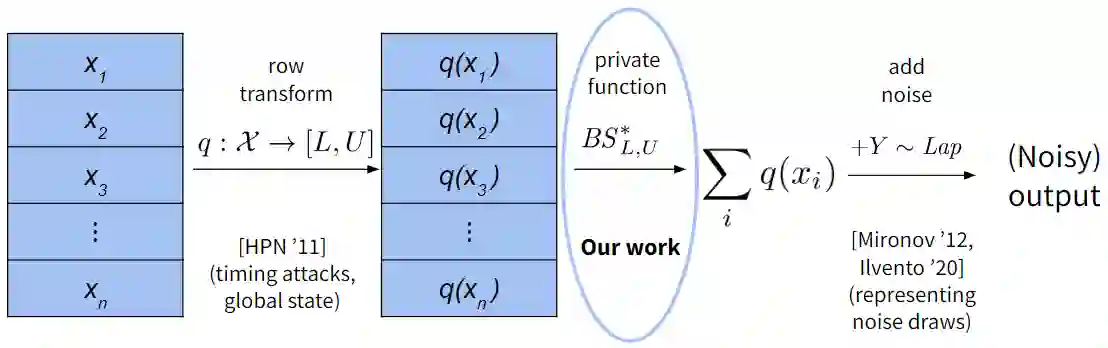
We identify a new class of vulnerabilities in implementations of differential privacy. Specifically, they arise when computing basic statistics such as sums, thanks to discrepancies between the implemented arithmetic using finite data types (namely, ints or floats) and idealized arithmetic over the reals or integers. These discrepancies cause the sensitivity of the implemented statistics (i.e., how much one individual's data can affect the result) to be much higher than the sensitivity we expect. Consequently, essentially all differential privacy libraries fail to introduce enough noise to hide individual-level information as required by differential privacy, and we show that this may be exploited in realistic attacks on differentially private query systems. In addition to presenting these vulnerabilities, we also provide a number of solutions, which modify or constrain the way in which the sum is implemented in order to recover the idealized or near-idealized bounds on sensitivity.
翻译:具体地说,当利用有限数据类型(即内流或浮点数)计算基本统计数据(如总和)和对真实数据或整数进行理想化计算之间存在差异时,就会出现这类数据。这些差异导致已执行统计数据的敏感度(即一个人的数据能对结果产生多大影响)大大高于我们预期的敏感度。因此,几乎所有有差异的隐私图书馆都未能引入足够的噪音来隐藏差异性隐私所要求的个人一级信息,而且我们表明,在现实地攻击差异性私人查询系统时,可能会利用这些数据。除了提出这些脆弱性外,我们还提供若干解决方案,这些解决方案修改或限制执行总和的方式,以便恢复理想化或接近理想化的敏感度界限。