
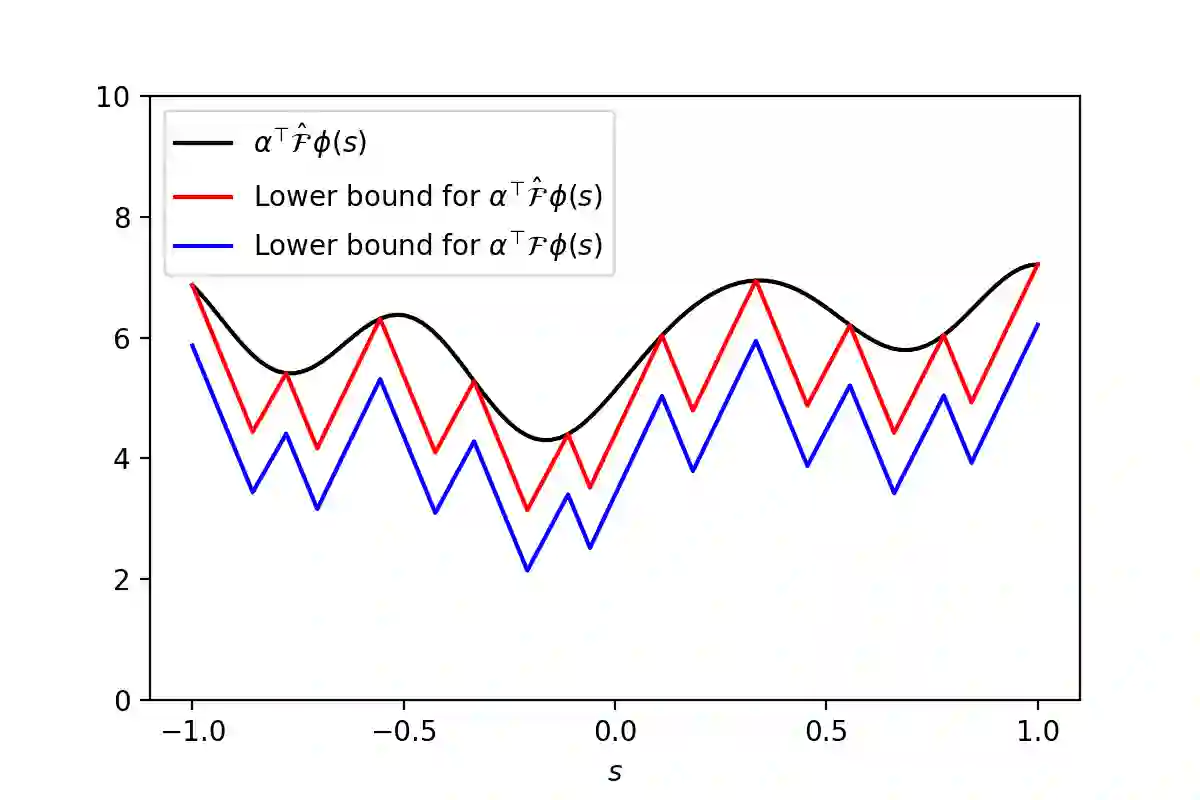
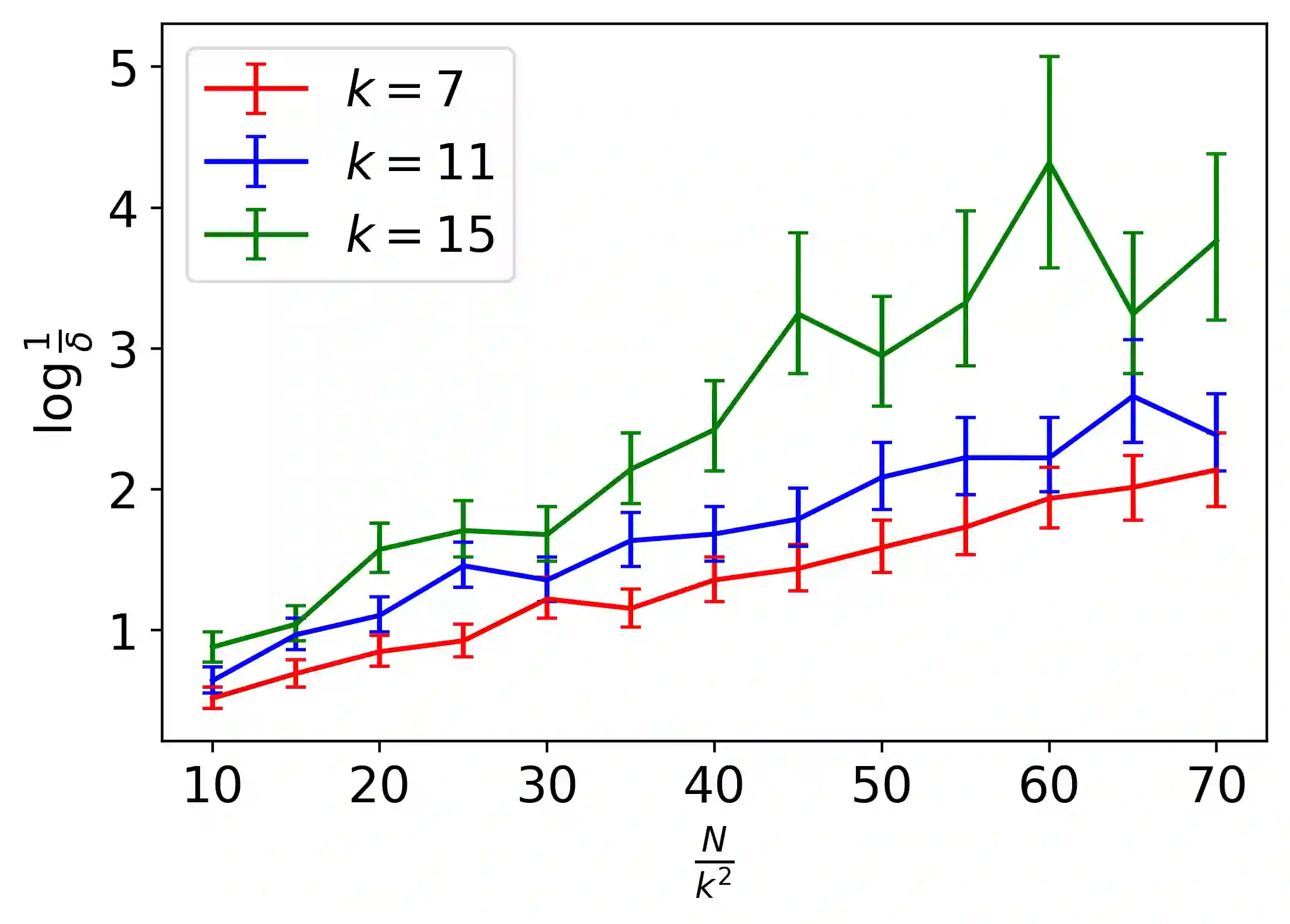
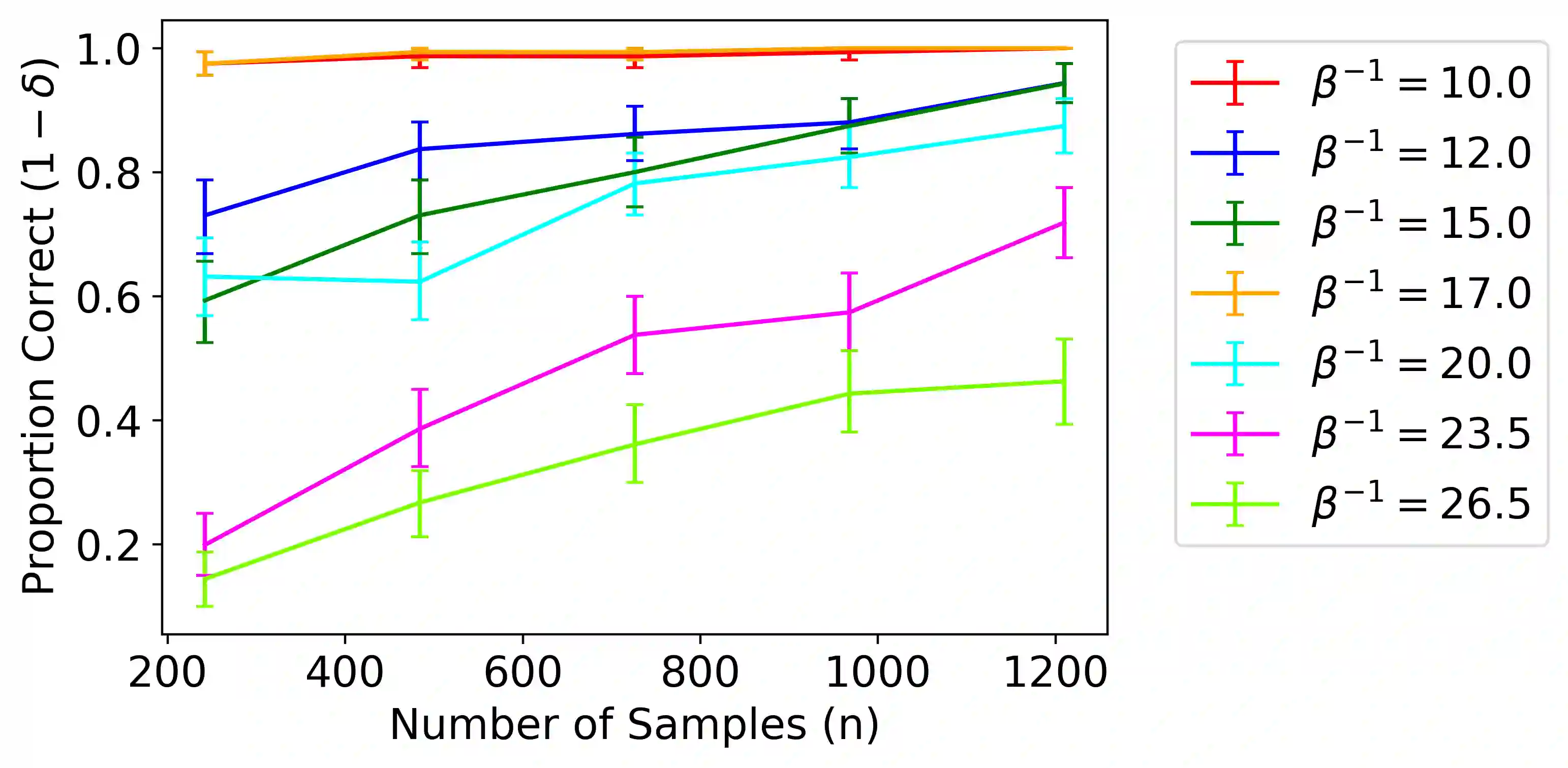
Inverse Reinforcement Learning (IRL) is the problem of finding a reward function which describes observed/known expert behavior. The IRL setting is remarkably useful for automated control, in situations where the reward function is difficult to specify manually or as a means to extract agent preference. In this work, we provide a new IRL algorithm for the continuous state space setting with unknown transition dynamics by modeling the system using a basis of orthonormal functions. Moreover, we provide a proof of correctness and formal guarantees on the sample and time complexity of our algorithm. Finally, we present synthetic experiments to corroborate our theoretical guarantees.
翻译:反强化学习(IRL)是找到一种能描述观察/已知专家行为的奖赏功能的问题。在奖赏功能难以手工指定或作为提取代理人偏好的手段的情况下,IRL设置对于自动控制非常有用。在这项工作中,我们为连续的状态空间设置提供了一种新的IRL算法,这种状态空间设置具有未知的过渡动态,通过以异常功能为基础对系统进行建模。此外,我们还为我们的算法样本和时间复杂性提供了正确性和正式保证的证明。最后,我们提出了合成实验,以证实我们的理论保证。
相关内容

Source: Apple - iOS 8


