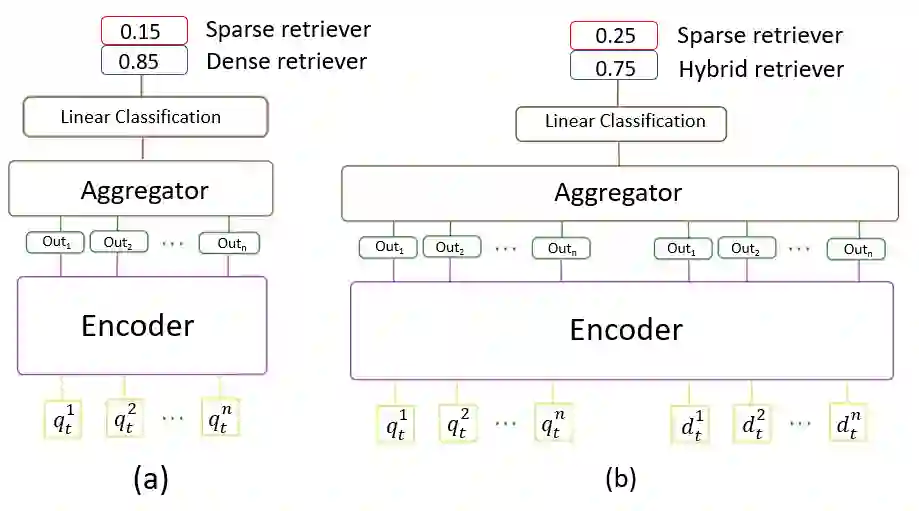
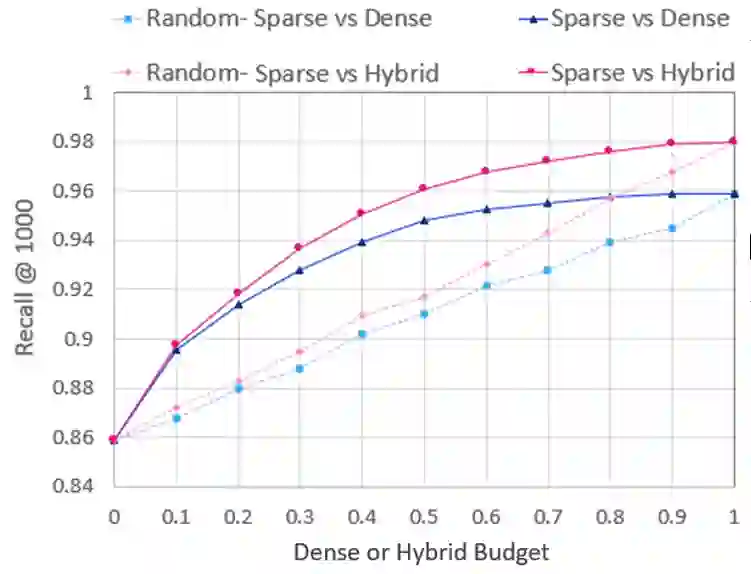
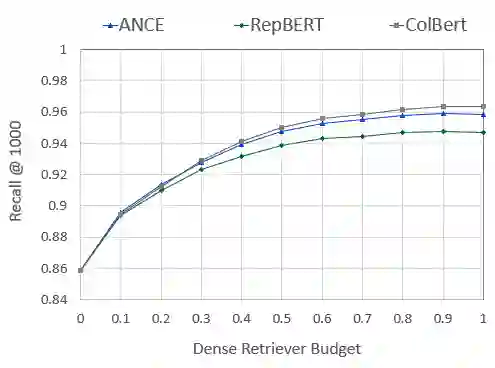
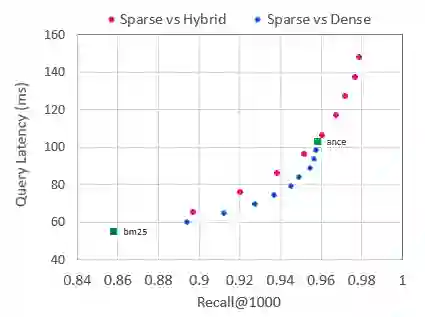
Over the last few years, contextualized pre-trained transformer models such as BERT have provided substantial improvements on information retrieval tasks. Recent approaches based on pre-trained transformer models such as BERT, fine-tune dense low-dimensional contextualized representations of queries and documents in embedding space. While these dense retrievers enjoy substantial retrieval effectiveness improvements compared to sparse retrievers, they are computationally intensive, requiring substantial GPU resources, and dense retrievers are known to be more expensive from both time and resource perspectives. In addition, sparse retrievers have been shown to retrieve complementary information with respect to dense retrievers, leading to proposals for hybrid retrievers. These hybrid retrievers leverage low-cost, exact-matching based sparse retrievers along with dense retrievers to bridge the semantic gaps between query and documents. In this work, we address this trade-off between the cost and utility of sparse vs dense retrievers by proposing a classifier to select a suitable retrieval strategy (i.e., sparse vs. dense vs. hybrid) for individual queries. Leveraging sparse retrievers for queries which can be answered with sparse retrievers decreases the number of calls to GPUs. Consequently, while utility is maintained, query latency decreases. Although we use less computational resources and spend less time, we still achieve improved performance. Our classifier can select between sparse and dense retrieval strategies based on the query alone. We conduct experiments on the MS MARCO passage dataset demonstrating an improved range of efficiency/effectiveness trade-offs between purely sparse, purely dense or hybrid retrieval strategies, allowing an appropriate strategy to be selected based on a target latency and resource budget.
翻译:过去几年来,BERT等经过事先培训的变压器模型在信息检索任务方面有了重大改进。最近基于事先培训的变压器模型的方法,如BERT, 微调密集的低维背景化查询和文件在嵌入空间中的表达方式。这些密集的检索器与稀少的检索器相比,在检索效力方面有很大的改进,但在计算上是密集的,需要大量的GPU资源,而且从时间和资源的角度来看,人们都知道密集的检索器比较昂贵。此外,还显示,稀少的检索器可检索到与密集检索器有关的补充信息,从而导致混合检索器的建议。这些混合检索器利用了成本低、精确匹配的零散检索器以及密集的检索器,以填补查询器和文件与文件之间的语义性差距。在这项工作中,我们用一个分类器来选择适合的检索战略(例如,稀疏漏的对密度比重),用精密的检索器来获取补充信息,从而能够用精密的检索器对精密的查询进行精确的查询,而用精密的精确的检索器来利用精准的检索器来利用精密的检索器来利用精密的检索器来利用精密的检索器来利用精密的精密的检索器来利用精细的检索器来缩小的检索器来缩小的检索器来缩小的检索器来缩小查询器来缩小查询器。在我们的检索器,我们在我们的计算方法,我们在我们的计算方法,我们在我们的计算中,我们的精度上,我们的精度上,我们的计算的计算的计算方法,,我们的精度的精度的计算的计算的精度的精度的精度可以降低对精度的精度的精度的精度的精度,我们的精度的精度的精度的精度的精度,我们的精度的精度,我们的精度的精度的精度的精度的精度的精度的精度的精度的精度的精度的精度的精度的精度的精度的精度的精度的精度的精度的精度的精度的精度,我们的精度的精度的精度的精度的精度,我们的精度的精度的精度的精度