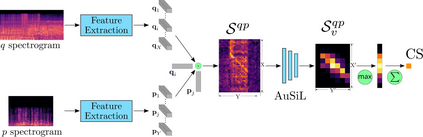
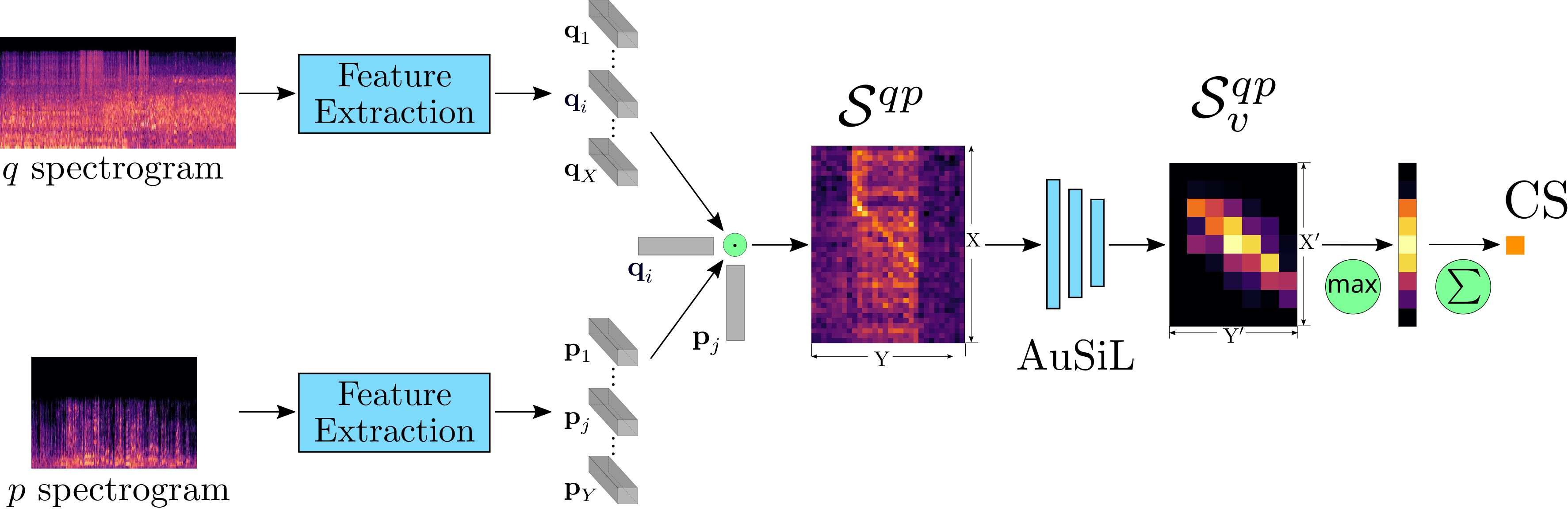
In this work, we address the problem of audio-based near-duplicate video retrieval. We propose the Audio Similarity Learning (AuSiL) approach that effectively captures temporal patterns of audio similarity between video pairs. For the robust similarity calculation between two videos, we first extract representative audio-based video descriptors by leveraging transfer learning based on a Convolutional Neural Network (CNN) trained on a large scale dataset of audio events, and then we calculate the similarity matrix derived from the pairwise similarity of these descriptors. The similarity matrix is subsequently fed to a CNN network that captures the temporal structures existing within its content. We train our network following a triplet generation process and optimizing the triplet loss function. To evaluate the effectiveness of the proposed approach, we have manually annotated two publicly available video datasets based on the audio duplicity between their videos. The proposed approach achieves very competitive results compared to three state-of-the-art methods. Also, unlike the competing methods, it is very robust to the retrieval of audio duplicates generated with speed transformations.
翻译:在这项工作中,我们处理基于音频的近复制视频检索问题。我们建议采用音频相似性学习(AuSiL)方法,有效捕捉视频配对之间的音频相似时间模式。为了对两个视频进行强有力的相似性计算,我们首先通过利用以大规模音频事件数据集培训的动态神经网络(CNN)为基础的传输学习,提取有代表性的音频视频描述符。然后我们计算出这些描述器的对称相似性矩阵。随后,将类似性矩阵输入一个有线电视新闻网网络,以捕捉其内容中存在的时间结构。我们培训我们的网络,遵循三重相生成过程,优化三重损失功能。为了评估拟议方法的有效性,我们根据视频视频的音频多彩度,手动了两个公开提供的视频数据集。拟议方法与三种最先进的方法相比,取得了非常有竞争力的结果。此外,与竞争性的方法不同,它对于以速度转换生成的音频重复进行检索非常可靠。