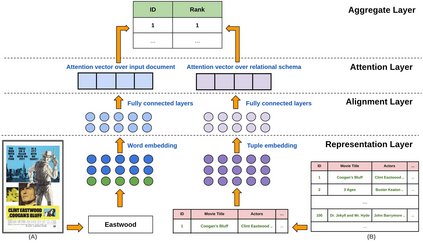
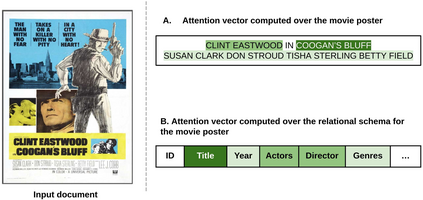
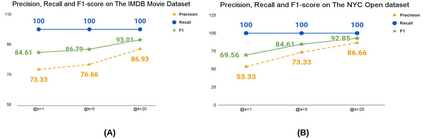
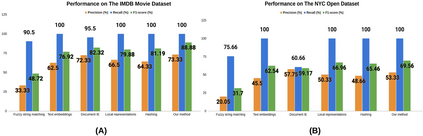
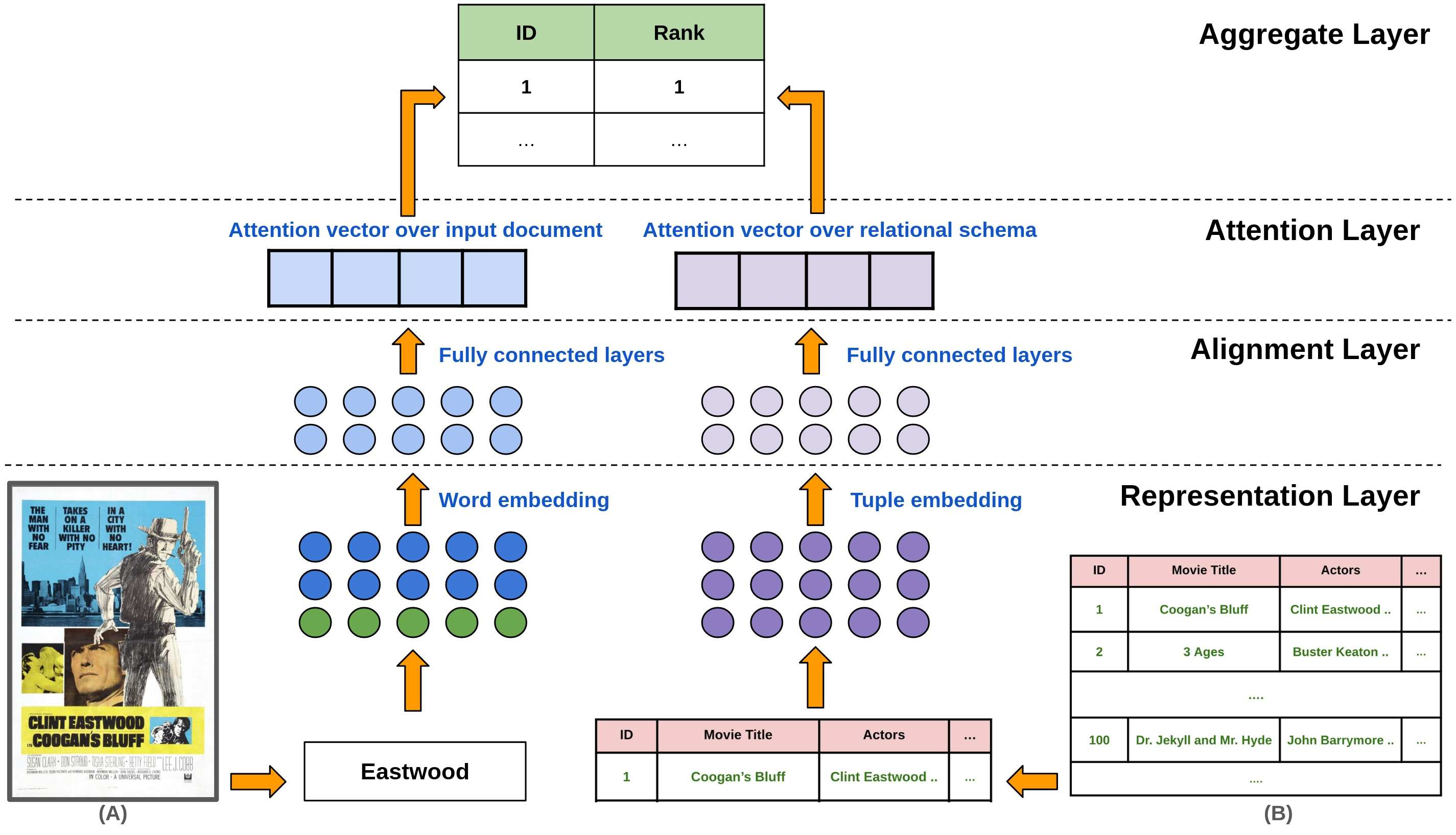
Visually rich documents (VRD) are physical/digital documents that utilize visual cues to augment their semantics. The information contained in these documents are often incomplete. Existing works that enable automated querying on VRDs do not take this aspect into account. Consequently, they support a limited set of queries. In this paper, we describe Juno -- a multimodal framework that identifies a set of tuples from a relational database to augment an incomplete VRD with supplementary information. Our main contribution in this is an end-to-end-trainable neural network with bi-directional attention that executes this cross-modal entity matching task without any prior knowledge about the document type or the underlying database-schema. Exhaustive experiments on two heteroegeneous datasets show that Juno outperforms state-of-the-art baselines by more than 6% in F1-score, while reducing the amount of human-effort in its workflow by more than 80%. To the best of our knowledge, ours is the first work that investigates the incompleteness of VRDs and proposes a robust framework to address it in a seamless way.
翻译:视觉丰富的文档( VRD) 是物理/数字文档, 使用视觉提示来增加语义。 这些文件中包含的信息往往不完整。 能够自动查询 VRDs的现有工作没有考虑到这个方面。 因此, 它们支持有限的一组查询 。 在本文中, 我们描述朱诺 -- -- 一个多式框架, 从关系数据库中找出一组图象, 以补充信息来补充不完整的 VRD。 我们在这方面的主要贡献是一个端到端的神经网络, 双向关注, 执行这一跨式实体匹配任务, 而不事先了解文件类型或基本数据库- schema 。 在两套异性数据组上进行的Exhaustive实验显示, Juno 超越了F1- score 中最新基线的6%以上, 同时将工作流程中的人类效率减少80%以上。 据我们所知, 我们的第一个工作是调查 VRDs 的不完全性, 并提议一个坚实的框架来解决这个问题。</s>