文本挖掘从小白到精通(八)--- 从海量文章中挖掘主要观点

写在前面:笔者最近在梳理自己的文本挖掘知识结构,借助gensim、sklearn、keras等库的文档做了些扩充,会陆陆续续介绍文本向量化、tfidf、主题模型、word2vec,既会涉及理论,也会有详细的代码和案例进行讲解,希望在梳理自身知识体系的同时也能对想学习文本挖掘的朋友有一点帮助,这是笔者写该系列的初衷。
特别推荐|【文本挖掘系列教程】:
文本挖掘从小白到精通(一)---语料、向量空间和模型的概念
文本挖掘从小白到精通(三)---主题模型和文本数据转换
文本挖掘从小白到精通(五)---主题模型的主题数确定和可视化
文本挖掘从小白到精通(六)---word2vec的训练、使用和可视化
文本挖掘从小白到精通(七)--- Word2vec的增量学习
文本分类算法集锦,从小白到大牛,附代码注释和训练语料
---------------------分--------------隔-----------------线---------------------
从海量文章中挖掘主要观点,说的就是文本聚类,在商业语境下也叫“典型意见挖掘”,说简单点就是从大量无标签(比如文档的分类,教育、科技、文学等)的文本数据中发现其潜在的结构,根据文本数据的结构特征“归纳”出若干个主题或者意见(提取每个簇群中的典型代表语句)。
本例展示了如何使用Scikit-learn进行基于词袋模型(bag-of-words)的文本聚类。本例使用一个scipy.sparse矩阵来保存文本特征,取代标准的numpy数组。
在本文中,笔者使用了两种文本特征提取方法:
TfidfVectorizer使用基于内存的词汇表(是一个python dict)来映射高频词汇到特征索引(features indices),因此计算词汇出现频次(稀疏)矩阵。 然后,词频通与逆向文档频率(IDF,Inverse Document Frequency)进行加权,得到tf-idf权重值。
HashingVectorizer将词汇共现哈希(hash)到一个固定的维度空间,这大大减小了向量的长度,有利于计算效率的提升和计算资源的节约,但可能会出现多个词汇共用同一id的情况。 然后,再将词汇的计数向量(word count vectors)标准化为每个都有l2范数且长度等于1(投射到欧几里德单位球),这对于K-means在高维空间中实现高效的聚类很有裨益。
HashingVectorizer不提供IDF加权,因为这是一个无状态模型(fit方法什么都不做)。 当需要IDF加权时,可通过将它的输出流水线化(pipeline)到TfidfTransformer实例来添加。
在聚类算法的选择上,笔者也提供了两个选项:
普通的K-means及其更具可扩展性的“小兄弟”Minibatch K-means。
此外,潜在语义分析(Latent Semantic Analysis)也可用于减少维度,并发现文本数据中的潜在模式(latent patterns)。
值得注意的是, K-means(和Minibatch K-means)对于特征的缩放非常敏感。在这种情况下,IDF加权(IDF weighting)有助于提升文本聚类的质量。
这种提升在剪影系数(Silhouette Coefficient)中是不可见的,因为该系数的数值很小。因为,这种测度似乎遭受所谓的“度量集中”或“维度诅咒”,对于高维数据集是较为常见的,比如文本数据。
其他度量,如V-measure和Adjusted Rand指数是基于信息论的评估分数:因为它们仅基于在群集分配而不是距离上,因此不受“维度诅咒”的影响。
注意:由于K-means是在优化非凸目标函数(Non-Convex Objective Function),因而很容易达到局部最优。 有几个独立的随机初始化运行对于获得良好的聚类收敛是很有必要的。
对于本文的聚类示例,笔者采取的如下步骤:
文本预处理(切词、去除停用词、数字归一化等)
构建基于TF-IDF的向量空间模型(Vector Space Model,VSS)
使用LSA / SVD对文档向量降维(可选,当维度过高时可以选用)
使用肘部方法(Elbow Method) 去发现最优的聚类数量
按照得出的最优聚类数,使用K-means或Minibatch K-means进行文本聚类
下面是实际操作过程:
1 载入必要的库,数量之多,绝对是个大工程!
from __future__ import print_functionfrom sklearn.decomposition import PCAfrom sklearn.decomposition import TruncatedSVDfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.feature_extraction.text import HashingVectorizerfrom sklearn.feature_extraction.text import TfidfTransformerfrom sklearn.pipeline import make_pipelinefrom sklearn.preprocessing import Normalizerfrom sklearn import metricsfrom pprint import pprintfrom sklearn.cluster import KMeans, MiniBatchKMeansimport pandas as pdimport jiebaimport loggingfrom optparse import OptionParserimport sysfrom time import timeimport numpy as np
2 加入日志和预设参数
每个参数都有说明,如果需要修改,请在default处进行操作。
# 将进展日志呈现在stdout上logging.basicConfig(level=logging.INFO,format='%(asctime)s %(levelname)s %(message)s')# parse 命令行参数op = OptionParser()op.add_option("--lsa",dest="n_components", type="int", default=120,help="利用潜在语义分析对文本数据进行预处理")op.add_option("--no-minibatch",action="store_false", dest="minibatch", default=False,help="使用一般的K-means算法 (使用batch模式).")op.add_option("--no-idf",action="store_false", dest="use_idf", default=False,help="禁用逆向文档频率特征加权。")op.add_option("--use-hashing",action="store_true", default=False,help="使用Hashing特征向量")op.add_option("--n-features", type=int, default=40000,help="从文本中提取的最大特征(维度)数量。")op.add_option("--verbose",action="store_true", dest="verbose", default=False,help="在K-means算法中打印进度报告。")print(__doc__)op.print_help()def is_interactive():return not hasattr(sys.modules['__main__'], '__file__')#解决Jupyter notebook 和IPython控制台的问题argv = [] if is_interactive() else sys.argv[1:](opts, args) = op.parse_args(argv)if len(args) > 0:op.error("该脚本不需要设置参数")sys.exit(1)
Automatically created module for IPython interactive environment
Usage: ipykernel_launcher.py [options]
Options:
-h, --help show this help message and exit
--lsa=N_COMPONENTS 利用潜在语义分析对文本数据进行预处理
--no-minibatch 使用一般的K-means算法 (使用batch模式).
--no-idf 禁用逆向文档频率特征加权。
--use-hashing 使用Hashing特征向量
--n-features=N_FEATURES
从文本中提取的最大特征(维度)数量。--verbose 在K-means算法中打印进度报告。
3 文本预处理
笔者将scikit-learn中的TfidfVectorizer类稍稍改写下,
以便将文本中的数字特征统一表示成"#NUMBER",达到一定的降噪效果。
def number_normalizer(tokens):""" 将所有数字标记映射为一个占位符(Placeholder)。对于许多实际应用场景来说,以数字开头的tokens不是很有用,但这样tokens的存在也有一定相关性。通过将所有数字都表示成同一个符号,可以达到降维的目的。"""return ("#NUMBER" if token[0].isdigit() else token for token in tokens)#继承TfidfVectorizer,拥有该类的特性,参数设置几近一致class NumberNormalizingVectorizer(TfidfVectorizer):def build_tokenizer(self):tokenize = super(NumberNormalizingVectorizer, self).build_tokenizer()return lambda doc: list(number_normalizer(tokenize(doc)))载入虎嗅网的文章数据,近五年的主页文章,包含40000+篇文章:
data = pd.read_excel('/home/kesci/input/huxiu6663/虎嗅网.xlsx','Sheet1')看看文章数据的结构,包含哪些字段:
data.head(2)
data.describe() #看看文章数据中的互动数据的描述性统计特征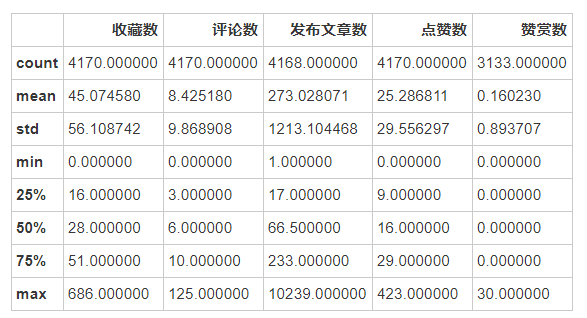
去掉正文为空的行:
null = data['文章正文'].isnull()no_null = ~nulldata = data[no_null]
去掉正文重复的行:
data = data.drop_duplicates('文章正文')清洗后的“干净”文本数据量:
len(data['文章正文'])3958
载入停用词表,用于过滤无意义的词汇,在提取文本特征时会用到:
stwlist=[line.strip() for line in open('/home/input/苏格兰折耳喵/停用词汇总.txt','r',encoding='utf-8').readlines()]
对文本进行分词处理,在Linux上可以实施并行分词,充分利用计算机多核心的优势加快文本分词进程:
jieba.enable_parallel(32)data['正文切词'] = data['文章正文'].apply(lambda i:jieba.lcut(i) )docs = data['正文切词']docs[:10] #展示靠前的十篇文章的分词效果,注意,每篇文章变成了有一连串词汇组成的list(列表)
0 [来源, :, 苏宁, 财富, 资讯, 作者, :, 苏宁, 金融, 研究院, 研究员, ...
1 [虎, 嗅, 华东, 报道, 作者, , |, , 范, 向东, , , 编辑, ...
2 [本文, 转自, 微信, 公众, 号, :, 爱范儿, (, ID, :, ifanr, )...
3 [晚上, 好, !, 为, 你, 送, 上, 今天, 的, 晚报, 消息, 。, 第一条, ...
4 [本文, 转自, 微信, 公众, 号, :, IT, 时报, (, ID, :, vitti...
5 [本文, 来自, 微信, 公众, 号, :, 骚客, 文艺, (, soulker2017,...
6 [来源, :, 三节课, (, ID, :, sanjieke01, ), 作者, :, 黄...
7 [本文, 转自, 微信, 公众, 号, :, AI, 财经, 社, (, ID, :, ai...
8 [2018, 年, 4, 月, 20, 日, ,, 北京, ,, 超市货架, 牛栏山, 二锅...
9 [大家, 晚上, 好, ,, 周一, 上班, 累不累, ?, 今天, 给, 大家, 带来, ...
Name: 正文切词, dtype: object
将每篇文章有词汇list转化为由空格隔开的string(字符串),便于后续的词汇-文档矩阵的构建:
data['正文切词'] =[' '.join(i) for i in docs]data['正文切词'][:10] # 展示前十篇文章的转化效果
0 来源 : 苏宁 财富 资讯 作者 : 苏宁 金融 研究院 研究员 付 一夫 最近 , 拼...
1 虎 嗅 华东 报道 作者 | 范 向东 编辑 | 李 清乐 今年 3...
2 本文 转自 微信 公众 号 : 爱范儿 ( ID : ifanr ) , 作者 : 文俊 。...
3 晚上 好 ! 为 你 送 上 今天 的 晚报 消息 。 第一条 是 关于 短 视频 的 , ...
4 本文 转自 微信 公众 号 : IT 时报 ( ID : vittimes ) 。 虎 嗅 ...
5 本文 来自 微信 公众 号 : 骚客 文艺 ( soulker2017 ) , 值班 主编 ...
6 来源 : 三节课 ( ID : sanjieke01 ) 作者 : 黄有璨 、 张成翼 20...
7 本文 转自 微信 公众 号 : AI 财经 社 ( ID : aicjnews ) , 作者...
8 2018 年 4 月 20 日 , 北京 , 超市货架 牛栏山 二锅头 , 题图 来自 : ...
9 大家 晚上 好 , 周一 上班 累不累 ? 今天 给 大家 带来 的 首条 消息 是 关于 ...
Name: 正文切词, dtype: object
最重要的文档特征提取环节到了!
4 文本特征提取
在这里,我们可以选用上面提到的HashingVectorizer和NumberNormalizingVectorizer(实际上就是TfidfVectorizer)。
这里,笔者选用的是NumberNormalizingVectorizer。如果你想用HashingVectorizer,那么在提取完特征后,还需要用TfidfTransformer提取文档的TF-IDF特征。
另外,笔者在这里没有使用LSA进行文本降维处理,因为这会损失掉部分有用的信息,不到万不得已,笔者不会使用。
print("%d 个文档" % len(data['正文切词']))print()print("使用稀疏向量(Sparse Vectorizer)从训练集中抽取特征")t0 = time()if opts.use_hashing:if opts.use_idf:#对HashingVectorizer的输出实施IDF规范化hasher = HashingVectorizer(n_features=opts.n_features,stop_words=stwlist, alternate_sign=False,norm=None, binary=False)vectorizer = make_pipeline(hasher, TfidfTransformer())else:vectorizer = HashingVectorizer(n_features=opts.n_features,stop_words=stwlist,alternate_sign=False, norm='l2',binary=False)else:vectorizer = NumberNormalizingVectorizer(max_df=0.5, max_features=opts.n_features,min_df=2, stop_words=stwlist,ngram_range=(1, 2),use_idf=opts.use_idf)X = vectorizer.fit_transform(data['正文切词'])print("完成所耗费时间: %fs" % (time() - t0))print("样本数量: %d, 特征数量: %d" % X.shape)print()if opts.n_components:print("用LSA进行维度规约(降维)")t0 = time()#Vectorizer的结果被归一化,这使得KMeans表现为球形k均值(Spherical K-means)以获得更好的结果。#由于LSA / SVD结果并未标准化,我们必须重做标准化。svd = TruncatedSVD(opts.n_components)normalizer = Normalizer(copy=False)lsa = make_pipeline(svd, normalizer)X = lsa.fit_transform(X)print("完成所耗费时间: %fs" % (time() - t0))explained_variance = svd.explained_variance_ratio_.sum()print("SVD解释方差的step: {}%".format(int(explained_variance * 100)))print('特征抽取完成!')print('特征抽取完成!')##############################################################################
3958 个文档
使用稀疏向量(Sparse Vectorizer)从训练集中抽取特征
完成所耗费时间: 22.493036s
样本数量: 3958, 特征数量: 40000
特征抽取完成!
5 使用肘部方法(Elbow Method) 发现最佳聚类数
值得一提的是关于聚类中心数目(K值)的选取,的确存在一种可行的方法,叫做Elbow Method:
通过绘制K-means代价函数与聚类数目K的关系图,选取直线拐点处的K值作为最佳的聚类中心数目。
上述方法中的拐点在实际情况中是很少出现的,待会你就会知道为什么了。
import matplotlib.pyplot as plt%matplotlib inlinen_clusters= 40wcss = []for i in range(1,n_clusters):if opts.minibatch:km = MiniBatchKMeans(n_clusters=i, init='k-means++', n_init=2,n_jobs=-1,init_size=1000, batch_size=1500, verbose=opts.verbose)else:km = KMeans(n_clusters=i, init='k-means++', max_iter=300, n_init=2,n_jobs=-1,verbose=opts.verbose)km.fit(X)wcss.append(km.inertia_)plt.plot(range(1,n_clusters),wcss)plt.title('肘 部 方 法')plt.xlabel('聚类的数量')plt.ylabel('wcss')plt.show()
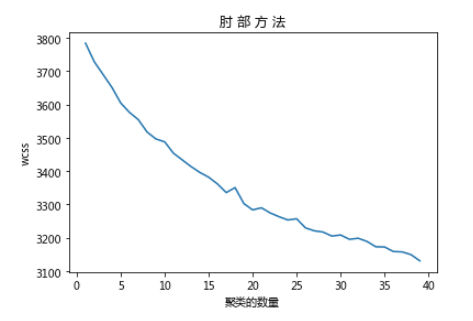
可以看到,并没有很好的“拐点”出现。
所以,笔者比较提倡的做法还是从实际问题出发,人工指定比较合理的K值,通过多次随机初始化聚类中心选取比较满意的结果。
在这里,笔者选择30作为聚类数,先试试效果,如果效果不好,再试试18、25等聚类数量。
labels = data['正文切词']true_k = 30 #聚类数量
6 进行事实上的文本聚类
这里有2个聚类方法,传统的K-Means和它的变种Mini Batch K-Means。
K-Means是常用的聚类算法,笔者在这里就不多介绍了,那就多说说Mini Batch K-Means:
Mini Batch K-Means是K-Means算法的变种,采用小批量的数据子集减小计算时间,同时仍试图优化目标函数,这里所谓的小批量是指每次训练算法时所随机抽取的数据子集,采用这些随机产生的子集进行训练算法,大大减小了计算时间,与其他算法相比,减少了k-均值的收敛时间,小批量k-均值产生的结果,同时也降低了聚类的效果,但是在实际项目中却表现得不明显。
鉴于此,笔者还是选用K-Means。
此外,由于 K-means 算法的分类结果会受到初始点的选取而有所区别,因此有提出这种算法的改进版本 --- K-means++ ,它能显著的改善分类结果的最终误差。
以下是具体实施过程:
if opts.minibatch:km = MiniBatchKMeans(n_clusters=true_k, init='k-means++', n_init=2,n_jobs=-1,init_size=1000, batch_size=1500, verbose=opts.verbose)else:km = KMeans(n_clusters=true_k, init='k-means++', max_iter=300, n_init=5,n_jobs=-1,verbose=opts.verbose)print("对稀疏数据(Sparse Data) 采用 %s" % km)t0 = time()km.fit(X)print("完成所耗费时间:%0.3fs" % (time() - t0))print()print("Homogeneity值: %0.3f" % metrics.homogeneity_score(labels, km.labels_))print("Completeness值: %0.3f" % metrics.completeness_score(labels, km.labels_))print("V-measure值: %0.3f" % metrics.v_measure_score(labels, km.labels_))print("Adjusted Rand-Index值: %.3f"% metrics.adjusted_rand_score(labels, km.labels_))print("Silhouette Coefficient值: %0.3f"% metrics.silhouette_score(X, km.labels_, sample_size=1000))print()#用训练好的聚类模型反推文档的所属的主题类别label_prediction = km.predict(X)label_prediction = list(label_prediction)if not opts.use_hashing:print("每个聚类的TOP关键词:")if opts.n_components:original_space_centroids = svd.inverse_transform(km.cluster_centers_)order_centroids = original_space_centroids.argsort()[:, ::-1]else:order_centroids = km.cluster_centers_.argsort()[:, ::-1]terms = vectorizer.get_feature_names()for i in range(true_k):print("簇群 %d " % (i+1), end='')print("该簇群所含文档占比为",'%.4f%%' % (int(label_prediction.count(i))/int(len(data['正文切词']))))print("簇群关键词:")for ind in order_centroids[i, :80]:print(' %s,' % terms[ind], end='')print('\n------------------------------------------------------------------------------------------------')
对稀疏数据(Sparse Data) 采用 KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=30, n_init=5, n_jobs=-1, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=False)
完成所耗费时间:750.241s
Homogeneity值: 0.374
Completeness值: 1.000
V-measure值: 0.544
Adjusted Rand-Index值: 0.000
Silhouette Coefficient值: 0.042
每个聚类的TOP关键词:
簇群 1 该簇群所含文档占比为 0.0217%
簇群关键词:
粉丝, 偶像, 节目, 明星, 女团, 练习生, 王菊, 艺人, 文化, 成员, 超越, 娱乐, 平台, 应援, 选手, 投票, 综艺, 品牌, 微博, 流量, 音乐, 鹿晗, 经纪, 内容, 少女, 偶像 练习生, 观众, 时代, 喜欢, 团队, 日本, 制作, 视频, 模式, 运营, 人气, 出道, 组合, 韩国, 吴亦凡, 二次元, 团体, 集资, 女孩, 话题, 选秀, 媒体, 经济, 行业, 合作, 孟美岐, 热度, 爱豆, 资源, 官方, 女性, 消费, 虚拟, 作品, 大家, 超过, 国内, 现场, 腾讯, 歌手, 广告, 舞台, 代言, 播出, 直播, 拥有, 传统, 产业, 游戏, 机会, 网红, 综艺节目, akb48, 互联网, 演出,
------------------------------------------------------------------------------------------------
簇群 2 该簇群所含文档占比为 0.0091%
簇群关键词:
共享, 单车, 汽车, 共享 单车, 自行车, 企业, 押金, 服务, 共享 汽车, 运营, 融资, 车辆, 出行, 充电, 平台, 滑板车, 宝马, 创业, 停车, 成本, ofo, 资本, 租赁, 投资, 投放, 摩拜, 项目, 电动, 模式, 经济, 共享 经济, 美国, 消费者, 领域, 城市, 需求, 创始人, ezzy, 行业, 业务, 按摩椅, 资金, 互联网, 合作, 超过, 智能, 共享 充电, uber, 停放, 管理, 用车, 共享 自行车, 滑板, 北京, 亿美元, lime, 奢侈品, 体验, 员工, 国内, 信息, 媒体, 骑行, 手机, 创业者, 平衡, 啸虎, 科技, 去年, 滴滴, 电动 滑板车, 自动, 租车, 奥迪, 合并, 李斌, 收购, 消息, 显示, 电动车,
------------------------------------------------------------------------------------------------
簇群 3 该簇群所含文档占比为 0.0382%
簇群关键词:
ai, 人工智能, 人类, 学习, 机器, 领域, 智能, 谷歌, 系统, 研究, 企业, 芯片, 信息, 算法, 识别, 机器人, 训练, 机器 学习, 平台, 美国, 场景, 科技, google, 医疗, 游戏, 马斯克, 深度, 分析, 理解, 行业, 服务, 模型, 产业, 预测, 开发者, 互联网, 项目, 内容, 开发, 团队, 自动, 语音, 深度 学习, 投资, facebook, 环境, 视觉, 微软, 过程, 时代, 判断, 硬件, 简单, 全球, 视频, deepmind, 翻译, 核心, 计算机, 需求, 创业, 神经网络, 研发, 人才, 发布, 巨头, 优势, alphago, 设备, 语言, 计算, 提升, 医生, 背后, 腾讯, ai 芯片, 传统, 百度, 业务, 大脑,
------------------------------------------------------------------------------------------------
簇群 4 该簇群所含文档占比为 0.0346%
簇群关键词:
电商, 京东, 平台, 微信, 阿里, 淘宝, 流量, 商品, 腾讯, 品牌, 商家, 模式, 消费, 黄峥, 消费者, 社交, 程序, 投资, 服务, 刘强, 业务, 唯品, 零售, 互联网, 购买, 行业, 价格, 电商 平台, 成本, 天猫, 合作, 增长, 企业, 内容, 领域, 卖家, 需求, 物流, 上市, 品类, 购物, 阿里巴巴, 销售, 当当, 假货, 农村, 生态, 亚马逊, 运营, 线下, 美国, 升级, 国内, 机会, 媒体, 超过, 团队, 支付, 大家, 亿美元, 交易, 上线, 价值, 社交 电商, 金融, 战略, 创业, 竞争, 信息, 核心, 自营, 成功, 巨头, 搜索, 城市, gmv, 场景, 规模, 客户, 手机,
------------------------------------------------------------------------------------------------
簇群 5 该簇群所含文档占比为 0.0159%
簇群关键词:
美国, uber, 中兴, 尼克, 亿美元, 投资, 华为, 卡兰, 卡兰 尼克, 软银, 企业, #NUMBER 亿美元, 全球, 谷歌, 员工, ceo, 业务, 董事会, 俄罗斯, 调查, 报道, 科技, 合作, 福耀, 中兴通讯, 政府, 特朗普, 服务, 印度, 手机, 芯片, 股东, 美元, 自动, 国内, 拥有, 超过, 媒体, 汽车, ola, 工厂, 出行, 交易, 创始人, 驾驶, 美国市场, 滴滴, 无人, 股票, 司机, 报告, 经济, waymo, 上市, 自动 驾驶, 消息, 美国政府, 汉堡, 接受, 收购, 文化, 领域, 董事, 诉讼, 研究, 工会, benchmark, 投资者, 行业, 信息, 高管, 回应, uber 董事会, 打车, 融资, 搜索, 贸易, 大家, 伊朗, 团队,
------------------------------------------------------------------------------------------------
簇群 6 该簇群所含文档占比为 0.1147%
簇群关键词:
企业, 互联网, 平台, 行业, 投资, 业务, 服务, 信息, 项目, 领域, 资本, 融资, 成本, 科技, 集团, 内容, 模式, 阿里, 增长, 团队, 收入, 品牌, 亿元, 芯片, 大家, 亿美元, 合作, 全球, 美国, 消费, 超过, 经济, 价值, 客户, 运营, 管理, 手机, 国内, 收购, 成功, 员工, 创业, 媒体, 腾讯, 系统, 需求, 支付, 股东, 影视, 产业, 乐视, 资金, #NUMBER 亿元, 销售, 酒店, 交易, 显示, 消费者, #NUMBER 亿美元, 微信, 上市, 人工智能, 时代, 传统, 发布, 价格, 核心, ceo, 阿里巴巴, 成立, 营销, 广告, 创始人, 英特尔, 区块, 商业, 过程, 研发, 场景, 金融,
------------------------------------------------------------------------------------------------
簇群 7 该簇群所含文档占比为 0.0167%
簇群关键词:
小米, 手机, 雷军, 上市, 互联网, 估值, 硬件, #NUMBER 小米, 生态, 亿美元, #NUMBER 亿美元, 华为, 业务, 价格, 品牌, 智能手机, 厂商, 小米 手机, 企业, 印度, 增长, 苹果, 小米 #NUMBER, 全球, 收入, 利润, 销量, ipo, 投资, 渠道, 模式, 国内, 超过, 行业, 去年, 亿元, 发布, oppo, #NUMBER 亿元, 智能, ov, 小米 生态, 电视, 科技, 香港, 出货量, 市值, mix, iot, 研发, 发布会, 广告, 销售, 价值, 核心, 资本, 招股书, 大家, 提升, 零售, 互联网服务, 竞争, miui, vivo, 设备, iphone, 成本, 显示, 领域, 小米 上市, 相机, 投资者, 消费, 游戏, 专利, 性价比, 服务, 空调, 三星, 腾讯,
------------------------------------------------------------------------------------------------
簇群 8 该簇群所含文档占比为 0.0205%
簇群关键词:
滴滴, 美团, 司机, 业务, 打车, 平台, 出行, 服务, 网约车, 补贴, 外卖, 出租车, 竞争, 领域, 乘客, uber, 亿美元, 程维, 美团 打车, 行业, 投资, 王兴, #NUMBER 亿美元, 城市, 互联网, 共享, 上海, 融资, 估值, 点评, 单车, 专车, 企业, 北京, 运营, 阿里, 腾讯, 订单, 资本, 全球, 大战, 支付, 交通, 信息, 收购, 上线, 流量, 美团 点评, 成本, 滴滴 出行, #NUMBER 美团, 汽车, 顺风, 规模, 财经, 场景, 战略, 南京, 去年, 价格, 摩拜, 微信, 显示, 车辆, 需求, 生活, 发布, 超过, 内部, 监管, 收入, 团队, 增长, 合作, 上市, #NUMBER 滴滴, 消息, 美国, 无人驾驶, 责任,
------------------------------------------------------------------------------------------------
簇群 9 该簇群所含文档占比为 0.0452%
簇群关键词:
汽车, 新能源, 电动车, 车型, 蔚来, 企业, 品牌, 驾驶, 特斯拉, 贾跃亭, 充电, 国内, 新能源 汽车, 造车, 合作, 投资, 量产, 政策, 领域, 电池, 传统, 工厂, 乐视, 美国, 系统, 电动, 自动, 研发, 销量, 互联网, 融资, 消费者, 车辆, 服务, 集团, 成本, 科技, 行业, 设计, 宝马, 车企, 新造, 电动汽车, 无人驾驶, 续航, 销售, 出行, 智能, 补贴, 全球, suv, 资本, 上市, 超过, 亿美元, 发布, 自动 驾驶, 亿元, 福特, 项目, 法拉第, 小鹏, es8, 时代, 公里, #NUMBER 亿元, 燃油, 积分, 业务, 制造, #NUMBER 公里, 价格, 合资, 资金, 拜腾, 功能, 比亚迪, 动力, 模式, 团队,
------------------------------------------------------------------------------------------------
簇群 10 该簇群所含文档占比为 0.0172%
簇群关键词:
单车, 共享, 共享 单车, ofo, 城市, 摩拜, 自行车, 企业, 投放, 融资, 运营, 小蓝, 押金, 行业, 成本, 骑行, 资本, 哈罗, 停放, 单车 企业, 出行, 哈罗 单车, 小蓝 单车, 车辆, 滴滴, 永安, 摩拜 ofo, 北京, 日本, 平台, 资金, 超过, 投资, 品牌, 模式, 订单, 政府, 管理, 合作, 数量, 玩家, 互联网, 团队, 李刚, 业务, 上海, 服务, 显示, 国内, 规模, 美国, 超过 #NUMBER, 创业, 单车 行业, 需求, 海外, 竞争, 出海, 骑单车, 黄车, 投入, 规范, 消息, 盈利, 投放量, 创始人, 市民, 策略, 亿美元, 亿元, 小鸣, 印度, 报道, 一年, 此前, 项目, 财经, 阿里, 骑车, 媒体,
------------------------------------------------------------------------------------------------
簇群 11 该簇群所含文档占比为 0.0195%
簇群关键词:
百度, 人工智能, 李彦宏, 陆奇, ai, 业务, 搜索, 互联网, 驾驶, 领域, 自动, 智能, 科技, 投资, 自动 驾驶, #NUMBER 百度, 平台, 战略, 团队, 内容, 谷歌, 吴恩达, 语音, 王劲, 事业部, 腾讯, 无人驾驶, 媒体, 学习, 无人, 合作, 服务, 信息, 硬件, dueros, 离职, 亿美元, 项目, 内部, 大会, 手机, 美国, 汽车, 时代, apollo, 广告, #NUMBER 亿美元, 信息流, 去年, 负责, 企业, 发布, 开放, 景驰, 头条, 核心, 副总裁, 创业, 百度 人工智能, 阿里, 调整, 资本, 成立, 百度 ai, 首席, 研究院, 行业, 增长, 一年, 系统, 收购, 亿元, 全球, 离开, 研究, 高管, 研发, 员工, 地图, 量产,
------------------------------------------------------------------------------------------------
簇群 12 该簇群所含文档占比为 0.0397%
簇群关键词:
游戏, 玩家, 腾讯, 手游, 网易, 内容, 任天堂, 平台, 日本, 主机, 国内, 厂商, 王者, 荣耀, 玩法, 体验, 开发, steam, 王者 荣耀, 行业, 手机, 作品, 制作, 文化, 微信, 角色, 上线, 故事, 小游戏, 社交, 发布, 美国, 电子游戏, 娱乐, 电竞, 设计, 现实, 项目, 团队, 英雄, ip, vr, 系列, 视频, 模式, 成功, 玩游戏, 合作, 大家, 产业, 喜欢, 官方, 电影, 开发者, 时代, 领域, 简单, 传统, 音乐, 发售, 核心, 版本, 拥有, 运营, 超过, 收入, 系统, 全球, 正式, 操作, 暴雪, 手柄, 生活, 魔兽, 类似, 游戏 玩家, 求生, #NUMBER 游戏, 发行, 绝地,
------------------------------------------------------------------------------------------------
簇群 13 该簇群所含文档占比为 0.0243%
簇群关键词:
智能, 音箱, 语音, google, 智能 音箱, 亚马逊, echo, ai, 设备, 交互, 人工智能, 硬件, alexa, 谷歌, 苹果, 手机, 功能, 国内, 小米, 语音 交互, 百度, 助手, 识别, 电视, 科技, 发布, 领域, 体验, 服务, homepod, 场景, 系统, 阿里, 平台, 耳机, 行业, 机器, 合作, 生态, 智能家居, 语音 助手, 内容, 信息, 出门, 联网, 问问, 巨头, 厂商, 出门 问问, 互联网, 团队, 设计, 价值, 芯片, 机器人, 销量, 企业, 腾讯, 价格, 美国, 手表, 投资, 消费者, 音乐, 学习, 支持, 模式, 眼镜, 家庭, assistant, 屏幕, 需求, 去年, 开发, 优势, google assistant, 研究, 语音 识别, 智能 语音, 超过,
------------------------------------------------------------------------------------------------
簇群 14 该簇群所含文档占比为 0.0114%
簇群关键词:
动画, 日本, netflix, 漫画, 内容, 作品, 动漫, 制作, 二次元, 电影, 原创, 观众, ip, 行业, 文化, jump, 创作, 国内, 平台, 合作, 故事, hbo, 少年, 日本 动画, 视频, 题材, 游戏, 连载, 女性, 模式, 美国, 投资, 腾讯, 版权, 产业, 抄袭, 时代, 票房, 杂志, 漫画家, 动画 制作, 年代, 拥有, 角色, 付费, 媒体, 商业, 开发, 网站, 成功, #NUMBER 年代, 业务, 传统, 亿美元, 足球, 奥巴马, 流媒体, 印度, 收入, 群体, 播出, 会员, 节目, 领域, 少年 jump, 柯南, 超过, 少女, 耽美, 大家, 系列, 改编, 委员会, 小说, 制作 委员会, 娱乐, 年轻人, 国产, 刀剑, 网剧,
------------------------------------------------------------------------------------------------
簇群 15 该簇群所含文档占比为 0.0344%
簇群关键词:
手机, 华为, 厂商, 小米, 三星, 智能手机, 魅族, 锤子, 印度, 科技, 品牌, vivo, 发布会, 罗永浩, 苹果, 发布, 屏幕, oppo, 设计, 消费者, 业务, 摄像头, 功能, 行业, 全球, 骁龙, 国内, 机型, 销量, iphone, 营销, 金立, 去年, 渠道, 联想, 锤子 科技, 骁龙 #NUMBER, 诺基亚, 体验, 出货量, 价格, htc, 高通, 增长, 魅蓝, 提升, 机身, 系统, 高端, 销售, 视频, 荣耀, 坚果, 设备, 性价比, 系列, 支持, 性能, android, 市场份额, 硬件, 售价, 企业, 时代, 指纹, 显示, 旗舰, tnt, 竞争, 芯片, 酷派, 配置, 处理器, 成本, 机器, 手机 厂商, 超过, ai, 互联网, 拍照,
------------------------------------------------------------------------------------------------
簇群 16 该簇群所含文档占比为 0.0483%
簇群关键词:
亿美元, 科技, #NUMBER 亿美元, 美国, 亚马逊, 消息, 苹果, 发布, 新浪, 报道, 腾讯, 投资, 特斯拉, 业务, 新浪 科技, 平台, 融资, 服务, 小米, 收购, 全球, 谷歌, 合作, 亿元, 企业, 上市, facebook, 回应, 美元, 员工, 北京, iphone, 汽车, 增长, 集团, 内容, 新闻, 手机, #NUMBER 亿元, #NUMBER 美元, 显示, ceo, 超过, 正式, 百度, 特朗普, 京东, 交易, 微信, 信息, 股价, 市值, 媒体, 滴滴, 阿里, 支付, 视频, 华为, 印度, 项目, uber, 阿里巴巴, 比特, 三星, 高通, 股东, 互联网, 有限公司, 机构, 领域, ipo, 功能, 价格, 支持, 区块, 游戏, 去年, 股份, 近日, 旗下,
------------------------------------------------------------------------------------------------
簇群 17 该簇群所含文档占比为 0.1688%
簇群关键词:
生活, 文化, 视频, 美国, 大家, 人类, 喜欢, 学习, 日本, 时代, 年轻人, 研究, 信息, 设计, 内容, 游戏, 媒体, 微信, 消费, 系统, 互联网, 机器, 电影, 朋友, 教育, 故事, 社交, 简单, 过程, 科技, 平台, 公众, 音乐, 领域, 拥有, 广告, 节目, 学生, 年轻, 体验, 作品, 品牌, 大学, alphago, 团队, 成功, 价值, 关系, 手机, 空间, 学校, 现实, 女性, 城市, 发布, 理解, 超过, 国内, 老师, 观众, 粉丝, 功能, 历史, 项目, 谷歌, 传统, 年代, 小时, 行业, 群体, 改变, 经济, 机会, 服务, 一年, 北京, 家庭, 算法, 专业, 比赛,
------------------------------------------------------------------------------------------------
簇群 18 该簇群所含文档占比为 0.0285%
簇群关键词:
视频, 内容, 抖音, 平台, 头条, 快手, 腾讯, 流量, 直播, 微视, 微信, 信息, 媒体, 社交, 粉丝, 广告, 推荐, 互联网, 微博, 网站, 算法, 发布, 功能, 行业, 新闻, 账号, 运营, asmr, 模式, 增长, 领域, 团队, 评论, 品牌, 音乐, 超过, 明星, 传播, 视频 内容, 优酷, 变现, 制作, qq, 国内, 电商, 朋友圈, 合作, 付费, 视频 平台, 视频 网站, 播放, 节目, 分享, 创作, 创作者, 渠道, 关系, 官方, 上线, 娱乐, 游戏, 淘宝, youtube, 年轻人, 文化, 机构, 补贴, 机器, 收入, 生活, 拥有, 去年, 小视频, 版权, 审核, 网红, 段子, 吸引, mcn, 容易,
------------------------------------------------------------------------------------------------
簇群 19 该簇群所含文档占比为 0.0298%
簇群关键词:
零售, 无人, 货架, 线下, 阿里, 无人 货架, 腾讯, 便利店, 门店, 超市, 企业, 消费, 电商, 商品, 生鲜, 便利, 永辉, 消费者, 品牌, 模式, 供应链, 互联网, 传统, 行业, 成本, 餐饮, 业务, 运营, 体验, 服务, 京东, 投资, 场景, 商业, 流量, 盒马, 合作, 城市, 物流, 需求, 渠道, 零售业, 领域, 家乐福, 平台, 业态, 配送, 线上, 资本, 智能, 高鑫, 销售, 升级, 上线, 布局, 巨头, 物种, 生活, 亚马逊, 超级, 融资, 核心, 竞争, 战略, 每日, 超级 物种, 价值, 购物, 沃尔玛, 高鑫 零售, 支付, 经营, 品类, 分享, 优鲜, 实体, 入股, 社区, 顾客, 每日 优鲜,
------------------------------------------------------------------------------------------------
簇群 20 该簇群所含文档占比为 0.0192%
簇群关键词:
驾驶, 自动, 自动 驾驶, 汽车, 无人, 车辆, 系统, 测试, 特斯拉, 驾驶 汽车, 传感器, 百度, waymo, 无人驾驶, 科技, 合作, ai, 道路, 司机, 激光雷达, 功能, 研发, 人工智能, 领域, 人类, 辅助, 伟达, uber, 方案, 芯片, 学习, 事故, 驾驶员, 团队, 美国, 传统, 谷歌, 环境, 深度, 行业, 软件, 厂商, 识别, 创业, google, 行驶, 雷达, 苹果, 城市, 计算, 车载, 场景, 开发, 控制, 奥迪, 收购, 驾驶 辅助, 算法, 英特尔, 项目, 感知, 信息, 地图, 摄像头, 卡车, 机器, 驾驶 系统, 福特, 平台, 服务, 发布, 出行, 成本, 硬件, 设计, 交通, 深度 学习, 研究, 过程, 简单,
------------------------------------------------------------------------------------------------
簇群 21 该簇群所含文档占比为 0.0073%
簇群关键词:
物流, 快递, 京东, 顺丰, 京东 物流, 电商, 业务, 菜鸟, 行业, 成本, 服务, 企业, 零售, 申通, 亿元, 平台, 投资, 阿里, 模式, 配送, #NUMBER 亿元, 无人机, 收入, 控股, 仓储, 增速, 快运, #NUMBER 顺丰, 刘强, 增长, 德邦, 运营, 中心, 全球, 顺丰 控股, 无人, 城市, 网点, 直营, 融资, 合作, 业务量, 第三方, 仓库, 客户, 领域, 中原, 上市, 线下, 圆通, 竞争, 物流 行业, 丰巢, 通达, 布局, 包裹, 加盟, 亿美元, 便利店, 快递 企业, 规模, 市值, 订单, 优势, 自营, 供应链, 社区, 超过, 估值, 国内, 价格, 中通, 战略, 界面, 智能, 投入, 商品, #NUMBER 京东, 快递 行业, 司机,
------------------------------------------------------------------------------------------------
簇群 22 该簇群所含文档占比为 0.0475%
簇群关键词:
品牌, 消费者, 消费, 集团, 时尚, 增长, 营销, 渠道, 门店, 行业, 设计, 销售, 奢侈品, 美国, 全球, 零售, gucci, 媒体, 电商, 销售额, 奢侈, 年轻人, 平台, 商品, 价格, 品类, 合作, 需求, 生活, 咖啡, 企业, 奢侈 品牌, 传统, 去年, 超过, 模式, 星巴克, 城市, 明星, 社交, 亿美元, 购买, 设计师, 年轻, 体验, zara, 显示, nike, 欧元, 国内, 女性, 文化, 日本, 潮流, 收购, 创意, 同比, 业绩, adidas, 拥有, 成本, 店铺, 业务, 商业, #NUMBER 亿美元, 价值, 服务, #NUMBER 欧元, 发布, 增长 #NUMBER, 系列, 广告, 闪店, 客户, 高端, 顾客, 升级, 成功, 核心, 人群,
------------------------------------------------------------------------------------------------
簇群 23 该簇群所含文档占比为 0.0323%
簇群关键词:
腾讯, 亿元, #NUMBER 亿元, 增长, 投资, 游戏, 直播, 业务, 阿里, 收入, 互联网, 平台, 上市, 亿美元, 增长 #NUMBER, 企业, #NUMBER 亿美元, 虎牙, 人民币, 领域, 流量, 内容, 营收, 同比, 京东, 阿里巴巴, 搜狗, 显示, 资本, 行业, 音乐, 微信, 映客, 视频, 超过, 融资, 发布, 市值, 网易, 财报, 美国, 万达, 电商, 去年, 斗鱼, 合作, 科技, 同比 增长, 净利润, 百度, 支付, 马化腾, 广告, 美团, 巨头, 战略, 集团, 零售, 估值, 资金, 超过 #NUMBER, 服务, 数字, 股东, 竞争, 商业, 股权, 运营, 万元, 招股书, 股份, 业绩, 亿元 #NUMBER, #NUMBER 万元, 股价, 版权, 光线, 搜索, 娱乐, 模式,
------------------------------------------------------------------------------------------------
簇群 24 该簇群所含文档占比为 0.0149%
簇群关键词:
机器人, 人类, 机器, ai, 人工智能, 智能, 领域, 亚马逊, 科技, 软银, 孙正义, 学习, 研究, 教育, 服务, 必选, 谷歌, 研发, 动作, 功能, 自动化, 制造, 设备, 训练, 聊天, 团队, 信息, 美国, 日本, 行业, 投资, 设计, 亿美元, 企业, 自动, 收购, 视频, 新闻, 工厂, 动力, 波士顿, 开发, 家庭, 聊天 机器人, 拥有, 波士顿 动力, 编程, 扫地, 简单, 汽车, #NUMBER 亿美元, 全球, 视觉, 家用, 扫地 机器人, 语音, 机械, 现实, 联网, 理解, 超过, 索菲亚, 系统, 水下, woebot, 烹饪, 大学, 算法, 软体, 比赛, 工人, 软体 机器人, 环境, 人形, 识别, 国内, 价值, 人类 机器人, 过程, 员工,
------------------------------------------------------------------------------------------------
簇群 25 该簇群所含文档占比为 0.0177%
簇群关键词:
特斯拉, model, 马斯克, 汽车, 亿美元, #NUMBER 亿美元, 产能, 工厂, 建厂, 车型, 电动车, 驾驶, 美国, 交付, 电池, 美元, 充电, 新能源, #NUMBER 美元, 自动, 自动 驾驶, 电动, 企业, 售价, 上海, #NUMBER 特斯拉, 量产, 车主, 制造, #NUMBER model, 万美元, 发布, roadster, 产量, 股价, 成本, musk, 传统, 特斯拉 model, 车辆, elon, 融资, 超过, 订单, model model, elon musk, 特斯拉 中国, 卡车, 销售, 国内, 设计, 资金, 投资, 目标, 消息, 研发, 预计, 超级, 员工, 系统, 全球, 价格, 去年, 加速, 独资, 功能, 上市, 优势, 科技, 关税, 贾跃亭, 续航, model 产能, 提升, 销量, 特斯拉 #NUMBER, autopilot, 政策, 超过 #NUMBER, 国产,
------------------------------------------------------------------------------------------------
簇群 26 该簇群所含文档占比为 0.0172%
簇群关键词:
苹果, iphone, 库克, 手机, apple, ios, 发布, 苹果公司, 设计, 系统, 设备, 亿美元, 美国, #NUMBER 亿美元, 自动, 屏幕, 功能, ipad, 科技, 开发者, 乔布斯, 更新, ios #NUMBER, 驾驶, 软件, 汽车, 全球, 自动 驾驶, 增长, 项目, 电池, 去年, 服务, #NUMBER 苹果, 谷歌, 报道, 人工智能, 研发, wwdc, ar, 信息, 硬件, 支持, 领域, 市值, siri, 开发, 企业, 员工, 研究, 智能, 业务, 体验, 平台, 隐私, 销量, 显示, ai, 收购, 超过, 厂商, 微软, 团队, 消费者, 手表, 视频, 发布会, 印度, 官方, store, 供应链, 行业, 教育, 性能, 苹果 #NUMBER, 识别, homepod, 投资, 巨头, 此前,
------------------------------------------------------------------------------------------------
簇群 27 该簇群所含文档占比为 0.0131%
簇群关键词:
城市, 北京, 上海, 便利店, 经济, 生活, 交通, 服务, 专业, 航线, 美国, 消费, 收入, 大家, 人口, 文化, 互联网, 出行, 大学, 一线, 汽车, 品牌, 模式, 项目, 空间, 需求, 街道, 杭州, 政府, 政策, 智慧, 地铁, 企业, 成本, 二线, 智能, 万元, 餐饮, 小时, 增速, 超过, 二线 城市, 车牌, 规划, 广州, 道路, 学校, 三四, 资源, 江浙沪, 高铁, 管理, 增长, 补贴, 平均, 编剧, 系统, 小宝, 居民, 大城市, 铁路, 行业, 一线 城市, #NUMBER 万元, 年轻人, 公寓, 拥有, 车辆, 北京 文化, 毕业生, 门店, 平台, 价格, 媒体, 大脑, 一年, 数量, 青年, 国际, #NUMBER 北京,
------------------------------------------------------------------------------------------------
簇群 28 该簇群所含文档占比为 0.0402%
簇群关键词:
人工智能, 人类, 学习, 机器, 领域, ai, 智能, 研究, 机器人, 科技, 算法, 企业, 机器 学习, 行业, 创业, 互联网, 投资, 识别, 深度, alphago, 系统, 服务, 计算机, 信息, 美国, 项目, 团队, 大脑, 微软, 深度 学习, 谷歌, 理解, 平台, 计算, 大家, 模型, 百度, 语音, 人才, 科学家, 过程, 场景, 人工智能 领域, 方向, 时代, 需求, 自动, 训练, 机会, 简单, 研发, 拥有, 硬件, 价值, 分析, 驾驶, 商业, 业务, 内容, 全球, 基础, 核心, 视觉, 设计, 预测, 医疗, 成本, 游戏, 经济, 生活, 开发, 判断, 无人驾驶, 自动化, 客户, 合作, 融资, 腾讯, 功能, 环境,
------------------------------------------------------------------------------------------------
簇群 29 该簇群所含文档占比为 0.0397%
簇群关键词:
电影, 票房, 影片, 导演, 观众, 上映, 漫威, 作品, 故事, 英雄, 好莱坞, 姜文, 美国, 影院, 影业, 万达, 发行, 文化, 中国 电影, 制作, 影视, 国内, 豆瓣, 印度, 口碑, 行业, 拍摄, 时代, 粉丝, 超级, 评分, 演员, 投资, 创作, 项目, 爱情, 成本, 生活, ip, 内容, 角色, 超级 英雄, 剧本, 超过, 内地, 日本, 成功, 喜欢, 药神, 徐峥, 院线, 票房 #NUMBER, 大片, 大家, 现实, 公寓, 亿美元, 北京, 题材, 平台, 观影, 宇宙, 系列, 爱情 公寓, 类型, 娱乐, 全球, 漫画, 戛纳, 合作, 产业, 黑豹, 去年, 复联, 电影节, 宣传, 成绩, 人物, 宣发, 收入,
------------------------------------------------------------------------------------------------
簇群 30 该簇群所含文档占比为 0.0126%
簇群关键词:
ofo, 单车, 摩拜, 滴滴, 共享, 共享 单车, 阿里, 合并, 融资, 啸虎, 资本, 投资, 美团, 腾讯, 投资人, 股东, 戴威, 团队, 运营, 创始人, 收购, 马化腾, 胡玮炜, 行业, 摩拜 ofo, 出行, 企业, 亿美元, 竞争, 成本, 两家, 大家, 模式, 哈罗, 王兴, 王晓峰, 蚂蚁, 估值, 互联网, 哈罗 单车, 城市, 摩拜 单车, 黄车, 领域, 平台, #NUMBER 亿美元, 消息, 金服, 蚂蚁 金服, 服务, 此前, 业务, 超过, 价值, 自行车, 战略, 李斌, 亿美金, 智能, 创业, 媒体, 盈利, 滴滴 ofo, 创始, 微信, 内部, 接受, 显示, 押金, ceo, 资金, 科技, 永安, 去年, 背后, 员工, 创始 团队, 管理, 董事会, 亿元,
上面的聚类效果还是蛮不错的,起码了解互联网动态的小伙伴能通过每个簇群下的关键词一眼看出每个簇群说了啥。另外,通过“该簇群所含文档占比”可以得知每个簇群在整个语料库中的重要性程度。
7 聚类可视化
将上面的聚类效果进行可视化,首先需要将文档向量从40000维的空间降维到2维空间,这里使用TruncatedSVD。
labels=km.labels_.tolist()l = km.fit_predict(X)svd = TruncatedSVD(n_components=2).fit(X)datapoint = svd.transform(X)
import matplotlib.pyplot as plt%matplotlib inlineplt.figure(figsize=(32, 28))label1 = ['#FFFF00', '#008008', '#0000FF','#800080','#FFF5EE','#98FB98','#A0522D','#FF7F00','#FFC125','#FFFFFF','#FFFAFA','#FFF68F','#FFEFD5','#FFE4E1','#FFDEAD','#FFC1C1','#FFB90F','#FFA54F','#FF8C00','#C0FF3E','#FF6EB4','#FF4500','#FF3030','#8A2BE2','#87CEEB','#8470FF','#828282','#7EC0EE','#7CFC00','#7A8B8B','#79CDCD','#76EE00']color = [label1[i] for i in labels]plt.scatter(datapoint[:, 0], datapoint[:, 1], c=color)centroids = km.cluster_centers_centroidpoint = svd.transform(centroids)plt.scatter(centroidpoint[:, 0], centroidpoint[:, 1], marker='^', s=150, c='#000000')plt.show()
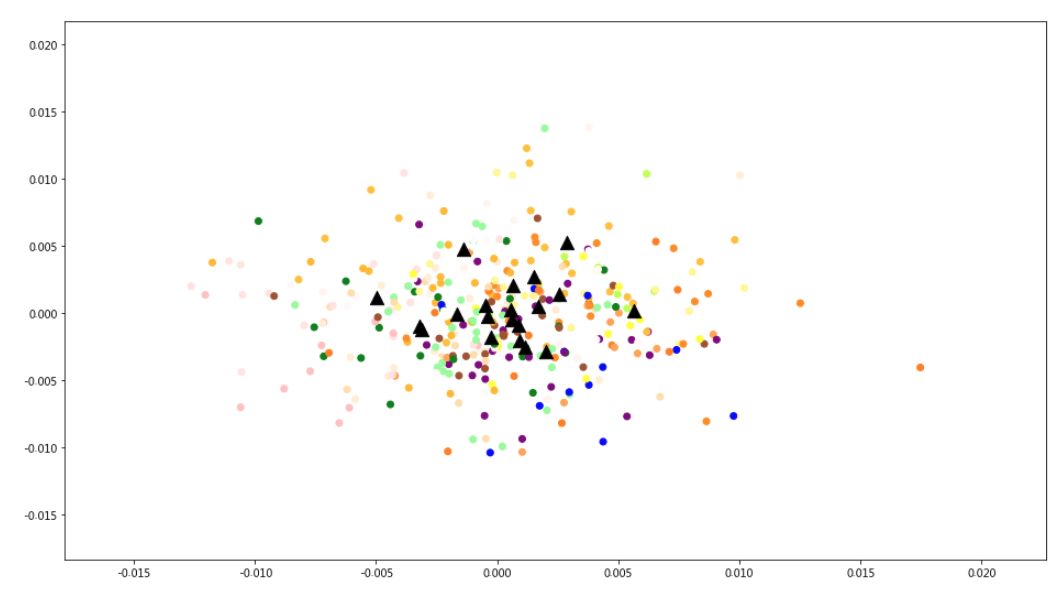
上图中的黑色三角是每个簇群的中心,不同的颜色代表不同的簇群。
可能是聚类效果不佳,亦或文档向量降维效果不佳,上面的图看起来比较杂乱,看起来没有比较集中的聚类。可能使用更好的聚类方法(DBSCAN)或者使用t-SNE对文档向量降维可以缓解这个问题。
结语
这里,笔者是基于文本的稀疏特征做的文本聚类,如果试试基于之前提到的word2vec ,用于提取词汇稠密向量(Dense Vector)来进行聚类,效果又会如何呢?感兴趣的小伙伴可以试试哦。
欢迎大家在下方评论出踊跃发言,谢谢各位的支持!
推荐阅读
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏