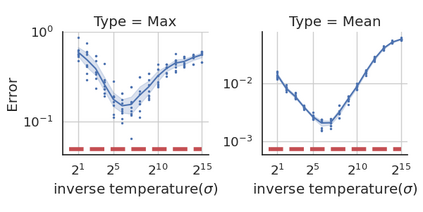
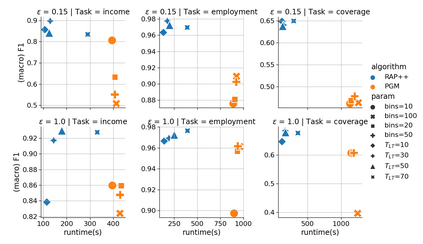
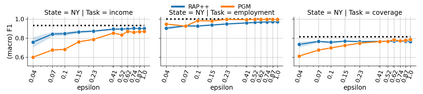
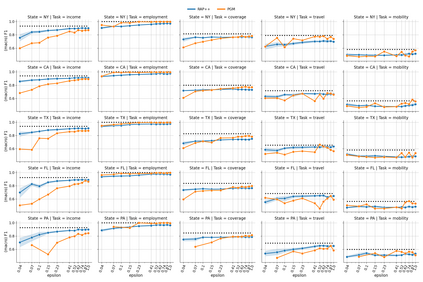
We provide a differentially private algorithm for producing synthetic data simultaneously useful for multiple tasks: marginal queries and multitask machine learning (ML). A key innovation in our algorithm is the ability to directly handle numerical features, in contrast to a number of related prior approaches which require numerical features to be first converted into {high cardinality} categorical features via {a binning strategy}. Higher binning granularity is required for better accuracy, but this negatively impacts scalability. Eliminating the need for binning allows us to produce synthetic data preserving large numbers of statistical queries such as marginals on numerical features, and class conditional linear threshold queries. Preserving the latter means that the fraction of points of each class label above a particular half-space is roughly the same in both the real and synthetic data. This is the property that is needed to train a linear classifier in a multitask setting. Our algorithm also allows us to produce high quality synthetic data for mixed marginal queries, that combine both categorical and numerical features. Our method consistently runs 2-5x faster than the best comparable techniques, and provides significant accuracy improvements in both marginal queries and linear prediction tasks for mixed-type datasets.
翻译:我们为制作合成数据同时提供一种对多种任务有用的有差别的私人算法:边际查询和多任务机器学习(ML)。我们的算法中的一个关键创新是能够直接处理数字特征,而与此不同的是,以前的一些相关方法要求首先将数字特征转换成{高基数}绝对特征,通过 {a binning 战略} 。为了提高准确性,需要更高程度的硬质颗粒度,但这种负面的可缩放性。消除对硬质的需求,使我们能够生成合成数据,保存大量统计查询,如数字特征边际和等级有条件线性临界值查询。保留后一种功能意味着,在实际和合成数据中,每个等级标签的分数大致相同。这是在多任务设置中训练线性分类员所需要的属性。我们的算法还使我们能够为混合的边际查询提供高质量的合成数据,既包括绝对性和数字性特征。我们的方法比最佳可比技术持续速度为2-5x,并在混合类型数据集的边际查询和线性预测任务中提供显著的精确性改进。