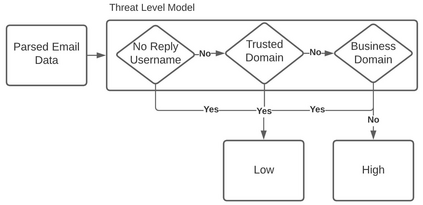
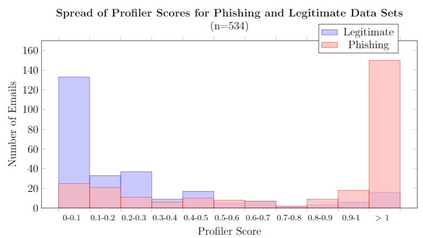
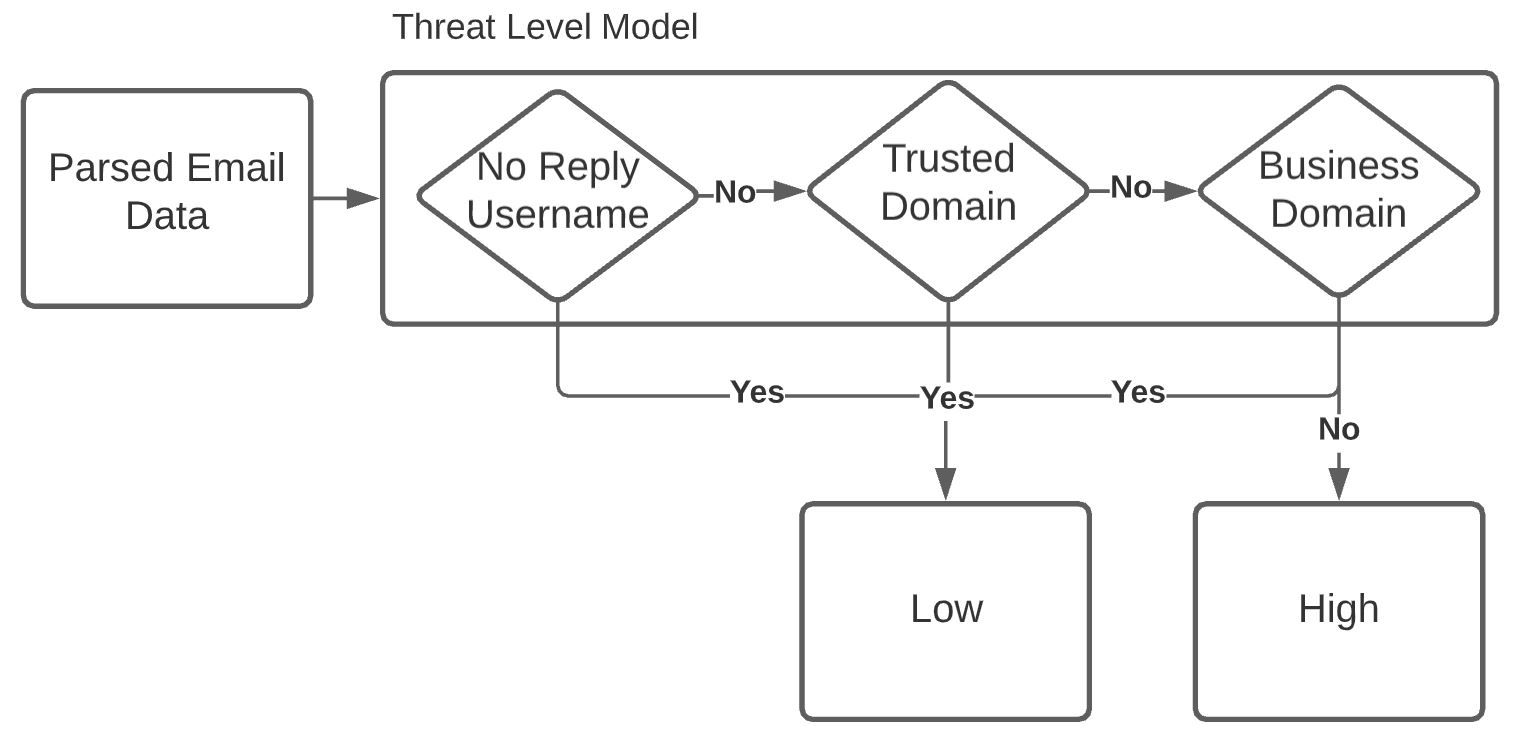
Email phishing has become more prevalent and grows more sophisticated over time. To combat this rise, many machine learning (ML) algorithms for detecting phishing emails have been developed. However, due to the limited email data sets on which these algorithms train, they are not adept at recognising varied attacks and, thus, suffer from concept drift; attackers can introduce small changes in the statistical characteristics of their emails or websites to successfully bypass detection. Over time, a gap develops between the reported accuracy from literature and the algorithm's actual effectiveness in the real world. This realises itself in frequent false positive and false negative classifications. To this end, we propose a multidimensional risk assessment of emails to reduce the feasibility of an attacker adapting their email and avoiding detection. This horizontal approach to email phishing detection profiles an incoming email on its main features. We develop a risk assessment framework that includes three models which analyse an email's (1) threat level, (2) cognitive manipulation, and (3) email type, which we combine to return the final risk assessment score. The Profiler does not require large data sets to train on to be effective and its analysis of varied email features reduces the impact of concept drift. Our Profiler can be used in conjunction with ML approaches, to reduce their misclassifications or as a labeller for large email data sets in the training stage. We evaluate the efficacy of the Profiler against a machine learning ensemble using state-of-the-art ML algorithms on a data set of 9000 legitimate and 900 phishing emails from a large Australian research organisation. Our results indicate that the Profiler's mitigates the impact of concept drift, and delivers 30% less false positive and 25% less false negative email classifications over the ML ensemble's approach.
翻译:电子邮件 phishing 越来越普遍, 并且随着时间推移, 越来越复杂。 为了遏制这一上升, 已经开发了许多用于检测phishing电子邮件的机器学习( ML) 算法。 但是, 由于这些算法所训练的电子邮件数据集有限, 它们不善于识别各种攻击, 因而受到概念的漂移; 攻击者可以对其电子邮件或网站的统计特征进行小改动, 以便成功地绕过检测。 随着时间的推移, 所报道的文献精确度与算法在真实世界中的实际有效性之间出现了差距。 这通过经常的错误正反正和反正的电子邮件分类来认识自己。 为此, 我们提议对电子邮件进行多层面的风险评估, 以减少攻击者调整电子邮件的电子邮件概念, 并避免被检测。 我们开发了一个风险评估框架, 分析电子邮件的威胁程度 (1), (2) 认知操纵, (3) 和 电子邮件类型, 我们结合了最后的风险评估分数。 简洁的数据集不需要大数据集来训练, 来有效和假正反正对电子邮件的Mliforal imal IM 。