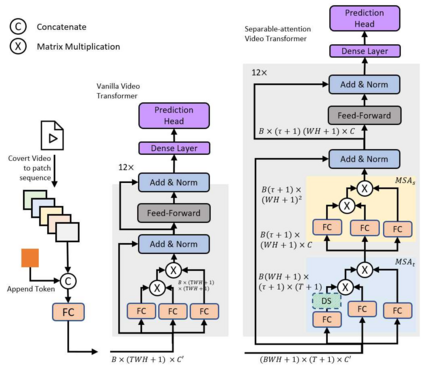
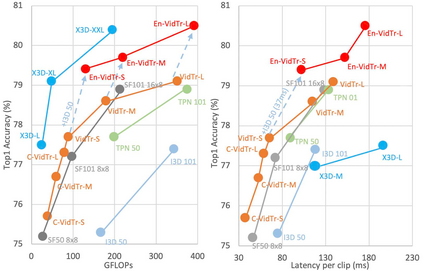
We introduce Video Transformer (VidTr) with separable-attention for video classification. Comparing with commonly used 3D networks, VidTr is able to aggregate spatio-temporal information via stacked attentions and provide better performance with higher efficiency. We first introduce the vanilla video transformer and show that transformer module is able to perform spatio-temporal modeling from raw pixels, but with heavy memory usage. We then present VidTr which reduces the memory cost by 3.3$\times$ while keeping the same performance. To further compact the model, we propose the standard deviation based topK pooling attention, which reduces the computation by dropping non-informative features. VidTr achieves state-of-the-art performance on five commonly used dataset with lower computational requirement, showing both the efficiency and effectiveness of our design. Finally, error analysis and visualization show that VidTr is especially good at predicting actions that require long-term temporal reasoning. The code and pre-trained weights will be released.
翻译:我们引入视频变换器( VidTr ), 并使用可分离的视频分类。 与常用的 3D 网络比较, VidTr 能够通过堆叠的注意力集聚时空信息, 并以更高的效率提供更好的性能。 我们首先引入了香草视频变压器, 并显示变压器模块能够从原始像素中进行时空建模, 但使用大量内存。 然后我们展示VidTr, 将存储成本降低3.3 $\ time, 并同时保持同样的性能。 为了进一步压缩模型, 我们建议基于标准偏差的顶级 K 集合关注, 通过丢弃非信息化特性来降低计算。 VidTr 在5个常用的数据集上取得最先进的性能, 并显示我们设计的效率和效力。 最后, 错误分析和直观化显示 VidTr 特别擅长预测需要长期时间推理的行动。 代码和预先训练的重量将被释放 。