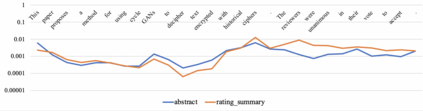
When directly using existing text generation datasets for controllable generation, we are facing the problem of not having the domain knowledge and thus the aspects that could be controlled are limited.A typical example is when using CNN/Daily Mail dataset for controllable text summarization, there is no guided information on the emphasis of summary sentences. A more useful text generator should leverage both the input text and control variables to guide the generation, which can only be built with deep understanding of the domain knowledge. Motivated by this vi-sion, our paper introduces a new text generation dataset, named MReD. Our new dataset consists of 7,089 meta-reviews and all its 45k meta-review sentences are manually annotated as one of the carefully defined 9 categories, including abstract, strength, decision, etc. We present experimental results on start-of-the-art summarization models, and propose methods for controlled generation on both extractive and abstractive models using our annotated data. By exploring various settings and analaysing the model behavior with respect to the control inputs, we demonstrate the challenges and values of our dataset. MReD allows us to have a better understanding of the meta-review corpora and enlarge the research room for controllable text generation.
翻译:当直接将现有的文本生成数据集用于可控的生成时,我们正面临着没有域知识的问题,因此可以控制的方面是有限的。一个典型的例子就是在使用CNN/Daily Mail数据集进行可控的文本总和时,没有关于摘要句重点的指导信息。一个更有用的文本生成器应该利用输入文本和控制变量来指导生成,这只有在对域知识有深刻了解的情况下才能建立。受此振动,我们的文件引入了一个新的文本生成数据集,名为MRED。我们的新数据集由7 089个元审查及其所有45公里的元审查句子组成,作为精心定义的9个类别之一,包括抽象、强度、决定等,手动加注解。我们在开始的艺术组合模型上提出了实验结果,并提出了利用我们附加说明的数据在采掘模型和抽象模型上进行受控生成的方法。通过探索各种设置和在控制投入方面的模型行为,我们展示了数据集的挑战和价值。我们的数据集和所有45公里的元审查是手动的注释,作为精心界定的9个类别之一,包括抽象、强度、强度、决定等等。我们能够更好地理解生成的版本的版本的模型研究。