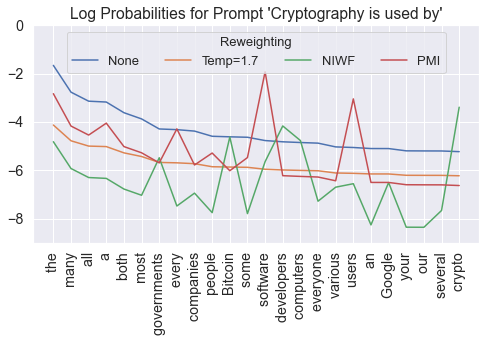
Language models are known to produce vague and generic outputs. We propose two unsupervised decoding strategies based on either word-frequency or point-wise mutual information to increase the specificity of any model that outputs a probability distribution over its vocabulary at generation time. We test the strategies in a prompt completion task; with human evaluations, we find that both strategies increase the specificity of outputs with only modest decreases in sensibility. We also briefly present a summarization use case, where these strategies can produce more specific summaries.
翻译:据知语言模式可以产生模糊和通用的产出。我们基于单词频率或点智互通信息,提出两个未经监督的解码战略,以增加任何模式的特殊性,从而在一代人的时间里在其词汇中产生概率分布。我们通过迅速完成任务测试这些战略;通过人类评价,我们发现这两个战略只会增加产出的具体性,而敏感度却略有下降。我们还简要地介绍了一个汇总使用案例,在这些案例中,这些战略可以产生更具体的摘要。