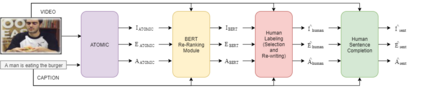
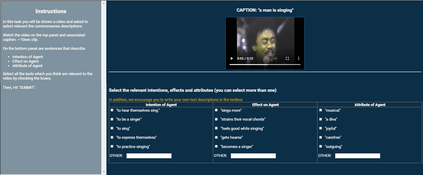
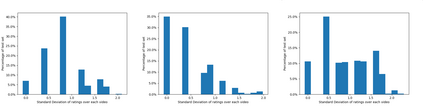
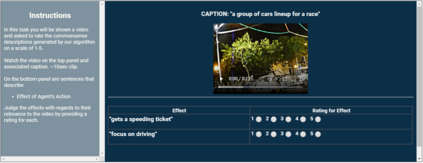
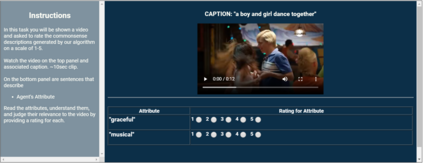
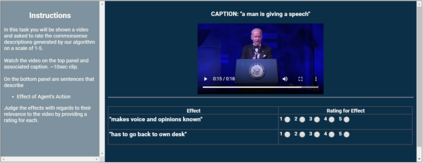
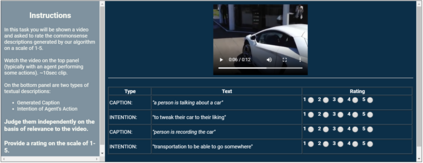
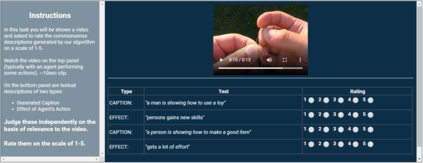
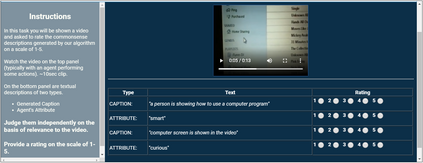
Captioning is a crucial and challenging task for video understanding. In videos that involve active agents such as humans, the agent's actions can bring about myriad changes in the scene. These changes can be observable, such as movements, manipulations, and transformations of the objects in the scene -- these are reflected in conventional video captioning. However, unlike images, actions in videos are also inherently linked to social and commonsense aspects such as intentions (why the action is taking place), attributes (such as who is doing the action, on whom, where, using what etc.) and effects (how the world changes due to the action, the effect of the action on other agents). Thus for video understanding, such as when captioning videos or when answering question about videos, one must have an understanding of these commonsense aspects. We present the first work on generating \textit{commonsense} captions directly from videos, in order to describe latent aspects such as intentions, attributes, and effects. We present a new dataset "Video-to-Commonsense (V2C)" that contains 9k videos of human agents performing various actions, annotated with 3 types of commonsense descriptions. Additionally we explore the use of open-ended video-based commonsense question answering (V2C-QA) as a way to enrich our captions. We finetune our commonsense generation models on the V2C-QA task where we ask questions about the latent aspects in the video. Both the generation task and the QA task can be used to enrich video captions.
翻译:视频理解是一项关键且具有挑战性的任务。 在涉及人类等活跃代理物的视频中, 代理物的行动可以给场景带来无数变化。 这些变化可以观察到, 比如视频的移动、 操纵和变换, 这些变化体现在常规视频字幕中。 然而, 与图像不同, 视频中的行动也与社会和常识方面有着内在的联系, 比如意图( 为何采取行动)、 属性( 比如谁在采取行动, 在哪里, 使用什么等等) 和影响( 行动导致的世界变化, 行动对其他代理物的影响) 。 因此, 这些变化对于视频理解, 比如在对视频进行字幕或回答关于视频的问题时, 人们必须了解这些常见的视频描述。 我们首先从视频中生成 \ textitit{ comsense} 标题, 以便描述意图、 属性和影响等潜在方面。 我们展示了一个新的数据集“ 以什么为基础, 使用什么等等, 使用什么等等, 以及效果2 视频( V2C ), 包含人类代理者进行各种行动的9k 视频视频视频视频视频视频视频视频视频视频视频视频视频视频, 以及我们用来解释的共同问题。