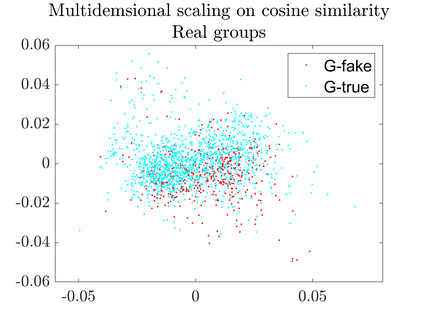
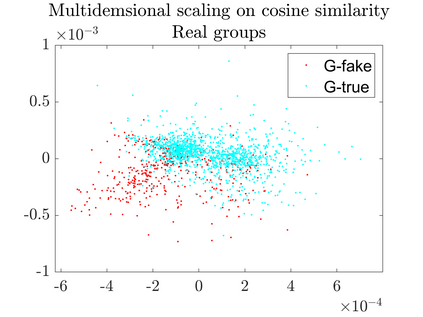
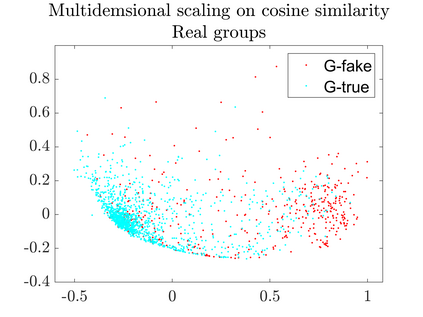
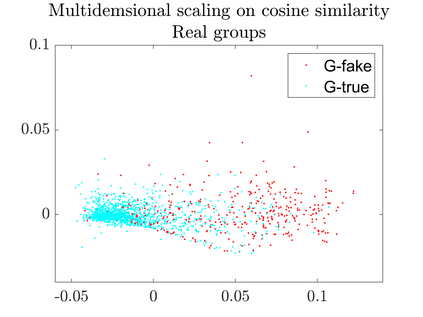
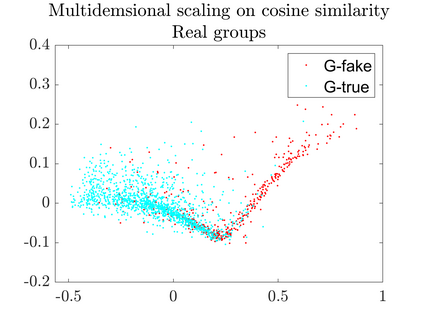
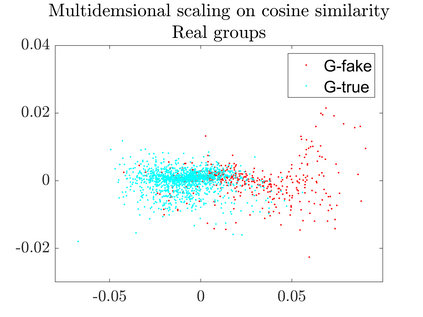
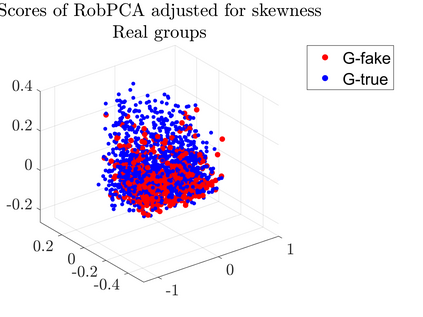
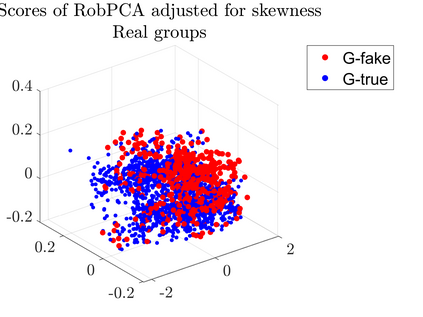
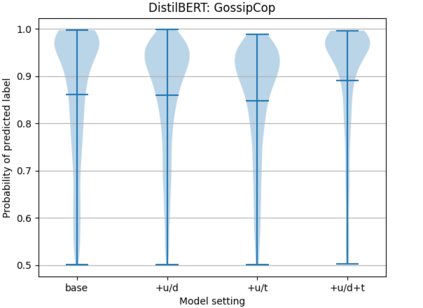
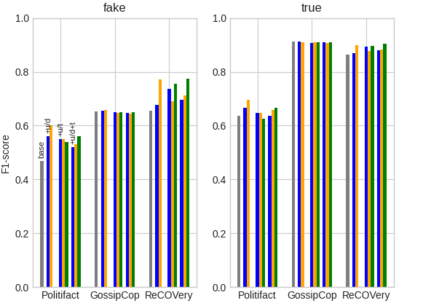
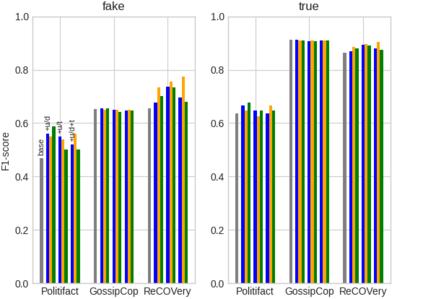
User-generated content (e.g., tweets and profile descriptions) and shared content between users (e.g., news articles) reflect a user's online identity. This paper investigates whether correlations between user-generated and user-shared content can be leveraged for detecting disinformation in online news articles. We develop a multimodal learning algorithm for disinformation detection. The latent representations of news articles and user-generated content allow that during training the model is guided by the profile of users who prefer content similar to the news article that is evaluated, and this effect is reinforced if that content is shared among different users. By only leveraging user information during model optimization, the model does not rely on user profiling when predicting an article's veracity. The algorithm is successfully applied to three widely used neural classifiers, and results are obtained on different datasets. Visualization techniques show that the proposed model learns feature representations of unseen news articles that better discriminate between fake and real news texts.
翻译:用户生成的内容(例如,推文和简况描述)和用户之间共享的内容(例如,新闻文章)反映了用户的在线身份。本文调查用户生成的内容和用户共享的内容之间的关联是否可用于在在线新闻文章中发现虚假信息。我们开发了一个用于识别虚假信息的多式学习算法。新闻文章和用户生成的内容的潜在表现使得在培训期间能够以选择与所评价的新闻报道内容相似的内容的用户的概况为指导,如果该内容在不同的用户之间共享,这种效果就会得到加强。在模型优化使用用户信息时,该模型在预测文章的真实性时并不依赖用户特征分析。该算法被成功地应用于三个广泛使用的神经分类者,并在不同的数据集中获取结果。视觉化技术显示,拟议的模型学习了对伪造和真实新闻文本进行更好区分的隐性新闻文章的特征描述。