【论文推荐】最新六篇自动问答(QA)相关论文—复杂序列问答、注意力机制、长短时记忆、文本推理、多因素注意力、主动的问答智能体
【导读】专知内容组整理了最近六篇自动问答(Question Answering)相关文章,为大家进行介绍,欢迎查看!
1. Complex Sequential Question Answering: Towards Learning to Converse Over Linked Question Answer Pairs with a Knowledge Graph(复杂序列问答:基于知识图谱的问答对关联方法)
作者:Amrita Saha,Vardaan Pahuja,Mitesh M. Khapra,Karthik Sankaranarayanan,Sarath Chandar
摘要:While conversing with chatbots, humans typically tend to ask many questions, a significant portion of which can be answered by referring to large-scale knowledge graphs (KG). While Question Answering (QA) and dialog systems have been studied independently, there is a need to study them closely to evaluate such real-world scenarios faced by bots involving both these tasks. Towards this end, we introduce the task of Complex Sequential QA which combines the two tasks of (i) answering factual questions through complex inferencing over a realistic-sized KG of millions of entities, and (ii) learning to converse through a series of coherently linked QA pairs. Through a labor intensive semi-automatic process, involving in-house and crowdsourced workers, we created a dataset containing around 200K dialogs with a total of 1.6M turns. Further, unlike existing large scale QA datasets which contain simple questions that can be answered from a single tuple, the questions in our dialogs require a larger subgraph of the KG. Specifically, our dataset has questions which require logical, quantitative, and comparative reasoning as well as their combinations. This calls for models which can: (i) parse complex natural language questions, (ii) use conversation context to resolve coreferences and ellipsis in utterances, (iii) ask for clarifications for ambiguous queries, and finally (iv) retrieve relevant subgraphs of the KG to answer such questions. However, our experiments with a combination of state of the art dialog and QA models show that they clearly do not achieve the above objectives and are inadequate for dealing with such complex real world settings. We believe that this new dataset coupled with the limitations of existing models as reported in this paper should encourage further research in Complex Sequential QA.
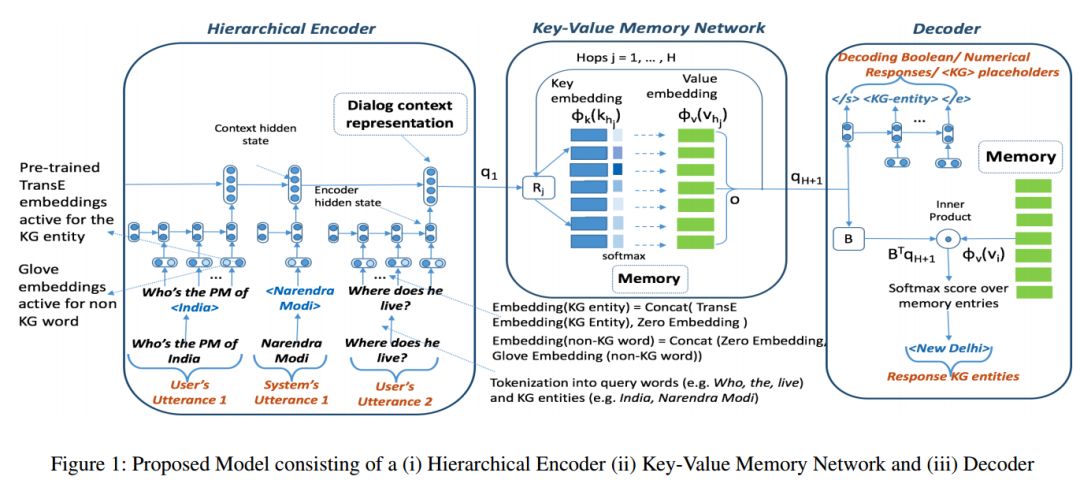
期刊:arXiv, 2018年1月31日
网址:
http://www.zhuanzhi.ai/document/ea56248d486fbd91166c3f0f3f13cc50
2. An Attention-Based Word-Level Interaction Model: Relation Detection for Knowledge Base Question Answering(基于注意力机制的字级交互模型:基于关系检测的知识库问答)
作者:Hongzhi Zhang,Guandong Xu,Xiao Liang,Tinglei Huang,Kun fu
摘要:Relation detection plays a crucial role in Knowledge Base Question Answering (KBQA) because of the high variance of relation expression in the question. Traditional deep learning methods follow an encoding-comparing paradigm, where the question and the candidate relation are represented as vectors to compare their semantic similarity. Max- or average- pooling operation, which compresses the sequence of words into fixed-dimensional vectors, becomes the bottleneck of information. In this paper, we propose to learn attention-based word-level interactions between questions and relations to alleviate the bottleneck issue. Similar to the traditional models, the question and relation are firstly represented as sequences of vectors. Then, instead of merging the sequence into a single vector with pooling operation, soft alignments between words from the question and the relation are learned. The aligned words are subsequently compared with the convolutional neural network (CNN) and the comparison results are merged finally. Through performing the comparison on low-level representations, the attention-based word-level interaction model (ABWIM) relieves the information loss issue caused by merging the sequence into a fixed-dimensional vector before the comparison. The experimental results of relation detection on both SimpleQuestions and WebQuestions datasets show that ABWIM achieves state-of-the-art accuracy, demonstrating its effectiveness.
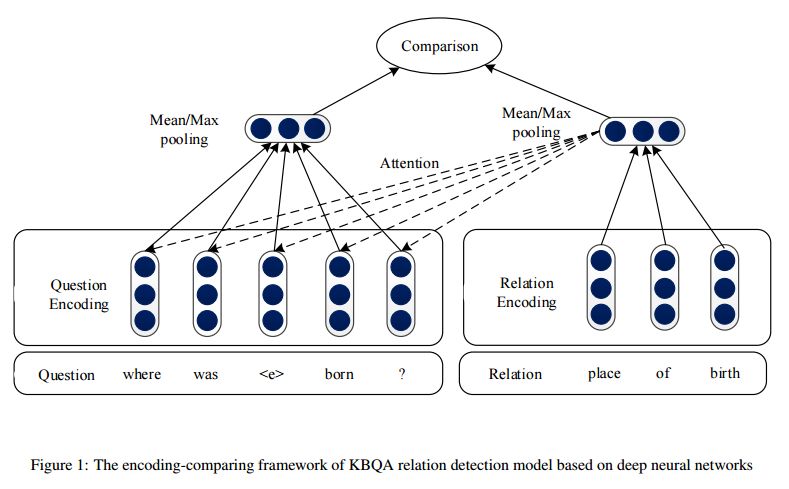
期刊:arXiv, 2018年1月30日
网址:
http://www.zhuanzhi.ai/document/cb89b101acd78d217dccf1891c81e464
3. Learning Intrinsic Sparse Structures within Long Short-Term Memory(在长短时记忆中学习固有的稀疏结构)
作者:Wei Wen,Yuxiong He,Samyam Rajbhandari,Minjia Zhang,Wenhan Wang,Fang Liu,Bin Hu,Yiran Chen,Hai Li
摘要:Model compression is significant for the wide adoption of Recurrent Neural Networks (RNNs) in both user devices possessing limited resources and business clusters requiring quick responses to large-scale service requests. This work aims to learn structurally-sparse Long Short-Term Memory (LSTM) by reducing the sizes of basic structures within LSTM units, including input updates, gates, hidden states, cell states and outputs. Independently reducing the sizes of basic structures can result in inconsistent dimensions among them, and consequently, end up with invalid LSTM units. To overcome the problem, we propose Intrinsic Sparse Structures (ISS) in LSTMs. Removing a component of ISS will simultaneously decrease the sizes of all basic structures by one and thereby always maintain the dimension consistency. By learning ISS within LSTM units, the obtained LSTMs remain regular while having much smaller basic structures. Based on group Lasso regularization, our method achieves 10.59x speedup without losing any perplexity of a language modeling of Penn TreeBank dataset. It is also successfully evaluated through a compact model with only 2.69M weights for machine Question Answering of SQuAD dataset. Our approach is successfully extended to non- LSTM RNNs, like Recurrent Highway Networks (RHNs). Our source code is publicly available at https://github.com/wenwei202/iss-rnns
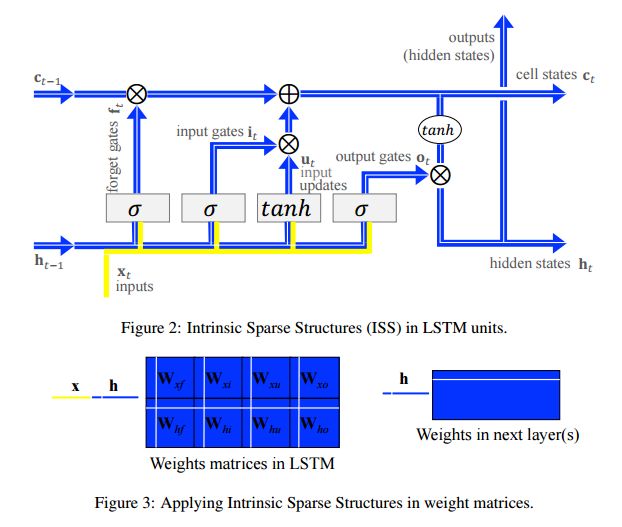
期刊:arXiv, 2018年1月30日
网址:
http://www.zhuanzhi.ai/document/dc380a5c607f335c00644002957fc24f
4. Finding ReMO (Related Memory Object): A Simple Neural Architecture for Text based Reasoning(寻找ReMO(相关的内存对象):基于文本推理的简单神经架构)
作者:Jihyung Moon,Hyochang Yang,Sungzoon Cho
摘要:To solve the text-based question and answering task that requires relational reasoning, it is necessary to memorize a large amount of information and find out the question relevant information from the memory. Most approaches were based on external memory and four components proposed by Memory Network. The distinctive component among them was the way of finding the necessary information and it contributes to the performance. Recently, a simple but powerful neural network module for reasoning called Relation Network (RN) has been introduced. We analyzed RN from the view of Memory Network, and realized that its MLP component is able to reveal the complicate relation between question and object pair. Motivated from it, we introduce which uses MLP to find out relevant information on Memory Network architecture. It shows new state-of-the-art results in jointly trained bAbI-10k story-based question answering tasks and bAbI dialog-based question answering tasks.
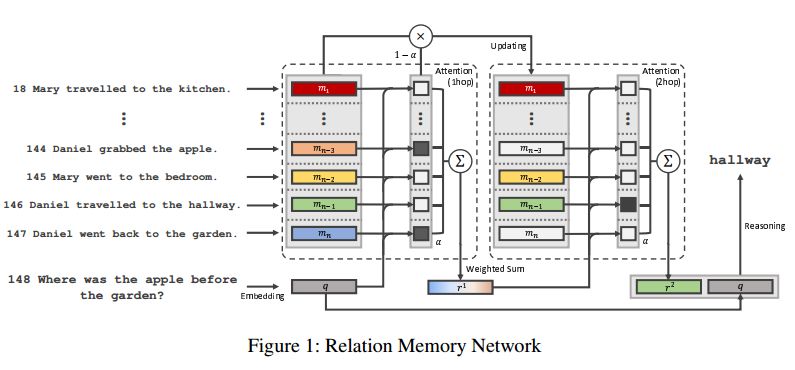
期刊:arXiv, 2018年1月26日
网址:
http://www.zhuanzhi.ai/document/d48340900a6cadb222eeb7b739a94a7c
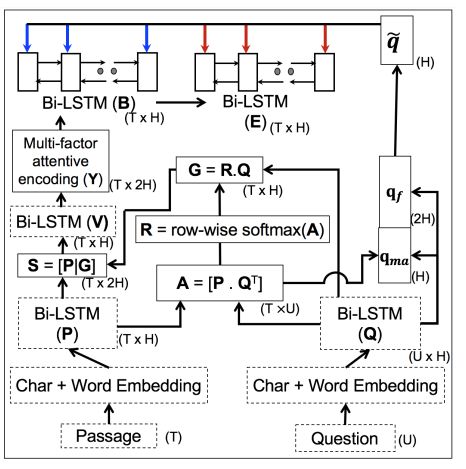
5. A Question-Focused Multi-Factor Attention Network for Question Answering(以问题为中心的多因素注意力网络的自动问答方法)
作者:Souvik Kundu,Hwee Tou Ng
摘要:Neural network models recently proposed for question answering (QA) primarily focus on capturing the passage-question relation. However, they have minimal capability to link relevant facts distributed across multiple sentences which is crucial in achieving deeper understanding, such as performing multi-sentence reasoning, co-reference resolution, etc. They also do not explicitly focus on the question and answer type which often plays a critical role in QA. In this paper, we propose a novel end-to-end question-focused multi-factor attention network for answer extraction. Multi-factor attentive encoding using tensor-based transformation aggregates meaningful facts even when they are located in multiple sentences. To implicitly infer the answer type, we also propose a max-attentional question aggregation mechanism to encode a question vector based on the important words in a question. During prediction, we incorporate sequence-level encoding of the first wh-word and its immediately following word as an additional source of question type information. Our proposed model achieves significant improvements over the best prior state-of-the-art results on three large-scale challenging QA datasets, namely NewsQA, TriviaQA, and SearchQA.
期刊:arXiv, 2018年1月25日
网址:
http://www.zhuanzhi.ai/document/9cc44f63e5206ff01765b56a155c24be
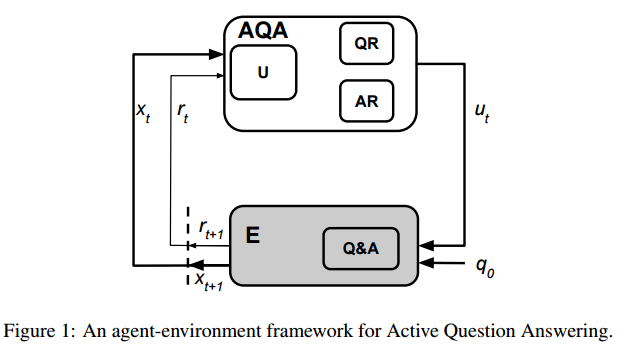
6. Analyzing Language Learned by an Active Question Answering Agent(一个主动的问答智能体分析语言方法)
作者:Christian Buck,Jannis Bulian,Massimiliano Ciaramita,Wojciech Gajewski,Andrea Gesmundo,Neil Houlsby,Wei Wang
摘要:Dense reconstructions often contain errors that prior work has so far minimised using high quality sensors and regularising the output. Nevertheless, errors still persist. This paper proposes a machine learning technique to identify errors in three dimensional (3D) meshes. Beyond simply identifying errors, our method quantifies both the magnitude and the direction of depth estimate errors when viewing the scene. This enables us to improve the reconstruction accuracy. We train a suitably deep network architecture with two 3D meshes: a high-quality laser reconstruction, and a lower quality stereo image reconstruction. The network predicts the amount of error in the lower quality reconstruction with respect to the high-quality one, having only view the former through its input. We evaluate our approach by correcting two-dimensional (2D) inverse-depth images extracted from the 3D model, and show that our method improves the quality of these depth reconstructions by up to a relative 10% RMSE.
期刊:arXiv, 2018年1月23日
网址:
http://www.zhuanzhi.ai/document/a5e9fd8ff62a7e93e2aa6136725a9ec9
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!





