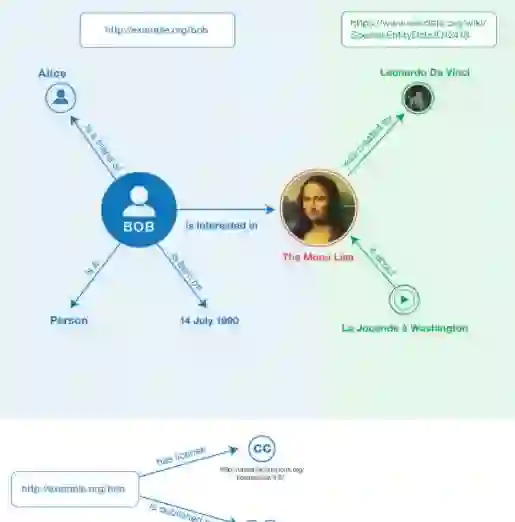
Knowledge Graphs (KGs) integrate heterogeneous data, but one challenge is the development of efficient tools for allowing end users to extract useful insights from these sources of knowledge. In such a context, reducing the size of a Resource Description Framework (RDF) graph while preserving all information can speed up query engines by limiting data shuffle, especially in a distributed setting. This paper presents two algorithms for RDF graph summarization: Grouping Based Summarization (GBS) and Query Based Summarization (QBS). The latter is an optimized and lossless approach for the former method. We empirically study the effectiveness of the proposed lossless RDF graph summarization to retrieve complete data, by rewriting an RDF Query Language called SPARQL query with fewer triple patterns using a semantic similarity. We conduct our experimental study in instances of four datasets with different sizes. Compared with the state-of-the-art query engine Sparklify executed over the original RDF graphs as a baseline, QBS query execution time is reduced by up to 80% and the summarized RDF graph is decreased by up to 99%.
翻译:知识图表(KGs)整合了各种数据,但一个挑战是开发有效的工具,使最终用户能够从这些知识来源中获取有用的见解。在这种情况下,在保存所有信息的同时,缩小资源描述框架图(RDF)的大小,通过限制数据打乱,可以加快查询引擎的速度,特别是在分布式设置中。本文介绍了RDF图形汇总的两种算法:组合基础汇总(GBS)和查询基础汇总(QBS)。后者是前一种方法的一种优化和无损的方法。我们实证地研究了拟议无损失的 RDF 图形组合以检索完整数据的效果,我们重新写入了RDFS Query 语言,称为STARQL 查询,使用相似的语义模式减少了三倍。我们在四个不同大小的数据集中进行实验研究。与在原始 RDF 图形中执行的状态- 查询引擎光化相比, QBS 查询时间减少至80%,而汇总的 RDF 图表则减少至99 %。