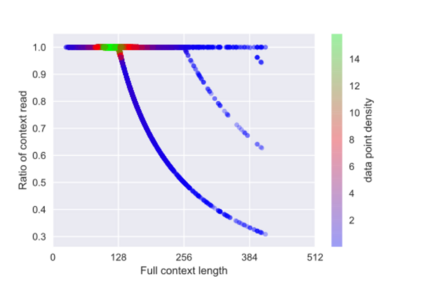
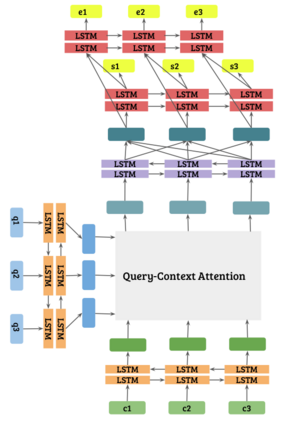
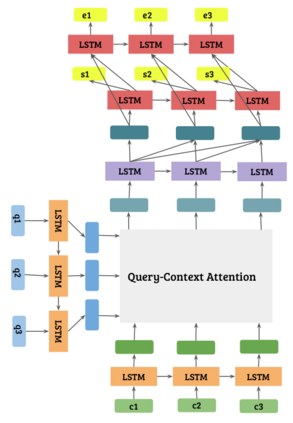
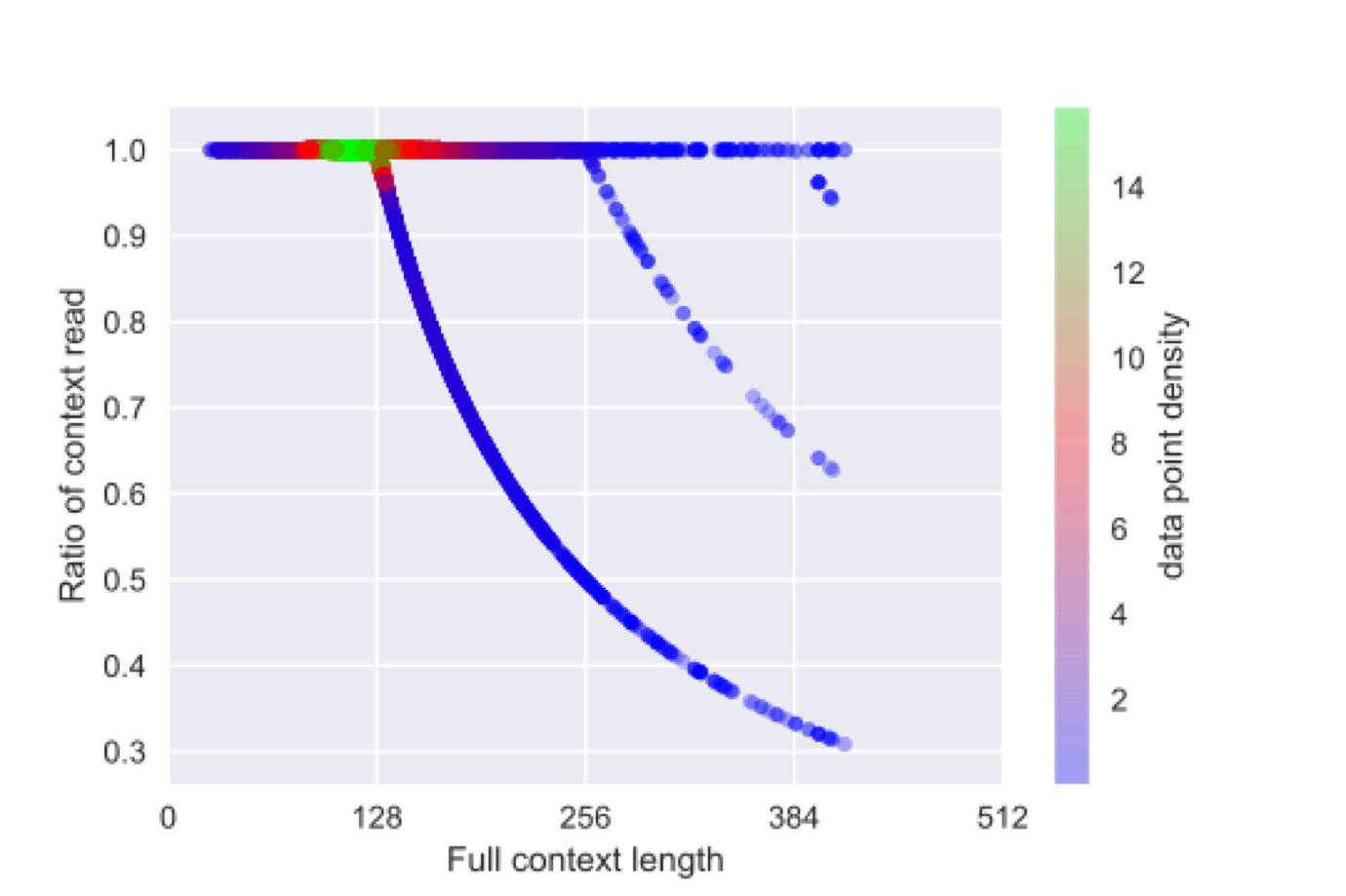
Any system which performs goal-directed continual learning must not only learn incrementally but process and absorb information incrementally. Such a system also has to understand when its goals have been achieved. In this paper, we consider these issues in the context of question answering. Current state-of-the-art question answering models reason over an entire passage, not incrementally. As we will show, naive approaches to incremental reading, such as restriction to unidirectional language models in the model, perform poorly. We present extensions to the DocQA [2] model to allow incremental reading without loss of accuracy. The model also jointly learns to provide the best answer given the text that is seen so far and predict whether this best-so-far answer is sufficient.
翻译:任何以目标为方向的继续学习系统不仅必须逐步学习,而且必须处理和吸收信息,这种系统还必须了解其目标何时实现。在本文中,我们从回答问题的角度来考虑这些问题。目前最先进的回答问题模型是整个段落而不是递增的。正如我们将显示的那样,对渐进阅读的天真的方法,例如对模型中单向语言模型的限制,效果很差。我们向DocQA模型提供扩展,允许在不丧失准确性的情况下进行递增读。模型还共同学习根据迄今为止所看到的文本提供最佳答案,并预测这一最佳答案是否足够。