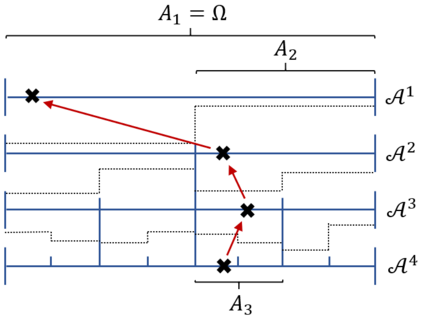
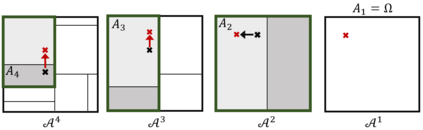
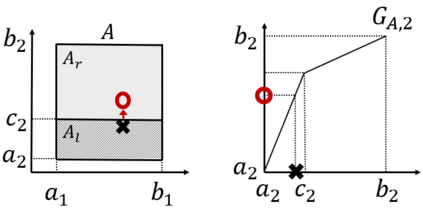
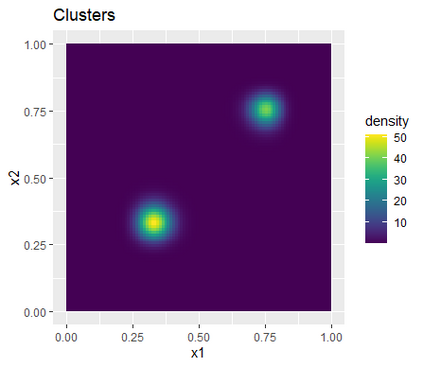
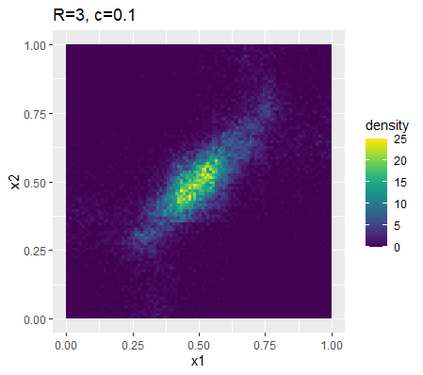
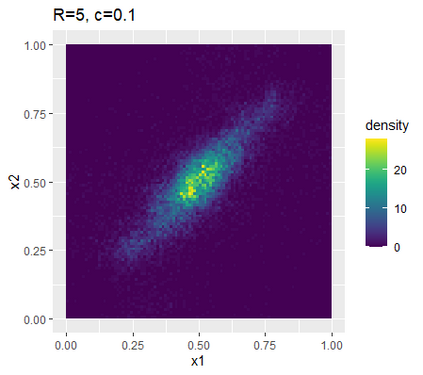
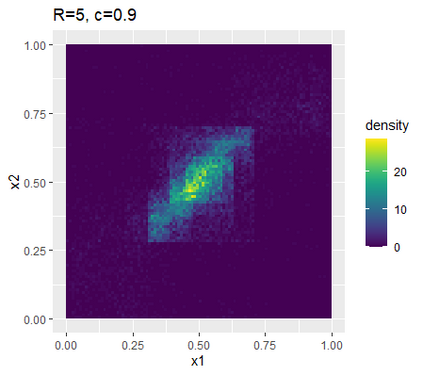
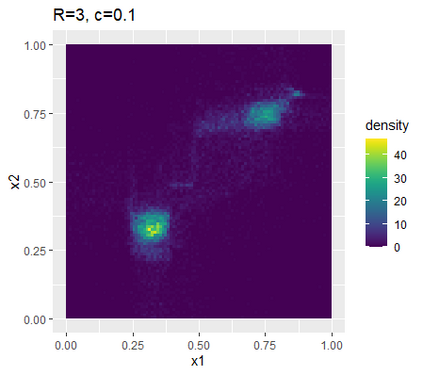
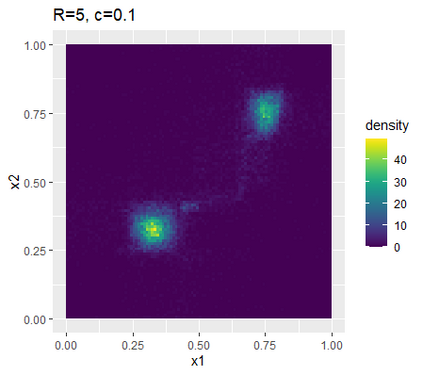
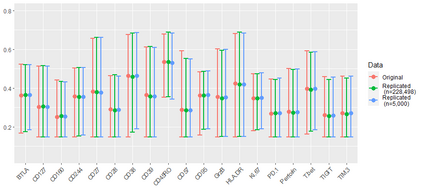
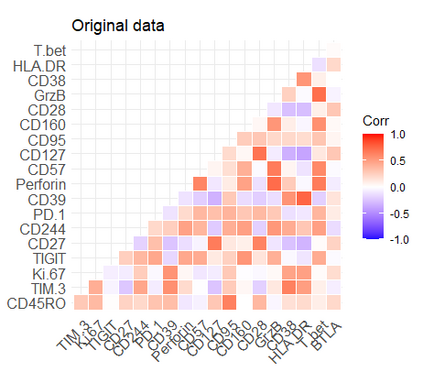
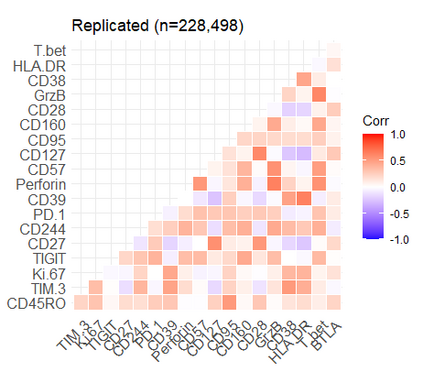
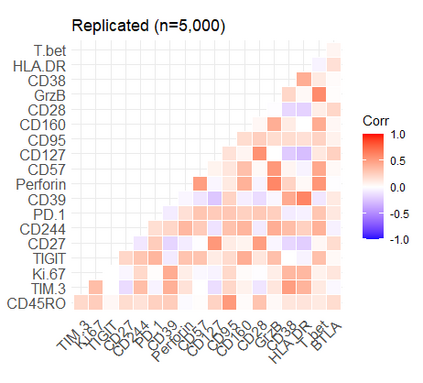
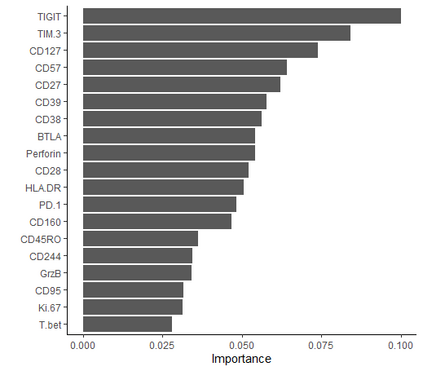
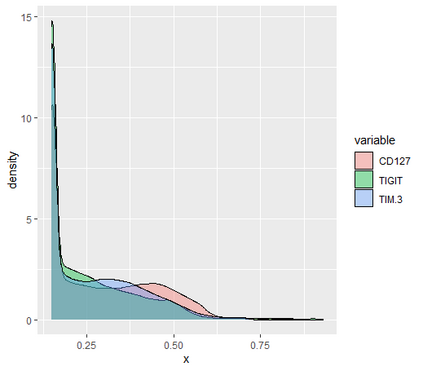
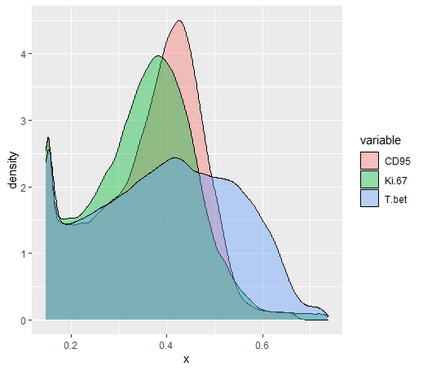
Learning probability measures based on an i.i.d. sample is a fundamental inference task, but is challenging when the sample space is high-dimensional. Inspired by the success of tree boosting in high-dimensional classification and regression, we propose a tree boosting method for learning high-dimensional probability distributions. We formulate concepts of "addition'' and "residuals'' on probability distributions in terms of compositions of a new, more general notion of multivariate cumulative distribution functions (CDFs) than classical CDFs. This then gives rise to a simple boosting algorithm based on forward-stagewise (FS) fitting of an additive ensemble of measures. The output of the FS algorithm allows analytic computation of the probability density function for the fitted distribution. It also provides an exact simulator for drawing independent Monte Carlo samples from the fitted measure. Typical considerations in applying boosting -- namely choosing the number of trees, setting the appropriate level of shrinkage/regularization in the weak learner, and the evaluation of variable importance -- can be accomplished in an analogous fashion to traditional boosting in supervised learning. Numerical experiments confirm that boosting can substantially improve the fit to multivariate distributions compared to the state-of-the-art single-tree learner and is computationally efficient. We illustrate through an application to a data set from mass cytometry how the simulator can be used to investigate various aspects of the underlying distribution.
翻译:基于 i. i. d. 抽样 的学习概率度量是一个基本的推论任务, 但当样本空间是高维时则具有挑战性。 树在高维分类和回归过程中的树增殖成功, 我们提议了一种树增殖方法, 用于学习高维概率分布。 我们设计了“ 添加” 和“ 重复” 的概念, 其概率分布是建立在比古典 CDFs 的多变累积分布函数( CDFs) 的新、 更一般的概念的概率构成上。 这在样本空间是高维度的时, 具有挑战性。 由于FS 算法的输出使得能够对安装的分布概率函数进行分析性计算。 我们还为从安装的计量中提取独立的 Monte Carlo 样本提供了精确的模拟。 应用提振的典型考虑 -- 即选择树木数量, 确定弱智者的适当收缩/ 和变式重要性的评估 -- 可以用一个类似的方式完成, 与传统的递增分配和测量的多维度矩阵的计算方法, 改进了我们用来测量的多维度的计算方法, 。