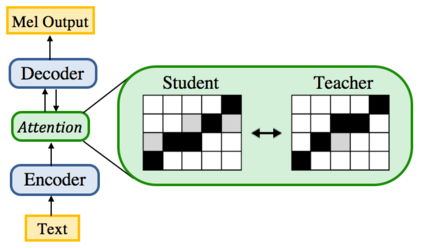
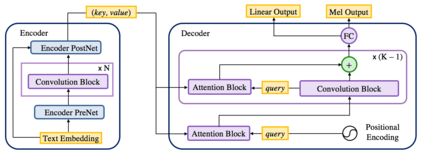
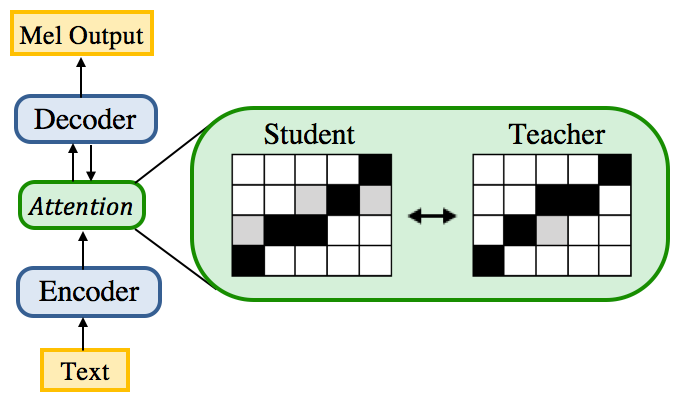
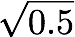In this work, we propose ParaNet, a non-autoregressive seq2seq model that converts text to spectrogram. It is fully convolutional and brings 46.7 times speed-up over the lightweight Deep Voice 3 at synthesis, while obtaining reasonably good speech quality. ParaNet also produces stable alignment between text and speech on the challenging test sentences by iteratively improving the attention in a layer-by-layer manner. Furthermore, we build the parallel text-to-speech system and test various parallel neural vocoders, which can synthesize speech from text through a single feed-forward pass. We also explore a novel VAE-based approach to train the inverse autoregressive flow (IAF) based parallel vocoder from scratch, which avoids the need for distillation from a separately trained WaveNet as previous work.
翻译:在这项工作中,我们提出ParaNet,这是一个将文本转换成光谱的不反向后继2seq模型。它具有全面进化性,在合成时对轻量深音3号进行46.7倍的加速,同时取得相当好的语音质量。ParaNet还以逐层方式反复提高注意,从而在具有挑战性的测试句上实现文字和语言之间的稳定一致。此外,我们建造了平行的文本到语音系统,并测试了各种平行的神经立体器,它可以通过一个单一的进料前进通道将文字的语音合成。我们还探索了一种基于VAE的新型方法,从零开始对基于平行电动电动的反向回移流(IAF)进行培训,从而避免了像以前的工作那样从一个经过单独训练的波网中蒸馏。